多进程与线程的优缺点及应用场景
多进程优点
①编程相对容易;通常不需要考虑锁和同步资源的问题。
②更强的容错性:比起多线程的一个好处是一个进程崩溃了不会影响其他进程。
③有内核保证的隔离:数据和错误隔离。 对于使用如C/C++这些语言编写的本地代码,错误隔离是非常有用的:采用多进程架构的程序一般可以做到一定程度的自恢复;(master守护进程监控所有worker进程,发现进程挂掉后将其重启)。
多线程的优点:
①创建速度快,方便高效的数据共享
共享数据:多线程间可以共享同一虚拟地址空间;多进程间的数据共享就需要用到共享内存、信号量等IPC技术。
②较轻的上下文切换开销 - 不用切换地址空间,不用更改寄存器,不用刷新TLB。
③提供非均质的服务。如果全都是计算任务,但每个任务的耗时不都为1s,而是1ms-1s之间波动;这样,多线程相比多进程的优势就体现出来,它能有效降低“简单任务被复杂任务压住”的概率。
应用场景
多进程应用场景
1.nginx主流的工作模式是多进程模式(也支持多线程模型)
2.几乎所有的web server服务器服务都有多进程的,至少有一个守护进程配合一个worker进程,例如apached,httpd等等以d结尾的进程包括init.d本身就是0级总进程,所有你认知的进程都是它的子进程;
3.chrome浏览器也是多进程方式。 (原因:①可能存在一些网页不符合编程规范,容易崩溃,采用多进程一个网页崩溃不会影响其他网页;而采用多线程会。②网页之间互相隔离,保证安全,不必担心某个网页中的恶意代码会取得存放在其他网页中的敏感信息。)
4.redis也可以归类到“多进程单线程”模型(平时工作是单个进程,涉及到耗时操作如持久化或aof重写时会用到多个进程)
多线程应用场景
线程间有数据共享,并且数据是需要修改的(不同任务间需要大量共享数据或频繁通信时)。
提供非均质的服务(有优先级任务处理)事件响应有优先级。
单任务并行计算,在非CPU Bound的场景下提高响应速度,降低时延。
与人有IO交互的应用,良好的用户体验(键盘鼠标的输入,立刻响应)
线程安全与线程同步
线程安全就是多线程访问时,采用了加锁机制,当一个线程访问该类的某个数据时,进行保护,其他线程不能进行访问直到该线程读取完,其他线程才可使用。不会出现数据不一致或者数据污染。
线程不安全就是不提供数据访问保护,有可能出现多个线程先后更改数据造成所得到的数据是脏数据
1. 概念
如果你的代码所在的进程中有多个线程在同时运行,而这些线程可能会同时运行这段代码。如果每次运行结果和单线程运行的结果是一样的,而且其他的变量的值也和预期的是一样的,就是线程安全的。
或者说,一个类或者程序所提供的接口对于线程来说是原子操作或者多个线程之间的切换不会导致该接口的执行结果存在二义性,也就是说我们不用考虑同步的问题。
线程安全问题都是由全局变量及静态变量引起的。(这句还未考证,但对全局变量和静态变量操作在多线程模型中会引发线程不安全)
若每个线程中对全局变量、静态变量只有读操作,而无写操作,一般来说,这个全局变量是线程安全的;若有多个线程同时执行写操作,一般都需要考虑线程同步,否则的话就可能影响线程安全。
2. 安全性
比如一个 ArrayList 类,在添加一个元素的时候,它可能会有两步来完成:1. 在 Items[Size] 的位置存放此元素;2. 增大 Size 的值。
在单线程运行的情况下,如果 Size = 0,添加一个元素后,此元素在位置 0,而且 Size=1;
而如果是在多线程情况下,比如有两个线程,线程 A 先将元素存放在位置 0。但是此时 CPU 调度线程A暂停,线程 B 得到运行的机会。线程B也向此 ArrayList 添加元素,因为此时 Size 仍然等于 0 (注意哦,我们假设的是添加一个元素是要两个步骤哦,而线程A仅仅完成了步骤1),所以线程B也将元素存放在位置0。然后线程A和线程B都继续运行,都增加 Size 的值。
那好,我们来看看 ArrayList 的情况,元素实际上只有一个,存放在位置 0,而 Size 却等于 2。这就是“线程不安全”了。
3. 线程同步
3.1 Synchronized(同步)
public class TraditionalThreadSynchronized {
public static void main(String[] args) {
final Outputter outputter = new Outputter();
// 运行两个线程分别输出名字zhangsan和lisi
new Thread() {
public void run() {
outputter.output("zhangsan");
}
}.start();
new Thread() {
public void run() {
outputter.output("lisi");
}
}.start();
}
}
class Outputter {
public void output(String name) {
// TODO 为了保证对name的输出不是一个原子操作,这里逐个输出name的每个字符
for(int i = 0; i < name.length(); i++) {
System.out.print(name.charAt(i));
// Thread.sleep(10);
}
}
}
运行结果:zhlainsigsan
显然输出的字符串被打乱了,我们期望的输出结果是zhangsanlisi,这就是线程同步问题,我们希望output方法被一个线程完整的执行完之后再切换到下一个线程,Java中使用synchronized保证一段代码在多线程执行时是互斥的,有两种用法:
方法 1: 使用synchronized将需要互斥的代码包含起来,并上一把锁。
{
synchronized (this) {
for(int i = 0; i < name.length(); i++) {
System.out.print(name.charAt(i));
}
}
}
这把锁必须是需要互斥的多个线程间的共享对象,像下面的代码是没有意义的。
{
Object lock = new Object();
synchronized (lock) {
for(int i = 0; i < name.length(); i++) {
System.out.print(name.charAt(i));
}
}
}
方法2:将synchronized加在需要互斥的方法上。
public synchronized void output(String name) {
// TODO 线程输出方法
for(int i = 0; i < name.length(); i++) {
System.out.print(name.charAt(i));
}
}
这种方式就相当于用this锁住整个方法内的代码块,如果用synchronized加在静态方法上,就相当于用××××.class锁住整个方法内的代码块。使用synchronized在某些情况下会造成死锁,死锁问题以后会说明。使用synchronized修饰的方法或者代码块可以看成是一个 原子操作。
每个锁对象(JLS(java语言规范)中叫monitor)都有两个队列,一个是就绪队列,一个是阻塞队列,就绪队列存储了将要获得锁的线程,阻塞队列存储了被阻塞的线程,当一个线程被唤醒(notify)后,才会进入到就绪队列,等待CPU的调度,反之,当一个线程被wait后,就会进入阻塞队列,等待下一次被唤醒,这个涉及到线程间的通信。看我们的例子,当第一个线程执行输出方法时,获得同步锁,执行输出方法,恰好此时第二个线程也要执行输出方法,但发现同步锁没有被释放,第二个线程就会进入就绪队列,等待锁被释放。一个线程执行互斥代码过程如下:
1. 获得同步锁;
2. 清空工作内存;
3. 从主内存拷贝对象副本到工作内存;
4. 执行代码(计算或者输出等);
5. 刷新主内存数据;
6. 释放同步锁。
所以,synchronized既保证了多线程的并发有序性,又保证了多线程的内存可见性。
信号量的实现和应用
信号量的代码实现
1,sem_open()
原型:sem_t * sem_open(const char *name, unsigned int value)
功能:创建一个信号量,或打开一个已经存在的信号量
参数:
name,信号量的名字。不同的进程可以通过同样的name而共享同一个信号量。如果该信号量不存在,就创建新的名为name的信号量;如果存在,就打开已经存在的名为name的信号量。
value,信号量的初值,仅当新建信号量时,此参数才有效,其余情况下它被忽略。
返回值。当成功时,返回值是该信号量的唯一标识(比如,在内核的地址、ID等)。如失败,返回值是NULL。
由于要做成系统调用,所以会穿插讲解系统调用的相关知识。
首先,在linux-0.11/kernel目录下面,新建实现信号量函数的源代码文件sem.c。同时,在linux-0.11/include/linux目录下新建sem.h,定义信号量数据结构。
linux-0.11/include/linux/sem.h
#ifndef _SEM_H
#define _SEM_H
#include <linux/sched.h>
#define SEMTABLE_LEN 20
#define SEM_NAME_LEN 20
typedef struct semaphore{
char name[SEM_NAME_LEN];
int value;
struct task_struct *queue;
} sem_t;
extern sem_t semtable[SEMTABLE_LEN];
#endif
由于sem_open的第一个参数name,传入的是应用程序所在地址空间的逻辑地址,在内核中如果直接访问这个地址,访问到的是内核空间中的数据,不会是用户空间。所以要用到get_fs_byte()函数获取用户空间的数据。get_fs_byte()函数的功能是获得一个字节的用户空间中的数据。同样,sem_unlink()函数的参数name也要进行相同的处理。
2,sem_unlink()
原型:int sem_unlink(const char *name)
功能:删除名为name的信号量。
返回值:返回0表示成功,返回-1表示失败
3,sem_wait()
原型:int sem_wait(sem_t *sem)
功能:信号量的P原子操作(检查信号量是不是为负值,如果是,则停下来睡眠等待,如果不是,则向下执行)。
返回值:返回0表示成功,返回-1表示失败。
4,sem_post()
原型:int sem_post(sem_t *sem)
功能:信号量的V原子操作(检查信号量的值是不是为0,如果是,表示有进程在睡眠等待,则唤醒队首进程,如果不是,向下执行)。
返回值:返回0表示成功,返回-1表示失败。
关于sem_wait()和sem_post()
我们可以利用linux 0.11提供的函数sleep_on()实现进程的睡眠,用wake_up实现进程的唤醒。
但是,sleep_on比较难以理解。我们先看下sleep_on源码。
void sleep_on(struct task_struct **p)
{
struct task_struct *tmp;
if (!p)
return;
if (current == &(init_task.task))
panic("task[0] trying to sleep");
tmp = *p;
*p = current;
current->state = TASK_UNINTERRUPTIBLE;
schedule();
if (tmp)
tmp->state=0;
}
还拿生产者和消费者的例子来说,依然是一个生产者和N个消费者,目前缓冲区为空,没有数可取。
1,消费者C1请求取数,调用sleep_on(&sem->queue)。此时,tmp指向NULL,p指向C1,调用schedule(),让出CPU的使用权。此时,信号量sem处等待队列的情况如下:
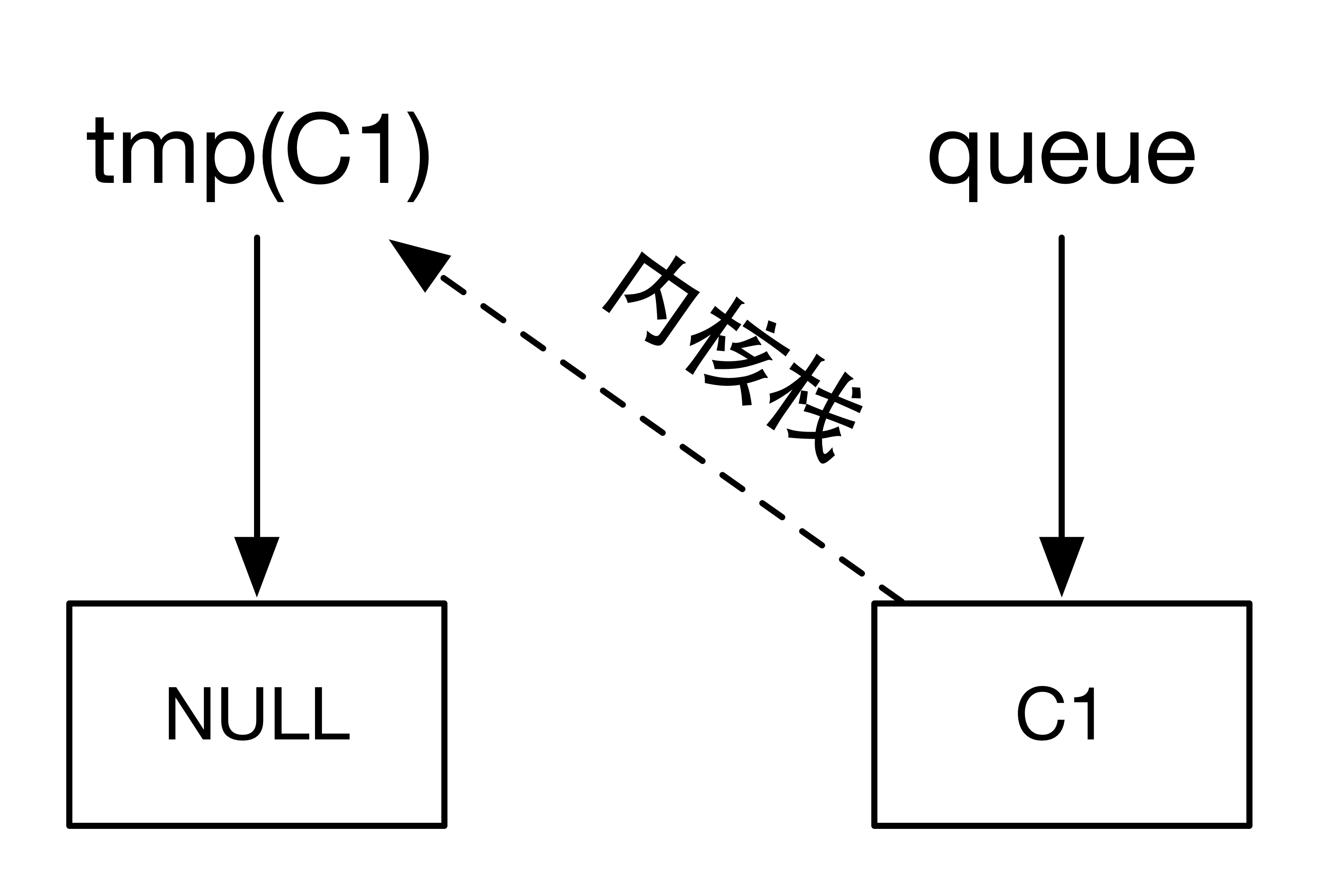
由于tmp是进程C1调用sleep_on()函数时申请的局部变量,所以会保存在C1运行到sleep_on函数中是C1的内核栈中,只要进程C1还没有从sleep_on()函数退出,tmp就会一直保存在C1的内核栈中。而进程C1是在sleep_on()中调用schedule()切出去的,所以在C1睡眠期间,tmp自然会保存在C1的内核栈中。这一点对于理解sleep_on上如何形成隐式的等待队列很重要。
2,消费者C2请求取数,调用sleep_on(&sem->queue)。此时,信号量sem出的等待队列如下:
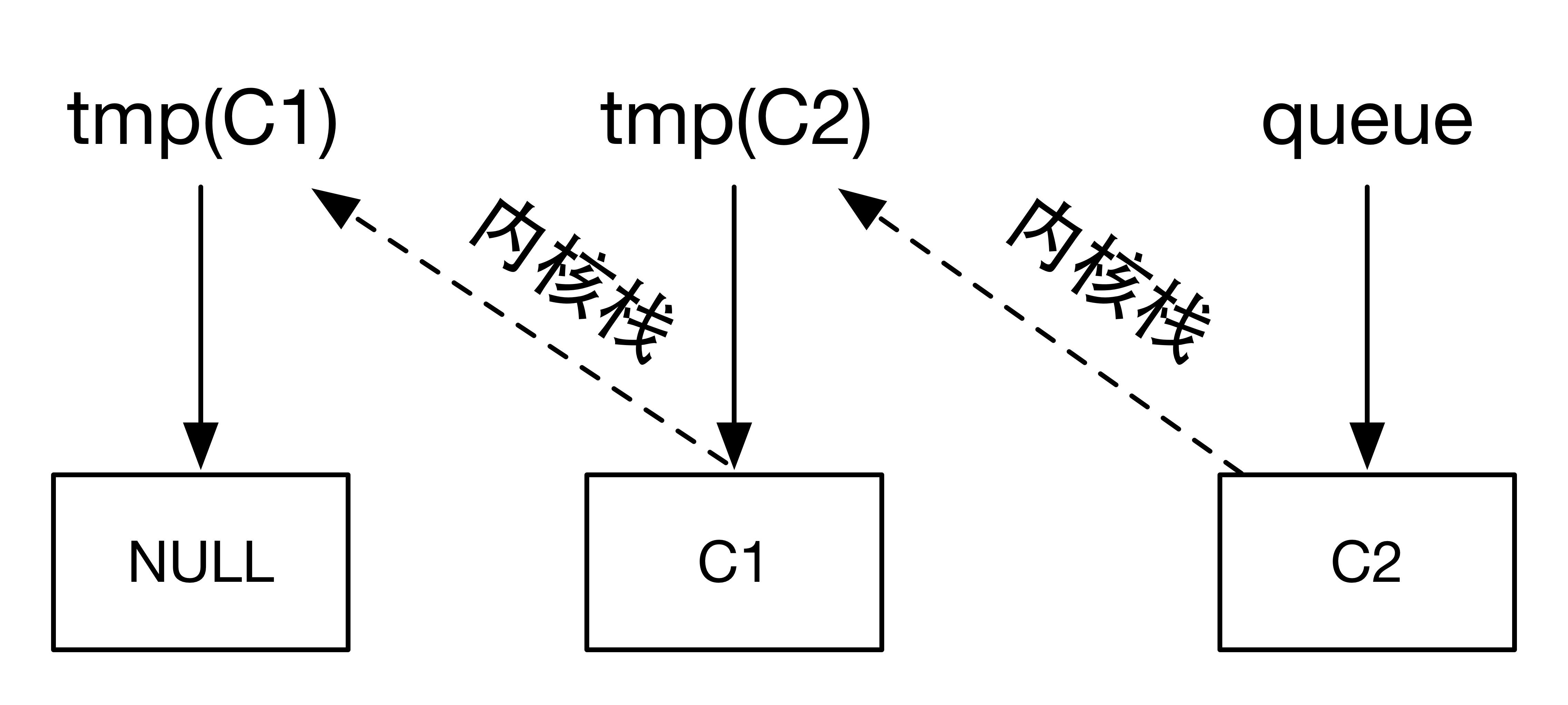
从这里就可以看到隐式的等待队列已经形成了。由于进程C2也会由于调用schedule()函数在sleep_on函数中睡眠,所以进程C2内核栈上的tmp便指向之前的等待队列的队首,也就是C1,通过C2的内核栈便可以找到睡眠的进程C1。这样就可以找到在信号量sem处睡眠的所有进程。
3,我们看下唤醒函数wake_up()
void wake_up(struct task_struct **p)
{
if (p && *p) {
(**p).state=0;
*p=NULL;
}
}
从中我们可以看到唤醒函数wake_up负责唤醒的是等待队列队首的进程。
当队首进程C2被唤醒时,从schedule函数退出,执行语句:
if (tmp)
tmp->state=0;
会将内核栈上由tmp指向的进程C1唤醒,如果进程C1的tmp还指向其他睡眠的进程,当C1被调度执行时,会将其tmp指向的进程唤醒,这样只要执行一次wake_up操作,就可以依次将所有等待在信号量sem处的睡眠进程唤醒。
sem_wait()和sem_post()函数的代码实现
由于我们要调用sleep_on实现进程的睡眠,调用wake_up实现进程的唤醒,上面已经讲清楚了sleep_on和wake_up的工作机制,接下来,便可以具体实现sem_wait和sem_post函数了。
1,sem_wait的实现
考虑到sleep_on会形成一个隐式的等待队列,而wake_up只要唤醒了等待队列的头节点,就可以依靠sleep_on内部的判断语句,实现依次唤醒全部的等待进程。所以,sem_wait的代码实现,必须考虑到这个情况。参考linux0.11内部的代码,对于进程是否需要等待的判断,不能用简单的if语句,而应该用while语句,假设现在sem=-1,生产者往缓冲区写入一个数,sem=0<=0,此时应该将等待队列队首的进程唤醒。当被唤醒的队首进程再次调度执行,从sleep_on函数退出,不会再执行if判断,而直接从if语句退出,继续向下执行。而等待队列后面被唤醒的进程随后也会被调度执行,同样也不会执行if判断,退出if语句,继续向下执行,这显然是不应该的。因为生产者只往缓冲区写入一个数,被等待队列的队首进程取走了,由于等待队列队首进程已经取走了那个数,他应该已经将sem修改为sem=-1,其他等待的进程应该再次执行if判断,由于sem=-1<0,会继续睡眠。要让其他等待进程再次执行时,要重新进行判断,所以不能是if语句了,必须是while语句才可以。
下面是实现sem_wait的代码:
int sys_sem_wait(sem_t *sem)
{
cli();
sem->value--;
while( sem->value < 0 )
sleep_on(&(sem->queue))
sti();
return 0;
}
但是没有考虑到有一种特殊的信号量:互斥信号量。比如要读写一个文件,一次只能允许一个进程读写,当一个进程要读写该文件时,需要先执行sem_wait(file),此后在该进程读写文件期间,若有其他进程也要读写该文件,则执行流程分析如下:
进程P1申请读写该文件,value=-1,sleep_on(&file->queue)。
进程P2申请读写该文件,value=-2,sleep_on(&file->queue)。
原来读写该文件的进程读写完毕,置value=-1,并唤醒等待队列的队首进程P2。
进程P2再次执行,唤醒进程P1,此时执行while()判断,不能跳出while()判断,继续睡眠等待。此时文件并没有被占用,P2完全可以读写该文件,所以程序运行出错了。出错原因在于,修改信号量的语句,必须放在while()判断的后面,因为执行while()判断,进程有可能睡眠,而这种情况下,是不需要记录有多少个进程在睡眠的,因为sleep_on()函数形成的隐式的等待队列已经记录下了进程的等待情况。
正确的sem_wait代码如下:
int sys_sem_wait(sem_t *sem)
{
cli();
while( sem->value <= 0 ) //
sleep_on(&(sem->queue)); //这两条语句顺序不能颠倒,很重要,是关于互斥信号量能不
sem->value--; //能正确工作的!!!
sti();
return 0;
}
2,sem_post()的实现
sem_post的实现必须结合sem_wait的实现情况
还是拿生产者和消费者的例子来分析。当缓冲区为空,没有数可取,value=0
消费者C1执行sem_wait(),value=0,sleep_on(&queue)。
消费者C2执行sem_wait(),value=0,sleep_on(&queue)。
等待队列的情况如下:
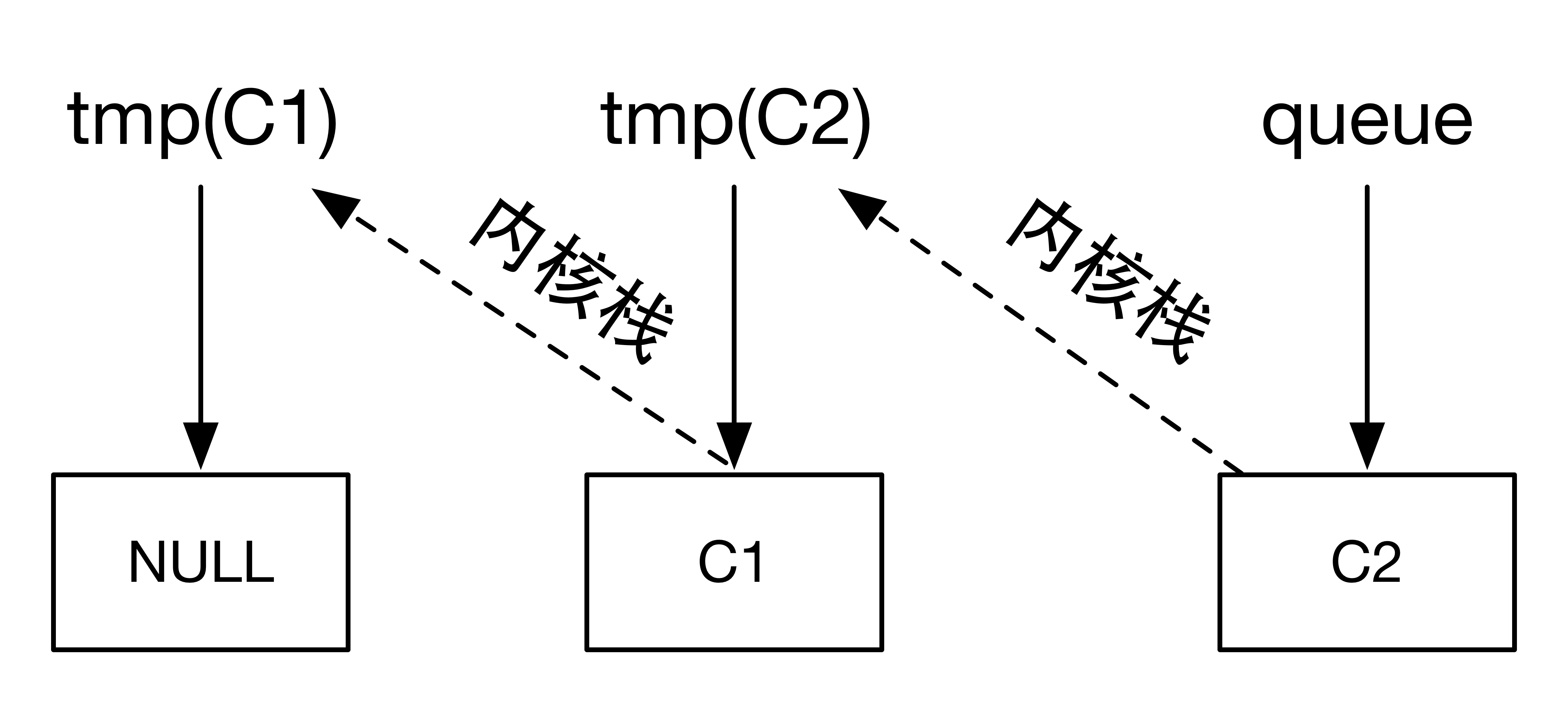
生产者执行sem_post(),value=1,wake_up(&queue),唤醒消费者C2。队列的情况如下:
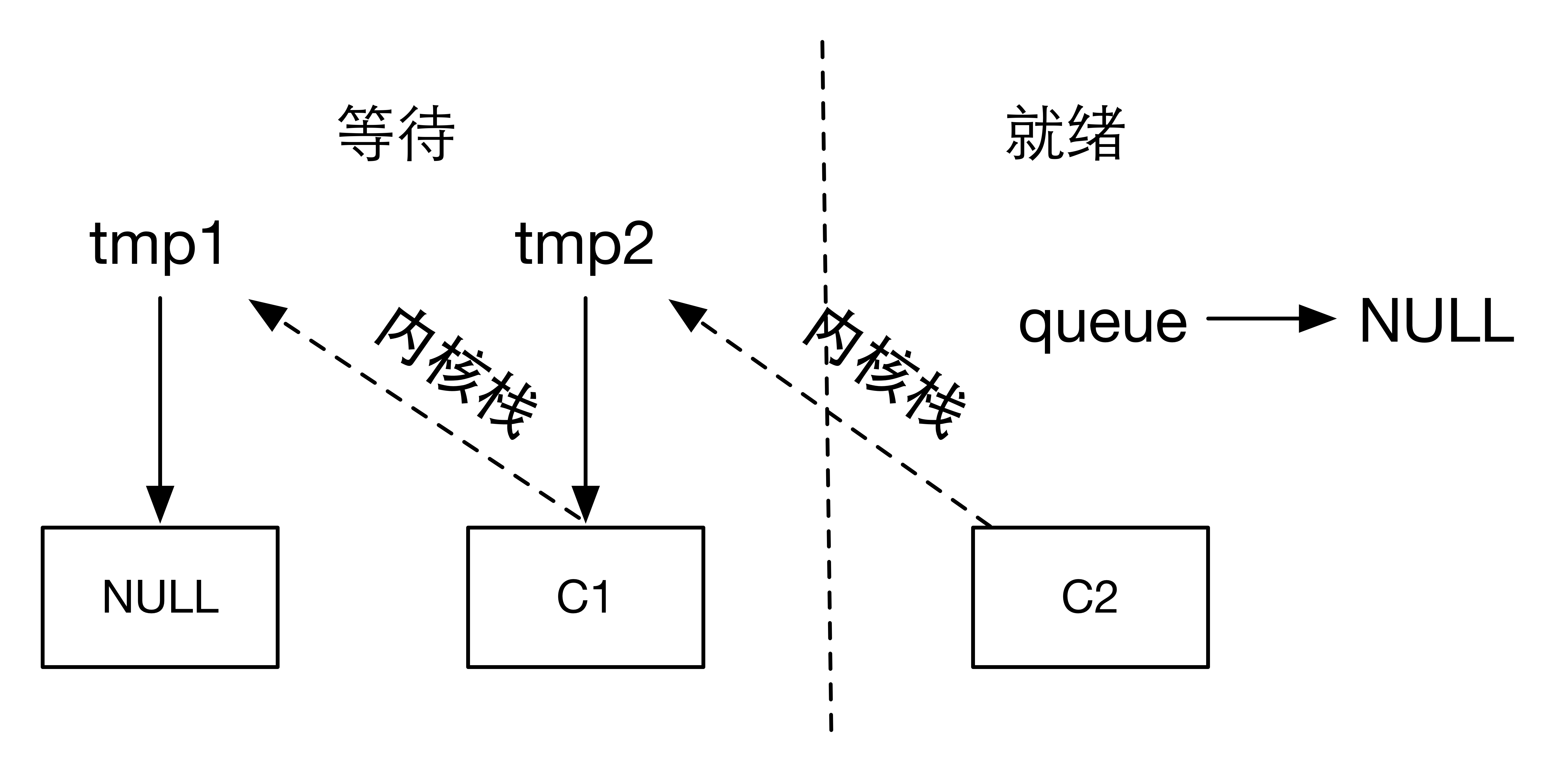
生产者再次执行sem_post(),value=2,wake_up(&queue)相当于wake_up(NULL)。队列情况如上。
消费者C2再次执行,唤醒C1,跳出while(),value=1,继续向下执行。
消费者C1再次执行,跳出while(),value=0,继续向下执行。
由此可以看出,sem_post里面唤醒进程的判断条件是:value<=1。
sem_post的实现代码如下:
int sys_sem_post(sem_t *sem)
{
cli();
sem->value++;
if( (sem->value) <= 1)
wake_up(&(sem->queue));
sti();
return 0;
}
练习代码链接:
https://gitee.com/zhang_yu_peng/practice-code/blob/master/冒泡排序.cpp