Linux中的EXT2文件系统
1.分区
分区是为了方便操作系统在一块硬盘上进行数据访问,即去哪里读取数据。
分区的要点是记录每一个分区的起始和结束柱面。这个数据存在MBR的分区表中。MBR只能存四个分区的记忆,可以是四个主分区或三个主分区一个扩展分区。(3P+1E或4P)
2.文件系统
对分区进行格式化是为了在分区上建立文件系统。一个分区通常只能格式化为一个文件系统,但是磁盘阵列等技术可以将一个分区格式化为多个文件系统。
划分好分区后,接着就要将分区格式化为操作系统能识别的文件系统了。比如针对linux就要格式化成它能识别的如EXT2文件系统,格式化成windows的文件系统就不行。
理论上说,一个分区只能就是一个文件系统。不能将分区格式化为ext3的同时也格式化成fat32。
硬盘的最小存储单位是扇区,但是磁头一个扇区一个扇区的读取效率太低,因此有了逻辑块的概念,它的大小是扇区的2^n倍。这样磁头就可以一次读一块。但是块的大小规划并不是越大越好,比如块大小规划为4KB,假设一个文件只要0.1KB,根据ext2文件系统的规定,一个块最多只能容纳一个文件,所以剩余的3.9KB就浪费了。因此在规划块的大小时,要考虑两个问题:
文件读取的效率;
文件大小可能造成硬盘空间的浪费。
3.inode
linux 系统中每个文件包括内容数据和文件属性两部分,这两部分分开来存储,文件内容存在块中,文件属性存在inode中。当分区被初始化为ext2文件系统时,它一定会有inode表和块区域这两个区域。inode记录文件的属性,以及文件内容放在哪个块中。这些属性包括:
- 该文件的存取模式(read/write/excute);
- 该文件的拥有者与群组(owner/group);
- 该文件的容量;
- 该文件创建或状态改变的时间(ctime);
- 最近一次的读取时间(atime);
- 最近修改的时间(mtime);
- 定义文件特性的旗标(flag),如 SetUID...;
- 该文件真正内容的指向 (pointer);
- 一个inode的大小为128个字节。
4.Linux的EXT2文件系统
Linux系统是如何读取一个文件的?下面分别针对目录和文件来说明:
目录
ext2文件系统建立一个目录时,会给该目录分配一个indoe和至少一个块。inode记录该目录的相关属性,并指向分配到的那个块。这个块记录了这个目录下的相关文件或目录的关联性。
文件
建立普通文件时,会给该文件分配一个inode与相对于该文件大小的块数量。如一个块大小为4KB,建立一个100KB的文件,linux将分配一个inode和25个块来存储该文件。
注意inode本省不记录文件名,而是记录文件的相关属性,文件名是记录在目录所属的块区域中的。
因此要读取一个文件的内容时,Linux会从 / 开始,一直获取到该文件的上层目录所在的inode,再由该目录的块区域中的文件名对应的inode号来找到对应的文件,最后根据inode中的指针找到最终的文件内容。
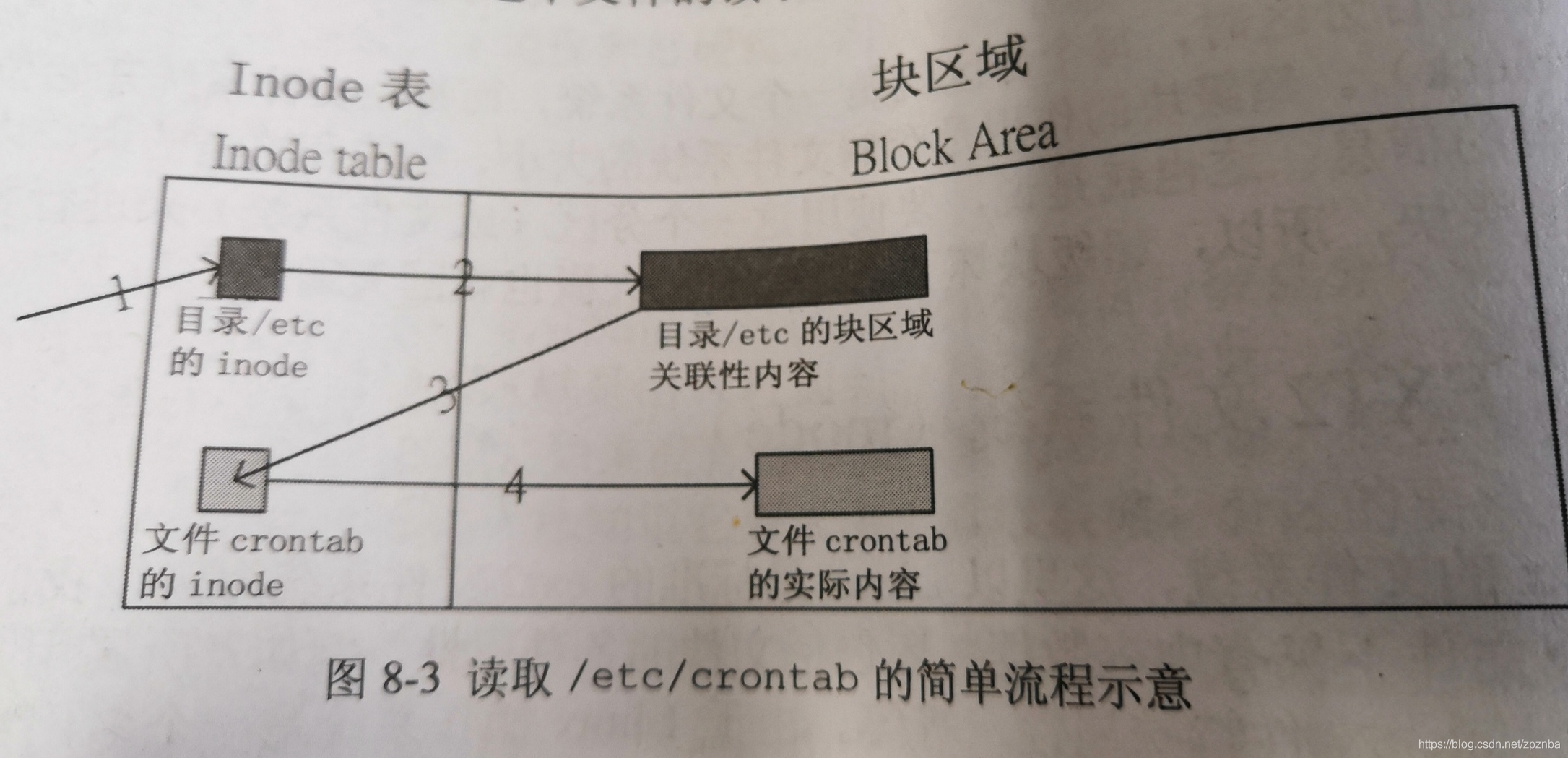
如上图,读取/etc/crontab的流程为:
1.根据/根目录的块中找到/etc对应的inode号
2.根据/etc 目录的块中的inode数据,查找到crontab的inode号
3.根据查到的inode号来获取该文件的属性,并且前往该inode所指的块,顺利获取crontab 的文件内容。
注意:
1.块和inode在一开始初始化时就已经固定好了。
2.分区的规划不是越大越好,因为硬盘上的数据进进出出,整个分区上的文件无法连续写在一起,而是填入式的,将数据填入没有使用的块中。如果文件写入的块太分散,就会有文件碎片产生,比如一个文件分别记录在分区的最前面和最后面的块时,会造成机械手臂移动幅度过大,数据读取效率就很低。所以要针对主机的具体用途去规划 。
3.在建立每个ext2文件系统时,会按照分区大小,确定若干个块组(block group),每个块组如上图又包括:
超级块:记录这个文件系统相关信息,没有它就没有这个文件系统。它记录的主要信息包括inode/block的总量,使用量,剩余量,以及文件系统的格式与相关信息;
组描述:记录这个块从何处开始记录;
块位图:通过block bitmap来记录每个block的状态,如是否被使用,这样操作系统可以很快去找到空的block分配给新文件;
inode位图:与block bitmap类似,记录每个inode的状态,如是否已经被使用,这样操作系统可以很快去找到空的inode分配给新文件;
inode table: 多个inode的信息;
Data Blocks: 每个块组的数据存放区。
当新建一个文件或目录时:
1.根据inode位图/块位图的信息,找到尚未使用的inod与块,将文件的属性和数据分别写入inode与块。
2.将刚刚使用的inode与块的号码告知超级块、inode位图、块位图等,让这些元数据更新。
日志
如果突然断电,那么文件系统会发生错误,比如数据只记录到上述的操作1,操作2尚未进行,就会发生元数据和数据存放区不一致的情况。如果强制进行一致性检查,需要检查整个分区,很费时。因此引入日志系统进行文件操作的记录,可以简化一致性检查的步骤:ext3/ext4 文件系统引入了日志功能,可以利用日志来修复文件系统。
超级块,i节点,数据块,目录块,间接块
一、物理磁盘到文件系统
文件系统用来存储文件内容、文件属性、和目录。这些类型的数据如何存储在磁盘块上的呢?unix/linux使用了一个简单的方法。如图所示.

它将磁盘块分为三个部分:
1)超级块,文件系统中第一个块被称为超级块。这个块存放文件系统本身的结构信息。比如,超级块记录了每个区域的大小,超级块也存放未被使用的磁盘块的信息。
2) i-节点表。超级块的下一个部分就是i-节点表,每个文件都有一些属性,如文件的大小、文件所有者、和创建时间等,这些性质被记录在一个称为i-节点的结构中。所有i-节点都有相同的大小,并且i-节点表是这些结构的一个列表,文件系统中每个文件在该表中都有一个i-节点。
3)数据区。文件系统的第3个部分是数据区。文件的内容保存在这个区域。磁盘上所有块的大小都一样。如果文件包含了超过一个块的内容,则文件内容会存放在多个磁盘块中。一个较大的文件很容易分布上千个独立的磁盘块中.
二、创建一个文件的过程
我们现在知道文件的内容和属性是分开存放的,那么又是如何管理它们的呢?现在我们以创建一个文件为例来讲解。在命令行输入命令:
$ who > userlist
当完成这个命令时。文件系统中增加了一个存放命令who输出内容的新文件,那么这整个过程到底是怎么回事呢?
文件的属性和内容:内核将文件内容存放在数据区,文件属性存放在i-节点,文件名存放在目录。图2显示了创建一个文件的例子,假如这个新文件要3 个存储块来存放内容。
包括如下四个步骤:
1)存储属性,也就是文件属性的存储,内核先找到一块空的i-节点。图2中。内核找到i-节点号47。内核把文件的信息记录其中。如文件的大小、文件所有者、和创建时间等
2)存储数据 ,即文件内容的存储,由于该文件需要3个数据块。因此内核从自由块的列表中找到3个自由块。图2中分别为627、200、992,内核缓冲区的第一块数据复制到块627,第二和第三分别复制到200和992.
3)记录分配情况,数据保存到了三个数据块中。所以必须要记录起来,以后再找到正确的数据。分配情况记录在文件的i-节点中的磁盘序号列表里。这3个编号分别放在最开始的3个位置。
4)添加文件名到目录,新文件的名字是userlist, 内核将文件的入口(47,userlist)添加到目录文件里。文件名和i-节点号之间的对应关系将文件名和文件和文件的内容属性连接起来,找到文件名就找到文件的i-节点号,通过i-节点号就能找到文件的属性和内容。
三、创建一个目录的过程
前面说了创建一个文件的大概过程,那么创建一个目录时又是怎么回事呢?
我们知道,目录其实也是文件,只是它的内容比较特殊:包含文件名字列表,列表一般包含两个部分:i-节点号和文件名。所以它的创建过程和文件创建过程一样,只是第二步写的内容不同。一个目录创建时至少包括两个链接:“.”,“..”
我们可以通过系统命令来查看目录的内容:#ls -lia
上图的结果是文件名和对应的i-节点号,其中“.”表示是当前目录,而“..”是当前目录的父目录。但也有特殊情况,我们查看根目录的情况:
[root@localhost ~]# ls -i1a /
2 .
2 ..
98305 .autofsck
1310721 backup
我们发现“.”和“..”都指向i-节点2.实际上当用mkfs创建一个文件系统时,mkfs会将根目录的父目录指向自己
四、如果有大文件如何实现
文件内容的分配情况是必须记录在i-节点的磁盘序号列表里的。但是i-节点只包含一个最多含有13个项的分配链表,如果分配的数据块超过13个块时怎么办?
Linux用到一个间接块来解决此问题.比如我们要记录14个块的编号,可以把前面10个记录在i-节点的磁盘序号列表里。另外4个编号放在一个数据块中。在i-节点的第11项里记录存放编号的数据块的指针,通过这个指针就能找到余下的4个数据块的编号,这个用来存放编号的数据就叫间接块。道理就和某些货物放在架上而把剩下的放在仓库里,并打个标签记下在仓库中具体位置的编号一样。
但当间接块也存满了时我们还可以再开第二个间接块,甚至3、4、5。。。更多额外块。但内核并不会把这些块记录在文件的i-节点的第12、13项里。而是开辟一个新的块的来存放这些间接块的列表,并在i-节点的第12项存放这一新额外块的编号。这存放着那个存储着第2、3、4、及后继额外块的编号的块的编号,这个块称为二级间接块.
同理当二级间接块饱和时还可以开辟第三级。
EXT2文件系统中目录树的读取与创建
在Linux系统下,每个文件(不管是一般文件还是目录)都会占用给一个inode,且可依据文件内容的大小来分配多个block给该文件使用。
1. 目录:
当我们在Linux系统中建立一个目录时,文件系统会分配一个inode与至少一块block给该目录。其中,inode记录该目录的相关权限与属性,并可记录分配到的那块block号码;而block则记录该目录下的文件名与对应文件名占用的inode号码。
即:inode本身并不记录文件名,文件名的记录在inode指向的block中。因此,新增/删除/更名文件名与目录的w权限有关。
2. 文件:
当我们在Linux文件系统中建立一个一般文件时,ext2会分配一个inode与相对于该文件大小的block数量给该文件。
目录树的读取:
目录树是由根目录开始读起,因此系统透过挂载的信息可以找到挂载点的inode号码,此时就能够得到根目录的inode内容,并依据该inode读取根目录的block内的文件名数据,再一层一层的往下读到正确的文件名。
以读取/etc/passwd这个文件为例:
- / 的inode:
透过挂载点的信息找到根目录的inode号码,inode规范的权限让我们可以读取该block的内容,并且inode中记录了对应block的号码 - / 的block:
进入上个步骤中block号码指向的block区域,并找到该内容有 etc/ 目录 的inode号码 - etc/ 的inode:
读取 etc/ 的inode得知用户具有r与x的权限, 因此可以读取 etc/ 的block内容,并且inode中记录了对应block的号码 - etc/的block:
进入上个步骤中block号码指向的block区域,找到该内容有 passwd 文件的inode号码 - passwd 的inode:
读取 passwd 文件的inode得知用户具有r的权限,因此可以读取 passewd 文件的block内容,并且inode中记录了对应block的号码 - passwd 的block:
最后将该block内容的数据读出来
新建文件:
这时还需要用到block bitmap和inode bitmap。
- 先确定用户对于欲新增文件的目录是否具有w与x的权限,若有的话才能新增;
- 根据inode bitmap找到没有使用的inode号码,并将新文件的权限、属性写入;
- 根据block bitmap找到没有使用的block号码, 并将实际的数据写入block中,且更新inode的block指向数据;
- 将刚刚写入的inode与block数据同步更新inode bitmap与block bitmap,并更新superblock的内容。
代码练习:
https://gitee.com/zhang_yu_peng/practice-code/blob/master/遍历.cpp