词典数据:数据词典(Data Dictionary,简称DD)就是用来定义数据流图中的各个成分的具体含义的。对数据流图中出现的每一个数据流、文件、加工给出详细定义。
散列表:散列表(Hash table,也叫哈希表),是根据关键码值(Key value)而直接进行访问的数据结构。也就是说,它通过把关键码值映射到表中一个位置来访问记录,以加快查找的速度。这个映射函数叫做散列函数,存放记录的数组叫做散列表。
倒排索引:倒排索引源于实际应用中需要根据属性的值来查找记录。这种索引表中的每一项都包括一个属性值和具有该属性值的各记录的地址。由于不是由记录来确定属性值,而是由属性值来确定记录的位置,因而称为倒排索引(inverted index)。带有倒排索引的文件我们称为倒排索引文件,简称倒排文件(inverted file)。
海量数据处理专题——倒排索引(搜索引擎之基石) 传送门


VSM全称是Vector Space Model(向量空间模型),是IR(Information Retrieval信息检索)模型中的一种,由于其简单,直观,高效,所以被广泛的应用到搜索引擎的架构中。98年的Google就是凭借这样的一个模型,开始了它的疯狂扩张之路。废话不多说,让我们来看看到底VSM是一个什么东东。
在开始之前,我默认大家对线性代数里面的向量(Vector)有一定了解的。向量是既有大小又有方向的量,通常用有向线段表示,向量有:加、减、倍数、内积、距离、模、夹角的运算。
文档(Document):一个完整的信息单元,对应的搜索引擎系统里,就是指一个个的网页。
标引项(Term):文档的基本构成单位,例如在英文中可以看做是一个单词,在中文中可以看作一个词语。
查询(Query):一个用户的输入,一般由多个Term构成。
那么用一句话概况搜索引擎所做的事情就是:对于用户输入的Query,找到最相似的Document返回给用户。而这正是IR模型所解决的问题:信息检索模型是指如何对查询和文档进行表示,然后对它们进行相似度计算的框架和方法。
举个简单的例子:
现在有两篇文章(Document)分别是 “春风来了,春天的脚步近了” 和 “春风不度玉门关”。然后输入的Query是“春风”,从直观上感觉,前者和输入的查询更相关一些,因为它包含有2个春,但这只是我们的直观感觉,如何量化呢,要知道计算机是门严谨的学科^_^。这个时候,我们前面讲的Term和VSM模型就派上用场了。
首先我们要确定向量的维数,这时候就需要一个字典库,字典库的大小,即是向量的维数。在该例中,字典为{春风,来了,春天, 的,脚步,近了,不度,玉门关} ,文档向量,查询向量如下图:
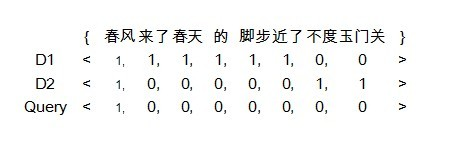
VSM模型示例
PS:为了简单起见,这里分词的粒度很大。
将Query和Document都量化为向量以后,那么就可以计算用户的查询和哪个文档相似性更大了。简单的计算结果是D1和D2同Query的内积都是1,囧。当然了,如果分词粒度再细一些,查询的结果就是另外一个样子了,因此分词的粒度也是会对查询结果(主要是召回率和准确率)造成影响的。
上述的例子是用一个很简单的例子来说明VSM模型的,计算文档相似度的时候也是采用最原始的内积的方法,并且只考虑了词频(TF)影响因子,而没有考虑反词频(IDF),而现在比较常用的是cos夹角法,影响因子也非常多,据传Google的影响因子有100+之多。
大名鼎鼎的Lucene项目就是采用VSM模型构建的,VSM的核心公式如下(由cos夹角法演变,此处省去推导过程)

VSM模型公式
从上面的例子不难看出,如果向量的维度(对汉语来将,这个值一般在30w-45w)变大,而且文档数量(通常都是海量的)变多,那么计算一次相关性,开销是非常大的,如何解决这个问题呢?不要忘记了,我们这节的主题就是 倒排索引,主角终于粉墨登场了!!!
倒排索引
倒排索引非常类似我们前面提到的Hash结构。以下内容来自维基百科:
倒排索引(英语:Inverted index),也常被称为反向索引、置入档案或反向档案,是一种索引方法,被用来存储在全文搜索下某个单词在一个文档或者一组文档中的存储位置的映射。它是文档检索系统中最常用的数据结构。
有两种不同的反向索引形式:
- 一条记录的水平反向索引(或者反向档案索引)包含每个引用单词的文档的列表。
- 一个单词的水平反向索引(或者完全反向索引)又包含每个单词在一个文档中的位置。
由上面的定义可以知道,一个倒排索引包含一个字典的索引和所有词的列表。其中字典索引中包含了所有的Term(通俗理解为文档中的词),索引后面跟的列表则保存该词的信息(出现的文档号,甚至包含在每个文档中的位置信息)。下面我们还采用上面的方法举一个简单的例子来说明倒排索引。
例如现在我们要对三篇文档建立索引(实际应用中,文档的数量是海量的):
文档1(D1):中国移动互联网发展迅速
文档2(D2):移动互联网未来的潜力巨大
文档3(D3):中华民族是个勤劳的民族
那么文档中的词典集合为:{中国,移动,互联网,发展,迅速,未来,的,潜力,巨大,中华,民族,是,个,勤劳}
建好的索引如下图:
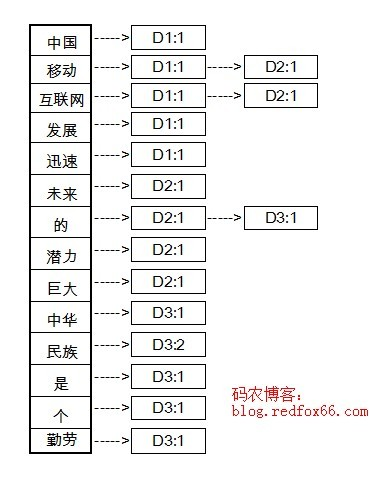
在上面的索引中,存储了两个信息,文档号和出现的次数。建立好索引以后,我们就可以开始查询了。例如现在有一个Query是”中国移动”。首先分词得到Term集合{中国,移动},查倒排索引,分别计算query和d1,d2,d3的距离。有没有发现,倒排表建立好以后,就不需要在检索整个文档库,而是直接从字典集合中找到“中国”和“移动”,然后遍历后面的列表直接计算。
对倒排索引结构我们已经有了初步的了解,但在实际应用中还有些需要解决的问题(主要是由海量数据引起的)。笔者列举一些问题,并给出相应的解决方案,抛砖以引玉,希望大家可以展开讨论:
1.左侧的索引表如何建立?怎么做才能最高效?
可能有人不假思索回答:左侧的索引当然要采取hash结构啊,这样可以快速的定位到字典项。但是这样问题又来了,hash函数如何选取呢?而且hash是有碰撞的,但是倒排表似乎又是不允许碰撞的存在的。事实上,虽然倒排表和hash异常的相思,但是两者还是有很大区别的,其实在这里我们可以采用前面提到的Bitmap的思想,每个Term(单词)对应一个位置(当然了,这里不是一个比特位),而且是一一对应的。如何能够做到呢,一般在文字处理中,有很多的编码,汉字中的GBK编码基本上就可以包含所有用到的汉字,每个汉字的GBK编码是确定的,因此一个Term的”ID”也就确定了,从而可以做到快速定位。注:得到一个汉字的GBK号是非常快的过程,可以理解为O(1)的时间复杂度。
2.如何快速的添加删除更新索引?
有经验的码农都知道,一般在系统的“做加法”的代价比“做减法”的代价要低很多,在搜索引擎中中也不例外。因此,在倒排表中,遇到要删除一个文档,其实不是真正的删除,而是将其标记删除。这样一个减法操作的代价就比较小了。
3.那么多的海量文档,如果存储呢?有么有什么备份策略呢?
当然了,一台机器是存储不下的,分布式存储是采取的。一般的备份保存3份就足够了。
数据词典创建——mmseg4j中文分词包使用报告传送门
Spring的web应用启动加载数据字典方法可以使用Listener监听器
查询:一次一单词
查询:一次一文档
一次一文档(Document at a Time):搜索引擎接收到用户的查询后,首先将每个单词的倒排列表从磁盘读入内存。然后以倒排列表中包含的文档为单位,计算每个文档与查询的最终相似性得分,最后返回得分最后的K个文档。该方法以文档为单位,纵向进行分数累计,之后移动到后续文档接着计算,即计算过程是“先纵向再横向”的。整个过程,我们只需要在内存中维护一个大小为K的优先队列,用来保存计算过程中得分最高的K个文档即可。
一次一单词(Term at a Time):搜索引擎接收到用户的查询后,首先将每个单词的倒排列表从磁盘读入内存。然后以词典中的单词为单位,一次一单词是采取“先横向再纵向”的方式。在单词---文档矩阵中首先进行横向移动,在计算完毕某个单词倒排列表中包含的所有文档后,接着计算下一个单词倒排列表中包含的文档ID,即进行纵向计算,如果发现某个文档ID已经有了得分,则在原先得分基础上进行累加。
排序:TF*IDF的大小
排序:向量空间模型
比如,一篇文章一共100个词汇,其中“机器学习”一共出现10次,那么他的TF就是10/100=0.1。这么看来好像仅仅是一个TF就能用来评估一个关键词的重要性(出现频率越高就越重要),其实不然,单纯使用TF来评估关键词的重要性忽略了常用词的干扰。常用词就是指那些文章中大量用到的,但是不能反映文章性质的那种词,比如:因为、所以、因此等等的连词,在英文文章里就体现为and、the、of等等的词。这些词往往拥有较高的TF,所以仅仅使用TF来考察一个词的关键性,是不够的。这里我们要引出IDF,来帮助我们解决这个问题。
IDF:IDF,英文全称:Inverse Document Frequency,即“反文档频率”。先看什么是文档频率,文档频率DF就是一个词在整个文库词典中出现的频率,就拿上一个例子来讲:一个文件集中有100篇文章,共有10篇文章包含“机器学习”这个词,那么它的文档频率就是10/100=0.1,反文档频率IDF就是这个值的倒数,即10。因此得出它的计算公式:
散列表(Hash table,也叫哈希表),是根据关键码值(Key value)而直接进行访问的数据结构。也就是说,它通过把关键码值映射到表中一个位置来访问记录,以加快查找的速度。这个映射函数叫做散列函数,存放记录的数组叫做散列表。