day60
http协议:https://www.cnblogs.com/liwenzhou/p/8620663.html
HTTP状态码
所有HTTP响应的第一行都是状态行,依次是当前HTTP版本号,3位数字组成的状态代码,以及描述状态的短语,彼此由空格分隔。
状态代码的第一个数字代表当前响应的类型:
- 1xx消息——请求已被服务器接收,继续处理
- 2xx成功——请求已成功被服务器接收、理解、并接受
- 3xx重定向——需要后续操作才能完成这一请求
- 4xx请求错误——请求含有词法错误或者无法被执行
- 5xx服务器错误——服务器在处理某个正确请求时发生错误
虽然 RFC 2616 中已经推荐了描述状态的短语,例如"200 OK"(状态码 状态码描述),"404 Not Found",但是WEB开发者仍然能够自行决定采用何种短语,用以显示本地化的状态描述或者自定义信息。
HTTP请求格式

'GET / HTTP/1.1 请求行( 请求方法 协议版本) Host: 127.0.0.1:8001 请求头部 User-Agent: Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:64.0) Gecko/20100101 Firefox/64.0 Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8 Accept-Language: zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2 Accept-Encoding: gzip, deflate Connection: keep-alive Upgrade-Insecure-Requests: 1' 无请求数据
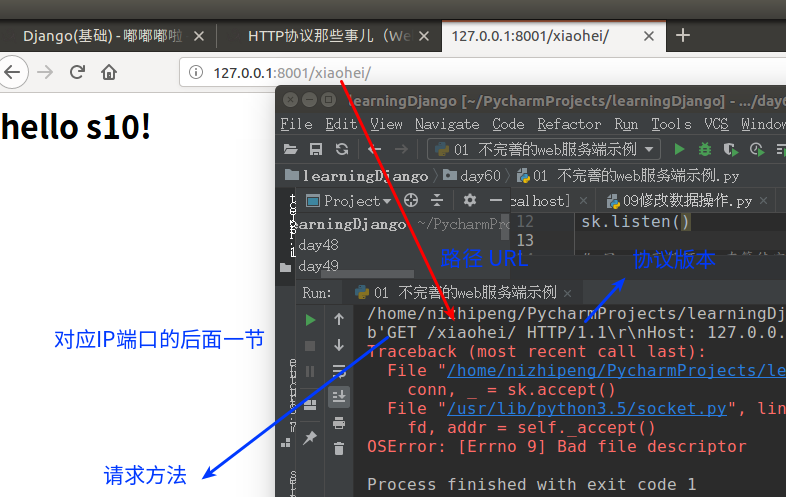
HTTP请求格式。

网页请求,后台回应。
===================================================================
HTTP响应格式

""" 不完善的web服务端示例 """ import socket # 生成socket实例对象 sk = socket.socket() # 绑定IP和端口 sk.bind(("127.0.0.1", 8001)) # 监听 sk.listen() # 写一个死循环,一直等待客户端来连我 while 1: # 获取与客户端的连接 conn, _ = sk.accept() # 接收客户端发来消息 data = conn.recv(8096) print(data) # HTTP响应格式 协议版本 状态码 状态码描述 回车符换行符 conn.send(b'http/1.1 200 ok ') # 给客户端回复消息 conn.send(b'<h1>hello s10!</h1>') # 关闭 conn.close() sk.close()
# HTTP响应格式 协议版本 状态码 状态码描述 回车符换行符
conn.send(b'http/1.1 200 ok ')
按HTTP响应格式发送数据。
效果:
========================================================================================
响应头,请求头
1 """ 2 不完善的web服务端示例 3 """ 4 5 import socket 6 7 # 生成socket实例对象 8 sk = socket.socket() 9 # 绑定IP和端口 10 sk.bind(("127.0.0.1", 8001)) 11 # 监听 12 sk.listen() 13 14 # 写一个死循环,一直等待客户端来连我 15 while 1: 16 # 获取与客户端的连接 17 conn, _ = sk.accept() 18 # 接收客户端发来消息 19 data = conn.recv(8096) 20 print(data) 21 # 给客户端回复消息 22 conn.send(b'http/1.1 200 OK content-type:text/html; charset=utf-8 ') 23 # 想让浏览器在页面上显示出来的内容都是响应正文 24 conn.send(b'<h1>hello s10!</h1>') 25 # 关闭 26 conn.close() 27 sk.close()
其中content-type:text/html; charset=utf-8在响应格式中属于响应头。
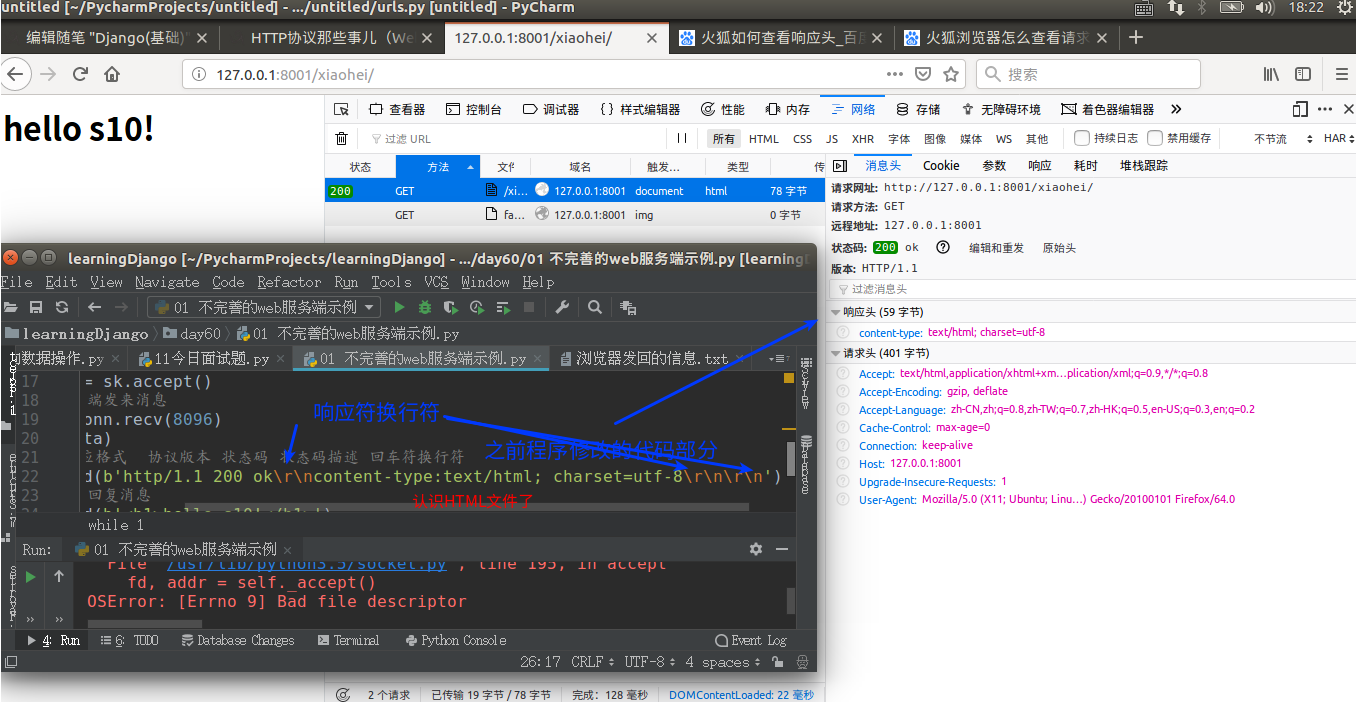
22行为响应格式。
关于HTTP协议:
1. 浏览器往服务端发的叫 请求(request)
请求的消息格式:
请求方法 路径 HTTP/1.1
k1:v1
k2:v2
请求数据
2. 服务端往浏览器发的叫 响应(response)
响应的消息格式:
HTTP/1.1 状态码 状态描述符
k1:v1
k2:v2
响应正文 <-- html的内容
根据不同的路径返回不同的内容web服务端示例
1 """ 2 完善的web服务端示例 3 根据不同的路径返回不同的内容 4 """ 5 6 import socket 7 8 # 生成socket实例对象 9 sk = socket.socket() 10 # 绑定IP和端口 11 sk.bind(("127.0.0.1", 8000)) 12 # 监听 13 sk.listen() 14 15 # 写一个死循环,一直等待客户端来连我 16 while 1: 17 # 获取与客户端的连接 18 conn, _ = sk.accept() 19 # 接收客户端发来消息 20 data = conn.recv(8096) 21 # 把收到的数据转成字符串类型 22 data_str = str(data, encoding="utf-8") # bytes("str", enconding="utf-8") 23 # print(data_str) 24 # 用 去切割上面的字符串 25 l1 = data_str.split(" ") 26 # print(l1[0]) 27 # 按照空格切割上面的字符串 28 l2 = l1[0].split() #GET /xiaohei/ HTTP/1.1 将第一行根据空格分开 29 url = l2[1] #取url 取第一行第二个数据 30 # 给客户端回复消息 31 conn.send(b'http/1.1 200 OK content-type:text/html; charset=utf-8 ') 32 # 想让浏览器在页面上显示出来的内容都是响应正文 33 34 # 根据不同的url返回不同的内容 35 if url == "/yimi/": 36 response = b'<h1>hello yimi!</h1>' 37 elif url == "/xiaohei/": 38 response = b'<h1>hello xiaohei!</h1>' 39 else: 40 response = b'<h1>404! not found!</h1>' 41 conn.send(response) 42 # 关闭 43 conn.close() 44 sk.close()
根据不同路径返回不同内容。
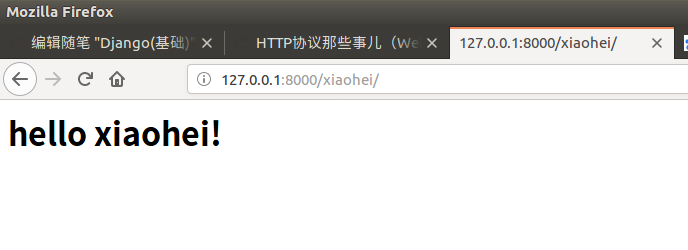
动态的网页
不同时候访问,内容不同。
1 """ 2 完善的web服务端示例 3 函数版根据不同的路径返回不同的内容 4 进阶函数版 不写if判断了,用url名字去找对应的函数名 5 返回html页面 6 返回动态的html页面 7 """ 8 9 import socket 10 11 # 生成socket实例对象 12 sk = socket.socket() 13 # 绑定IP和端口 14 sk.bind(("127.0.0.1", 8001)) 15 # 监听 16 sk.listen() 17 18 # 定义一个处理/yimi/的函数 19 def yimi(url): 20 with open("yimi.html", "r", encoding="utf-8") as f:#字符串类型读取 21 ret = f.read() 22 import time 23 # 得到替换后的字符串 html中内容被时间戳替换 24 ret2 = ret.replace("@@xx@@", str(time.time())) 25 return bytes(ret2, encoding="utf-8") 26 27 28 # 定义一个处理/xiaohei/的函数 29 def xiaohei(url): 30 with open("xiaohei.html", "rb") as f:#二进制读取 31 ret = f.read() 32 return ret 33 34 35 # 定义一个专门用来处理404的函数 36 def f404(url): 37 ret = "你访问的这个{} 找不到".format(url) 38 return bytes(ret, encoding="utf-8") 39 40 41 url_func = [ 42 ("/yimi/", yimi), 43 ("/xiaohei/", xiaohei), 44 ] 45 46 47 # 写一个死循环,一直等待客户端来连我 48 while 1: 49 # 获取与客户端的连接 50 conn, _ = sk.accept() 51 # 接收客户端发来消息 52 data = conn.recv(8096) 53 # 把收到的数据转成字符串类型 54 data_str = str(data, encoding="utf-8") # bytes("str", enconding="utf-8") 55 # print(data_str) 56 # 用 去切割上面的字符串 57 l1 = data_str.split(" ") 58 # print(l1[0]) 59 # 按照空格切割上面的字符串 60 l2 = l1[0].split() 61 url = l2[1] 62 # 给客户端回复消息 63 conn.send(b'http/1.1 200 OK content-type:text/html; charset=utf-8 ') 64 # 想让浏览器在页面上显示出来的内容都是响应正文 65 66 # 根据不同的url返回不同的内容 67 # 去url_func里面找对应关系 68 for i in url_func: 69 if i[0] == url: 70 func = i[1] 71 break 72 # 找不到对应关系就默认执行f404函数 73 else: 74 func = f404 75 # 拿到函数的执行结果 76 response = func(url) 77 # 将函数返回的结果发送给浏览器 78 conn.send(response) 79 # 关闭连接 80 conn.close()
html文件
xiaohei.html
<!DOCTYPE html> <html lang="zh-CN"> <head> <meta charset="UTF-8"> <meta http-equiv="x-ua-compatible" content="IE=edge"> <meta name="viewport" content="width=device-width, initial-scale=1"> <title>小黑</title> </head> <body> <h1>day60 Web框架本质都讲了些啥啊</h1> <p>小黑啊</p> <p>啊,真的是黑啊!</p> </body> </html>
yimi.html
<!DOCTYPE html> <html lang="zh-CN"> <head> <meta charset="UTF-8"> <meta http-equiv="x-ua-compatible" content="IE=edge"> <meta name="viewport" content="width=device-width, initial-scale=1"> <title>yimi</title> </head> <body> <h1>day60 web框架的本质</h1> <p>海燕</p> <p>在苍茫的大海上,狂风卷积着乌云,在乌云和大海之间,海燕像黑色的闪电,在高傲的飞翔</p> <a href="http://www.luffycity.com">程序员的梦想,点我直达</a> <audio src="song.ogg" controls="controls"></audio> <!--其中为被替换内容--> <p>@@xx@@</p> </body> </html>
@@XX@@被替换。
动态的网页:
本质上都是字符串的替换
字符串替换发生在什么地方:
在服务端替换完再返回给浏览器!!!
总结一下:
1. web框架的本质:
socket服务端 与 浏览器的通信
2. socket服务端功能划分:
a. 负责与浏览器收发消息(socket通信) --> wsgiref/uWsgi/gunicorn...
b. 根据用户访问不同的路径执行不同的函数
c. 从HTML读取出内容,并且完成字符串的替换 --> jinja2(模板语言)
3. Python中 Web框架的分类:
1. 按上面三个功能划分:
1. 框架自带a,b,c --> Tornado
2. 框架自带b和c,使用第三方的a --> Django
3. 框架自带b,使用第三方的a和c --> Flask
2. 按另一个维度来划分:
1. Django --> 大而全(你做一个网站能用到的它都有)
2. 其他 --> Flask 轻量级