自动化测试工具运用
在使用这些工具的路上,一路艰难险阻,困难重重,逐个击破,记此篇。上篇:对自动化测试工具的简要认识
最终效果
学有所获、学有所用
Fibonacci数列
问题描述
Fibonacci数列的递推公式为:Fn=Fn-1+Fn-2,其中F1=F2=1。
当n比较大时,Fn也非常大,现在我们想知道,Fn除以10007的余数是多少。
数据规模与约定
1 <= n <= 1,000,000。
| 输入格式 | 输出格式 |
|---|---|
| 输入包含一个整数n。 | 输出一行,包含一个整数,表示Fn除以10007的余数。 |
官方测试用例
| 序号 | 输入 | 输出 |
|---|---|---|
| 1 | 1 | 1 |
| 2 | 2 | 1 |
| 3 | 10 | 55 |
| 4 | 55 | 2091 |
| 5 | 100 | 6545 |
| 6 | 500 | 8907 |
| 7 | 999 | 4659 |
| 8 | 9999 | 9973 |
| 9 | 99999 | 6415 |
| 10 | 999999 | 3131 |
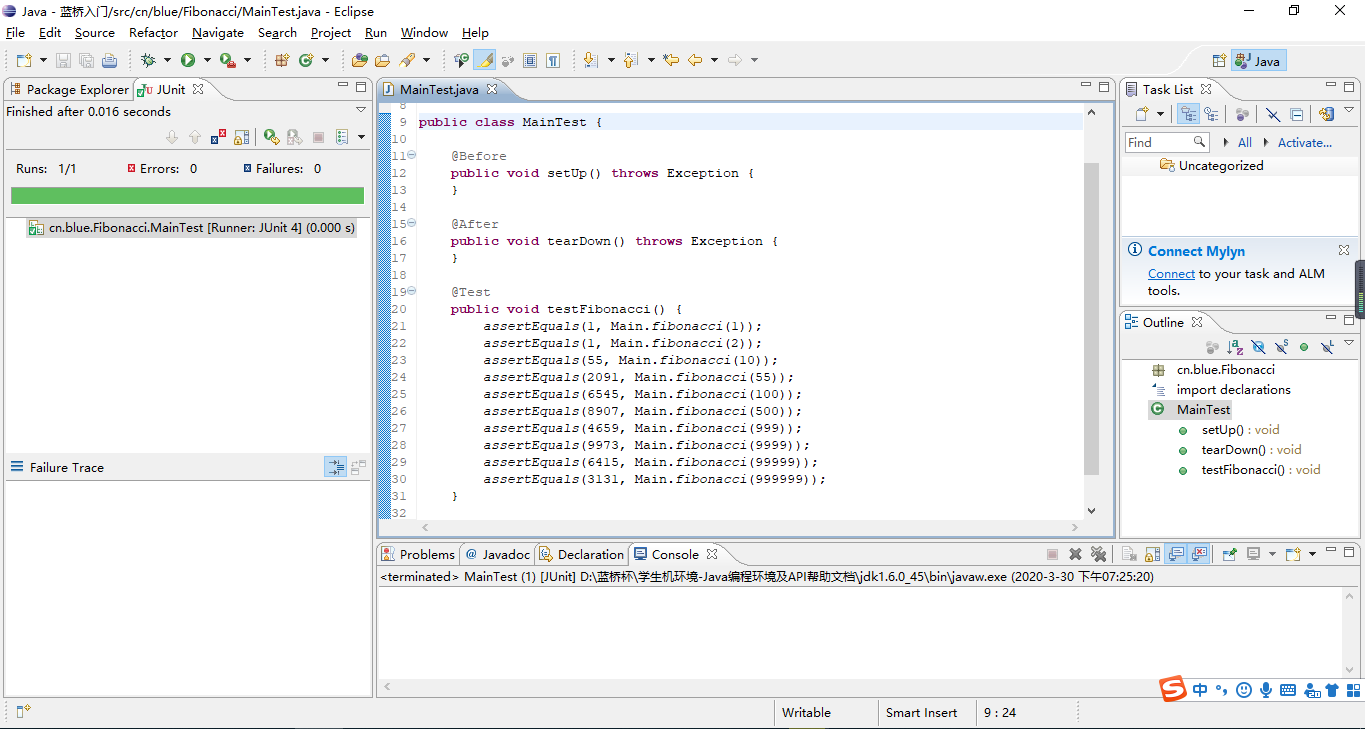
以上便是此篇需要达到了目的,收集汇总蓝桥官方的测试用例,对数据进行处理后,再使用Junit进行单元测试。
减去人工操作过程中繁杂的重复输入数据的过程。
分析
遇到问题
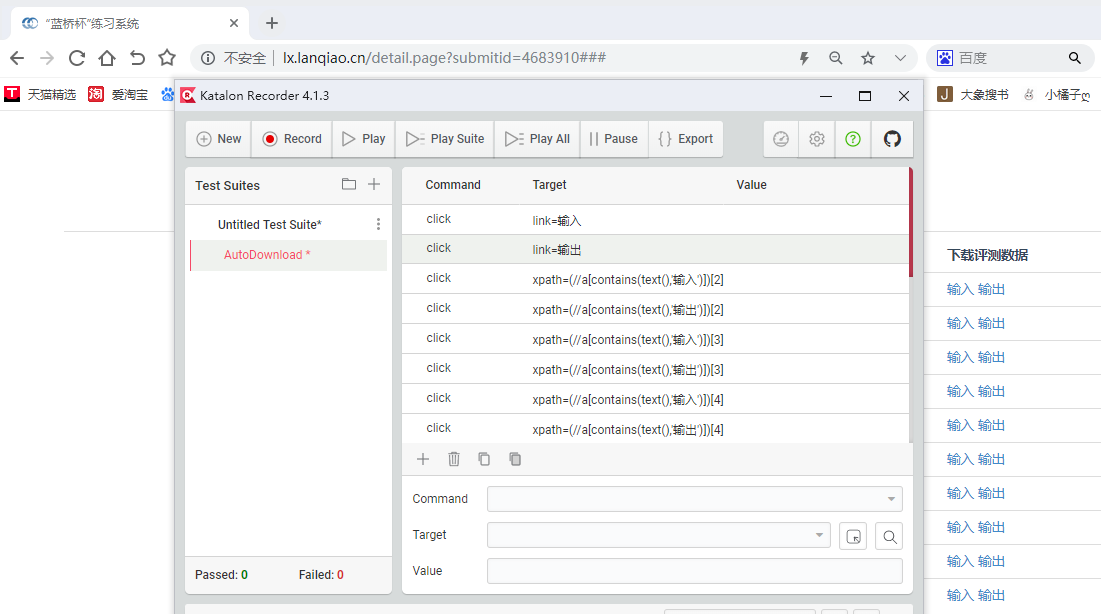
蓝桥杯的练习系统评测页面
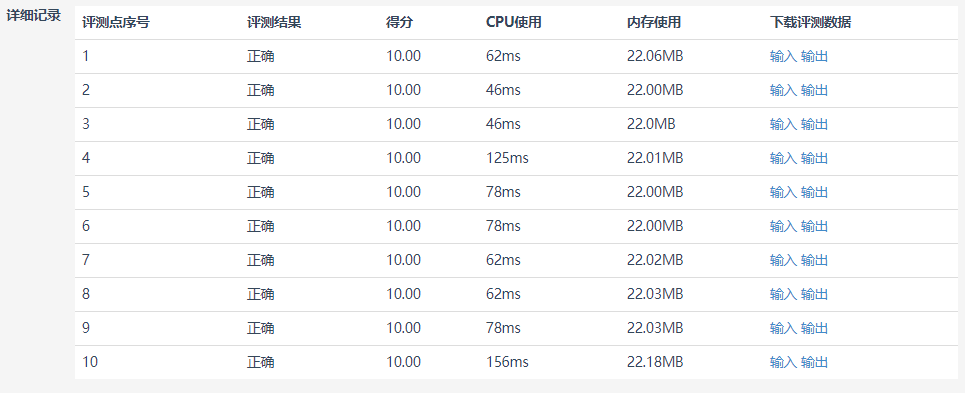
看!右侧下载评测数据属性下,有众多蓝色可点击文字,每次点击输入/输出就会下载一个txt文件。
逐个点击得到如下图:
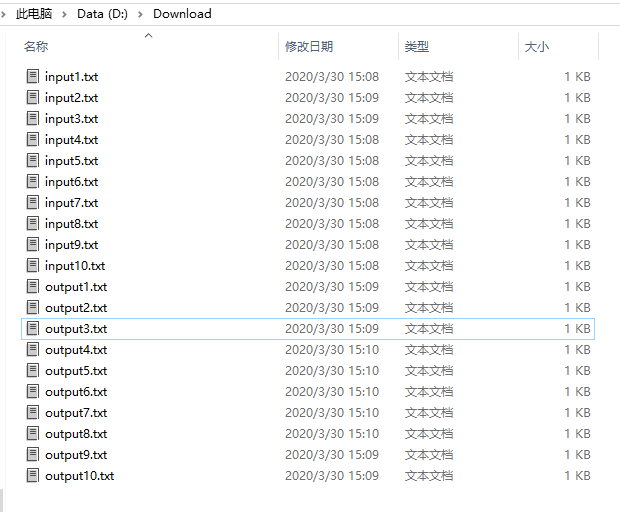
得到20个txt文件!更麻烦的是还需要打开20个txt文件,重复的进行 Ctrl + C / Ctrl + V 操作
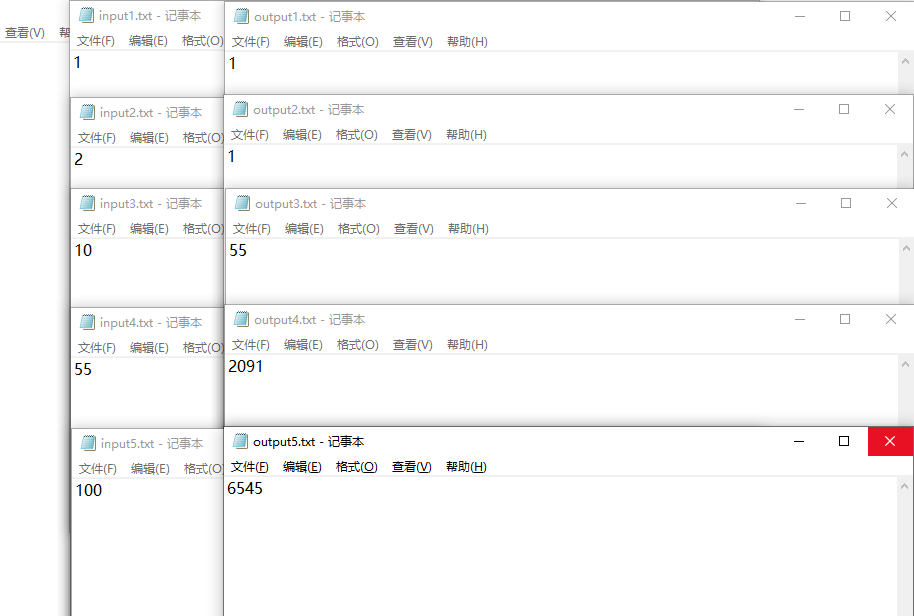
这工作量似乎有点震惊到了博主本人。
不行!得想办法将这些工作自动化!身为计算机学子,怎么能受这点困难打倒?
解决思路
刚学完的Selenium IDE和 Katalon Recorder可以派上用场了。
首先来到评测页面,打开录制脚本的功能,操作一遍,逐个点击下载txt文件,停止降本录制。
这时候回放就可以看到自动化测试工具在自行下载所有测试用例的输入输出了。
拿到20个txt文件之后,需要用java实现合并这20个txt文件的功能。
同时还想在合并过程中读取数据并拼接字符串提供给Junit测试使用。
实际操作
工具
浏览器: 火狐浏览器 版本 74.0
插件: Katalon Recorder V4.1.3
开发工具:Eclipse 3.6.2版本,JDK 1.6.0_45版本
后续:Eclipse 4.15.0版本,JDK 1.8版本
操作
打开 Chrome浏览器 登陆到蓝桥练习系统,进入评测页面,启动 Katalon Recorder 录制脚本。
这就得到了自动下载的脚本。
注意注意:本人试了一下,直接运行,崩了!直接封号处理...
由于脚本的执行速度过快!点击Play的瞬间就完成了20个下载点击操作!
Oh no没有考虑到反爬虫机制,知识盲区。号没了还可以再借(因为同班好多同学参加蓝桥杯)
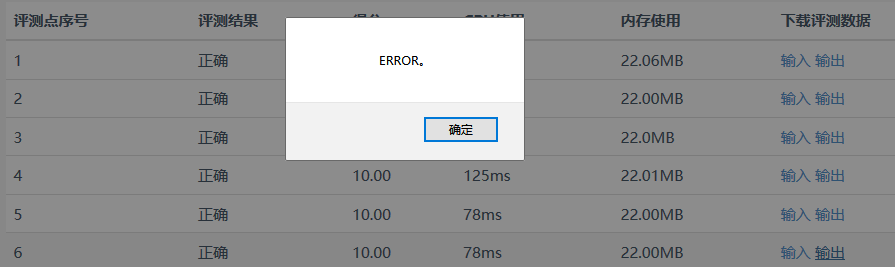
改进
遇到问题继续查资料,注意到 Katalon Recorder 界面是有自行编写命令的区域。
立刻查询Katalon Recorder 有没有sleep pause等命令,结果无功而返。
既然插件命令不熟悉,那么导出的脚本是java代码,总可以用sleep了吧。
导出的脚本源代码
package com.example.tests;
import java.util.regex.Pattern;
import java.util.concurrent.TimeUnit;
import org.junit.*;
import static org.junit.Assert.*;
import static org.hamcrest.CoreMatchers.*;
import org.openqa.selenium.*;
import org.openqa.selenium.firefox.FirefoxDriver;
import org.openqa.selenium.support.ui.Select;
public class AutoDownload {
private WebDriver driver;
private String baseUrl;
private boolean acceptNextAlert = true;
private StringBuffer verificationErrors = new StringBuffer();
@Before
public void setUp() throws Exception {
driver = new FirefoxDriver();
baseUrl = "https://www.google.com/";
driver.manage().timeouts().implicitlyWait(30, TimeUnit.SECONDS);
}
@Test
public void testAutoDownload() throws Exception {
driver.findElement(By.linkText("输入")).click();
driver.findElement(By.linkText("输出")).click();
driver.findElement(By.xpath("(//a[contains(text(),'输入')])[2]")).click();
driver.findElement(By.xpath("(//a[contains(text(),'输出')])[2]")).click();
driver.findElement(By.xpath("(//a[contains(text(),'输入')])[3]")).click();
driver.findElement(By.xpath("(//a[contains(text(),'输出')])[3]")).click();
driver.findElement(By.xpath("(//a[contains(text(),'输入')])[4]")).click();
driver.findElement(By.xpath("(//a[contains(text(),'输出')])[4]")).click();
driver.findElement(By.xpath("(//a[contains(text(),'输入')])[5]")).click();
driver.findElement(By.xpath("(//a[contains(text(),'输出')])[5]")).click();
driver.findElement(By.xpath("(//a[contains(text(),'输入')])[6]")).click();
driver.findElement(By.xpath("(//a[contains(text(),'输出')])[6]")).click();
driver.findElement(By.xpath("(//a[contains(text(),'输入')])[7]")).click();
driver.findElement(By.xpath("(//a[contains(text(),'输出')])[7]")).click();
driver.findElement(By.xpath("(//a[contains(text(),'输入')])[8]")).click();
driver.findElement(By.xpath("(//a[contains(text(),'输出')])[8]")).click();
driver.findElement(By.xpath("(//a[contains(text(),'输入')])[9]")).click();
driver.findElement(By.xpath("(//a[contains(text(),'输出')])[9]")).click();
driver.findElement(By.xpath("(//a[contains(text(),'输入')])[10]")).click();
driver.findElement(By.xpath("(//a[contains(text(),'输出')])[10]")).click();
}
@After
public void tearDown() throws Exception {
driver.quit();
String verificationErrorString = verificationErrors.toString();
if (!"".equals(verificationErrorString)) {
fail(verificationErrorString);
}
}
private boolean isElementPresent(By by) {
try {
driver.findElement(by);
return true;
} catch (NoSuchElementException e) {
return false;
}
}
private boolean isAlertPresent() {
try {
driver.switchTo().alert();
return true;
} catch (NoAlertPresentException e) {
return false;
}
}
private String closeAlertAndGetItsText() {
try {
Alert alert = driver.switchTo().alert();
String alertText = alert.getText();
if (acceptNextAlert) {
alert.accept();
} else {
alert.dismiss();
}
return alertText;
} finally {
acceptNextAlert = true;
}
}
}
直接拷贝脚本到eclipse,再导入一些外部jar包,准备好浏览器驱动。
selenium相关包下载: http://www.seleniumhq.org/download/
浏览器驱动下载: https://github.com/mozilla/geckodriver/releases
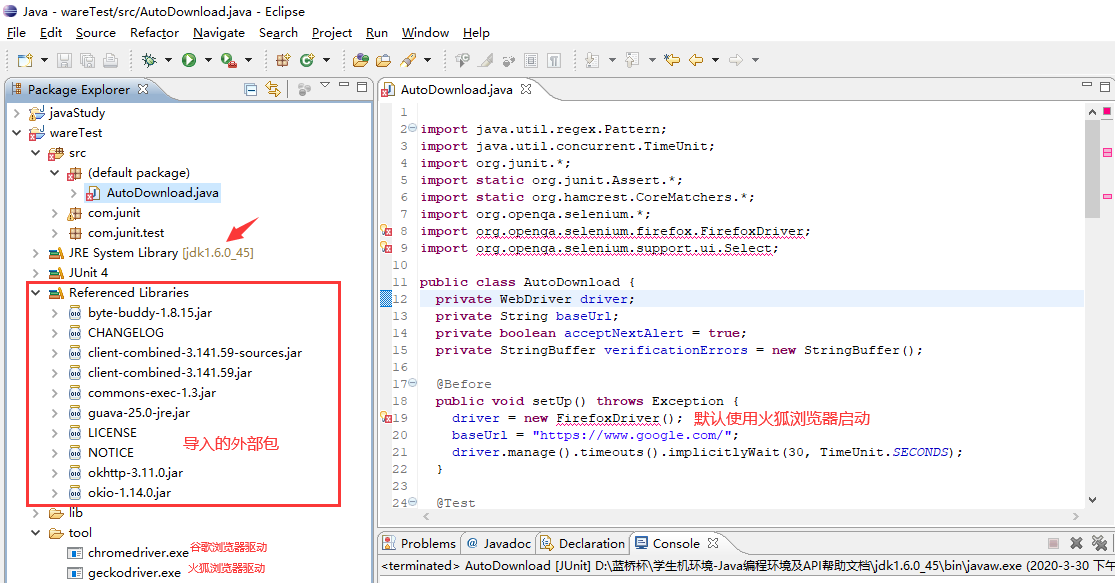
从这里开始各种错误信息,查看了好多版本兼容问题。
有个报错显示最低要求jdk版本1.8。然而这蓝桥杯专用的eclipse换高版本jdk就不行。
索性载了个最新版的Eclipse 4.15.0版本 配置JDK 1.8
再将项目迁移到新的Eclipse,注意安装好配置环境。提前查看各工具间的版本兼容问题。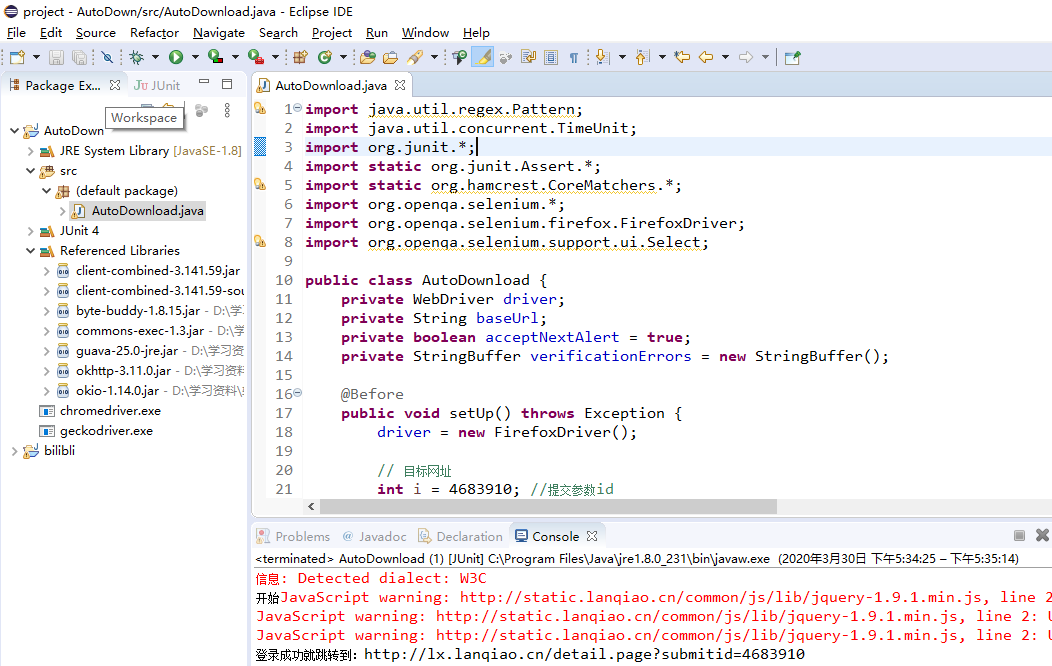
经过修修补补终于改出需要功能的代码
import java.util.regex.Pattern;
import java.util.concurrent.TimeUnit;
import org.junit.*;
import static org.junit.Assert.*;
import static org.hamcrest.CoreMatchers.*;
import org.openqa.selenium.*;
import org.openqa.selenium.firefox.FirefoxDriver;
import org.openqa.selenium.support.ui.Select;
public class AutoDownload {
private WebDriver driver;
private String baseUrl;
private boolean acceptNextAlert = true;
private StringBuffer verificationErrors = new StringBuffer();
@Before
public void setUp() throws Exception {
driver = new FirefoxDriver();
// 目标网址
int i = 4694494; //提交参数id
baseUrl = "http://lx.lanqiao.cn/detail.page?submitid="+i;
driver.manage().timeouts().implicitlyWait(30, TimeUnit.SECONDS);
}
@Test
public void testAutoDownload() throws Exception {
System.out.print("开始");
driver.get("http://lx.lanqiao.cn/");
int n = 2;
Thread.sleep(1000 * n); // 休眠n秒
driver.findElement(By.id("xloginbtn")).click();
Thread.sleep(500 * n); // 休眠n秒
driver.findElement(By.xpath("//a[@id='btnShowLoginDialog']/p[3]")).click();
Thread.sleep(1000 * n); // 休眠n秒
driver.findElement(By.xpath("//input[@type='text']")).click();
Thread.sleep(1000 * n); // 休眠n秒
WebElement e= driver.findElement(By.xpath("/html/body/div/div/div[1]/div[2]/div/div[1]/div/div[3]/div[1]/form/div[1]/div/div/span/input"));
e.clear();
e.sendKeys("123456");//这里输入自己的账号
Thread.sleep(1000 * n); // 休眠n秒
e= driver.findElement(By.xpath("/html/body/div/div/div[1]/div[2]/div/div[1]/div/div[3]/div[1]/form/div[2]/div/div/span/input"));
e.sendKeys("123");//这里输入自己的密码
Thread.sleep(1000 * n); // 休眠n秒
// driver.find_element_by_id('p').send_keys('*********')
driver.findElement(By.xpath("//button[@type='button']")).click();
Thread.sleep(1000 * n); // 休眠n秒
driver.findElement(By.linkText("评测记录")).click();
Thread.sleep(1000 * n); // 休眠n秒
System.out.println("登录成功就跳转到:"+baseUrl); //从这里开始操作下载内容
Thread.sleep(1000 * n); // 休眠n秒
Thread.sleep(1000 * n); // 休眠n秒
driver.findElement(By.linkText("输入")).click();
Thread.sleep(1000 * n); // 休眠n秒
driver.findElement(By.linkText("输出")).click();
Thread.sleep(1000 * n); // 休眠n秒
driver.findElement(By.xpath("(//a[contains(text(),'输入')])[2]")).click();Thread.sleep(1000 * n); // 休眠n秒
driver.findElement(By.xpath("(//a[contains(text(),'输出')])[2]")).click();Thread.sleep(1000 * n); // 休眠n秒
driver.findElement(By.xpath("(//a[contains(text(),'输入')])[3]")).click();Thread.sleep(1000 * n); // 休眠n秒
driver.findElement(By.xpath("(//a[contains(text(),'输出')])[3]")).click();Thread.sleep(1000 * n); // 休眠n秒
driver.findElement(By.xpath("(//a[contains(text(),'输入')])[4]")).click();Thread.sleep(1000 * n); // 休眠n秒
driver.findElement(By.xpath("(//a[contains(text(),'输出')])[4]")).click();Thread.sleep(1000 * n); // 休眠n秒
driver.findElement(By.xpath("(//a[contains(text(),'输入')])[5]")).click();Thread.sleep(1000 * n); // 休眠n秒
driver.findElement(By.xpath("(//a[contains(text(),'输出')])[5]")).click();Thread.sleep(1000 * n); // 休眠n秒
driver.findElement(By.xpath("(//a[contains(text(),'输入')])[6]")).click();Thread.sleep(1000 * n); // 休眠n秒
driver.findElement(By.xpath("(//a[contains(text(),'输出')])[6]")).click();Thread.sleep(1000 * n); // 休眠n秒
driver.findElement(By.xpath("(//a[contains(text(),'输入')])[7]")).click();Thread.sleep(1000 * n); // 休眠n秒
driver.findElement(By.xpath("(//a[contains(text(),'输出')])[7]")).click();Thread.sleep(1000 * n); // 休眠n秒
driver.findElement(By.xpath("(//a[contains(text(),'输入')])[8]")).click();Thread.sleep(1000 * n); // 休眠n秒
driver.findElement(By.xpath("(//a[contains(text(),'输出')])[8]")).click();Thread.sleep(1000 * n); // 休眠n秒
driver.findElement(By.xpath("(//a[contains(text(),'输入')])[9]")).click();Thread.sleep(1000 * n); // 休眠n秒
driver.findElement(By.xpath("(//a[contains(text(),'输出')])[9]")).click();Thread.sleep(1000 * n); // 休眠n秒
driver.findElement(By.xpath("(//a[contains(text(),'输入')])[10]")).click();Thread.sleep(1000 * n); // 休眠n秒
driver.findElement(By.xpath("(//a[contains(text(),'输出')])[10]")).click();Thread.sleep(1000 * n); // 休眠n秒
}
@After
public void tearDown() throws Exception {
driver.quit();
String verificationErrorString = verificationErrors.toString();
if (!"".equals(verificationErrorString)) {
fail(verificationErrorString);
}
}
private boolean isElementPresent(By by) {
try {
driver.findElement(by);
return true;
} catch (NoSuchElementException e) {
return false;
}
}
private boolean isAlertPresent() {
try {
driver.switchTo().alert();
return true;
} catch (NoAlertPresentException e) {
return false;
}
}
private String closeAlertAndGetItsText() {
try {
Alert alert = driver.switchTo().alert();
String alertText = alert.getText();
if (acceptNextAlert) {
alert.accept();
} else {
alert.dismiss();
}
return alertText;
} finally {
acceptNextAlert = true;
}
}
}
好了!成功拿到大量数据。
数据处理
看着20个txt文件都头疼,赶紧复习一下java的File类 和 IO流
其实知道以上两个知识点后还是很简单滴。一轮for遍历1到10
拼接文件名 input i output i ,读取他们的内容写入一个总的txt文件内。
源码
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException;
import java.util.Arrays;
public class Collect {
public static void main(String args[]) throws IOException {
collect();
}
public static void collect() throws IOException{
FileOutputStream fos = new FileOutputStream("D:\Download\all.txt");
for(int i=1;i<=10;i++){
FileInputStream fis = new FileInputStream("D:\Download\input"+i+".txt");
int len = 0;
byte[] bytes = new byte[1024];
while((len = fis.read(bytes))!= -1){
fos.write(bytes,0,len-2);
}
fos.write(" ".getBytes());
fis.close();
fis = new FileInputStream("D:\Download\output"+i+".txt");
len = 0;
while((len = fis.read(bytes))!= -1){
fos.write(bytes,0,len);
}
//fos.write("
".getBytes());
fis.close();
}
fos.close();
System.out.print("汇总完成");
}
}
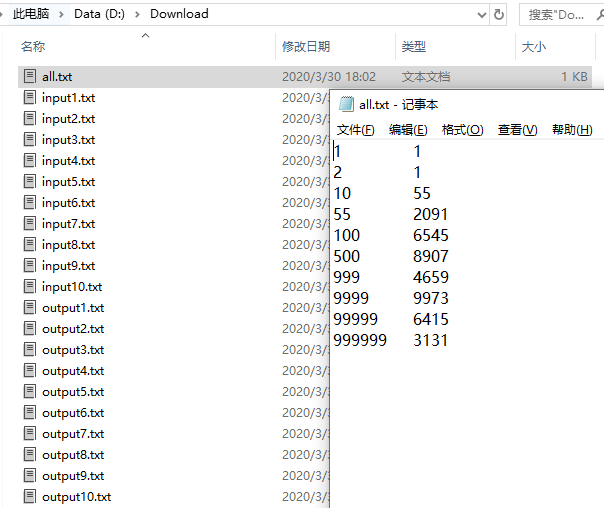
得到一个汇总数据,这时候还要填到Typora的表格内,似乎也有点小麻烦...
难道,要动用excel表格吗?是的!没错。虽然没试过java与excel的联动,但是知道txt和excel是可以自动转换的。
先解决测试类的断言批量代码。
assertEquals(1, Main.fibonacci(1)); ——>assertEquals( a , function ( b ));
就是利用字符串拼接把数据部分替换成all.txt的每一行数据。
上源码:
import java.io.BufferedReader;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.InputStreamReader;
import java.util.Arrays;
import java.util.Scanner;
public class Copy {
public static void main(String args[]) throws IOException {
Scanner sc = new Scanner(System.in);
String func_name = sc.nextLine();
cpoy(func_name);
}
public static void cpoy(String func) throws IOException {
BufferedReader br = new BufferedReader(new InputStreamReader(
new FileInputStream("D:\Download\all.txt")));
FileOutputStream fos = new FileOutputStream("D:\Download\code.txt");
String str = "";
String linestr;// 按行读取
while ((linestr = br.readLine()) != null) {
String[] data = linestr.split(" ");// 按Tab键分割
str = "assertEquals(" + data[0] + ", " + func + "(" + data[1]
+ "));"+"
";
System.out.print(str);
fos.write(str.getBytes());
}
fos.close();
}
}
代码解释:
首先要输入一个函数名。
比如此处调用的静态方法就斐波那契数列模10007,输入 Main.fibonacci 。得到code.txt
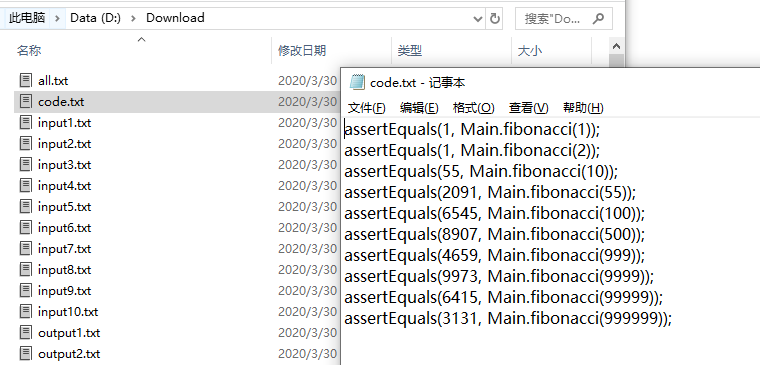
注意注意,断言的第一个值是预测结果。所以code.txt 的数据看起来与 all.txt 相反。
最后
首先在Download文件夹下新建一个excel文档 ——> 双击打开——>填入如下模板
其次双击打开all.txt文件——> Ctrl A 全选 ——> Ctrl C 复制 ——> 切换到excel文档 ——> 点击B2位置(如上图)——>Ctrl V 粘贴
得到下图
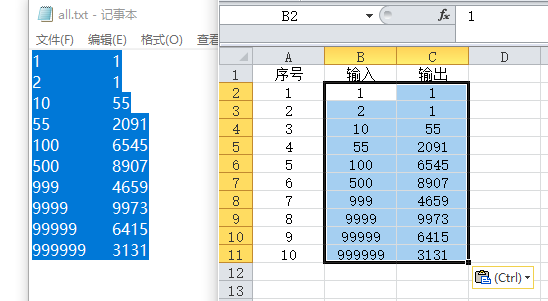
最后 Ctrl A 全选 ——> Ctrl C 复制——>切换到Typora ——>Ctrl V 粘贴
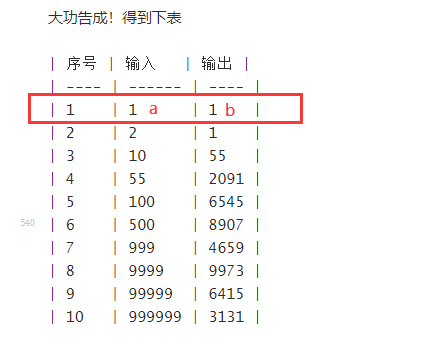
大功告成!得到下表
| 序号 | 输入 | 输出 |
|---|---|---|
| 1 | 1 | 1 |
| 2 | 2 | 1 |
| 3 | 10 | 55 |
| 4 | 55 | 2091 |
| 5 | 100 | 6545 |
| 6 | 500 | 8907 |
| 7 | 999 | 4659 |
| 8 | 9999 | 9973 |
| 9 | 99999 | 6415 |
| 10 | 999999 | 3131 |
Junit快速创建
选中斐波那契数列的Main函数右击 New ——> JUnit Test Case——>Next
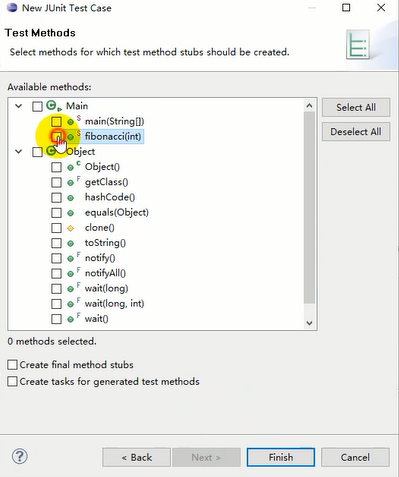
勾选需要测试的方法——>Finish
把code.txt的全部代码拷贝替换下面这句代码。
右键运行
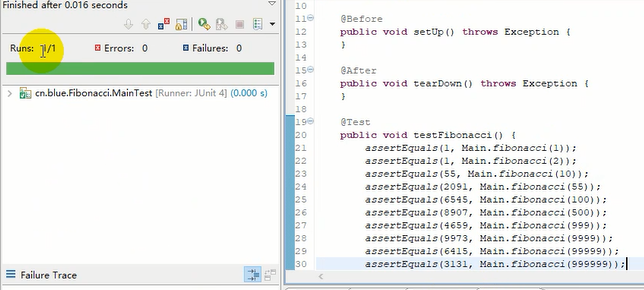
绿色!测试通过。任务完成!
总结
一路下来遇到的困难一个又一个,本来想得很简单的东西,实际操作起来又遇到新的问题。
有些困难是真的让人着急,比如将脚本代码放到老eclipse跑的时候,一堆看不懂的报错。查了知道是jdk版本过低。
还想办法更换老eclipse的编译环境,弄了好久好久。也不知道换没换成,反正就是没有报错也启动不了浏览器。
还在网上比对各个工具的版本是否配对。版本兼容性问题真是不容小视!
还有快完成任务的时候突发奇想,既然测试类的断言代码可以用java生成,那么Typora的表格也是符合markdown语法的。
可以先套个模板再更改里面的数据,保存到某个.md文件下。直接生成表格,再copy过来就ok了。
最后发现了自己的java基础还是不够强,File类 String类 都还需要去看官方文档才记得方法怎么用,有待加强!
通向罗马的路不止一条,这条走不通就换另一条。后面意外发现selenium有脚本执行速度的功能!
之后就直接在selenium运行自动下载的脚本了。