 第三单元规格作业博客总结
第三单元规格作业博客总结
规格
什么是规格?
对一个方法/类/程序/外部可感知的行为语义的抽象表示,避免了内部细节的宏观表现,把设计与实现有效的分离。
表示方法:JML语言
方法规格抽象:
-
前置条件规定了方法的调用者行为:即如果你要调用这个方法,那么就必须按照我给你的说明输入相应的参数,否则,程序无法运行我不背锅。
-
后置条件是方法履行的承诺,如果调用者按照我给定的规格进行了输入,那么我就应该将他的输入正确处理,返回调用者预期的成果。
JML的工具链:openJML
http://www.eecs.ucf.edu/~leavens/JML/index.shtml
基于JUNIT框架进行测试
第一步:初始时刻,写了一个Demo,准备用JUNIT自动生成测试用例:

第二步:用命令生成测试文件*.java如下图所示。
java -jar jmlunitng.jar srcDemo.java
第三步:编译src目录下所有的.java文件。完成之后,src目录之下会有所有的java文件生成的.class文件。其中最重要的是名为:Demo_JML_Test.class的文件
qi'zhjavac -cp jmlunitng.jar src*.java
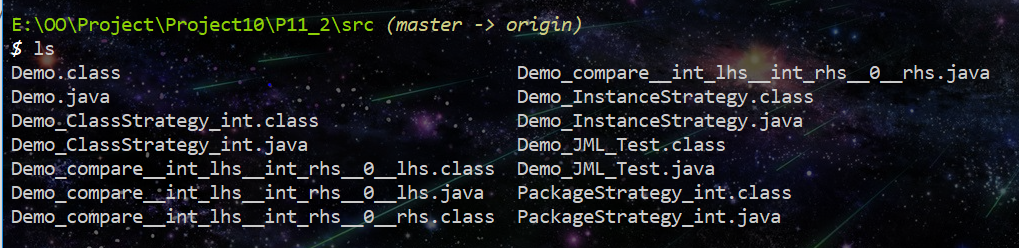
第四步:运行我们在第三步产生的Demo_JML_Test.class。产生的结果如下图所示。
java -cp jmlunitng.jar Demo_JML_Test

(测试结果的第一行是 racEnabled 的测试,意在检测我们的主文件是否带有 JML 的运行时检查,若没有则跳过所有测试。由于我在进行测试的时候,只使用了jmlunitng.jar这一个第三方包,所以它是不包含运行时检查的插件的,因此第一个点会出现fail的情况)
可以看到,JMLUNIT自动生成的测试文件特征十分明显,就是“取边界数据”,int的上下界和0(正负数的边界)是JMLUNIT测试的重点,笔者在第一次作业中采用的是直接相减的结果作为返回值,此时会有整数相加减溢出的情况;因为当时还没有琢磨出jmlunit的使用,所以强测直接GG了。
另外需要说明的是,感觉jmlunitng.jar这个包的使用十分受限,它只能对一些简单jml规格进行判断,自动生成数据,稍微复杂一点的数据它便无能为力,所以个人感觉,它带来的作用其实不及同学们自己构造测试用例,再所以…别偷懒。
看另一个例子:
这是待测试代码:
public class Demo {
private int flag;
/*
@ public normal_behavior
@ requires obj != null && obj instanceof Path;
@ assignable
othing;
@ ensures
esult == (((Demo) obj).flag == this.flag)
@ also
@ public normal_behavior
@ requires obj == null || !(obj instanceof Demo);
@ assignable
othing;
@ ensures
esult == false;
@*/
public boolean equals(Object obj) {
if(this == obj){
return true;
}else if(!(obj instanceof Demo)){
return false;
}else {
Demo d1 = (Demo) obj;
return d1.flag == this.flag;
}
}
}
JMLUNITNG生成的测试用例如下:
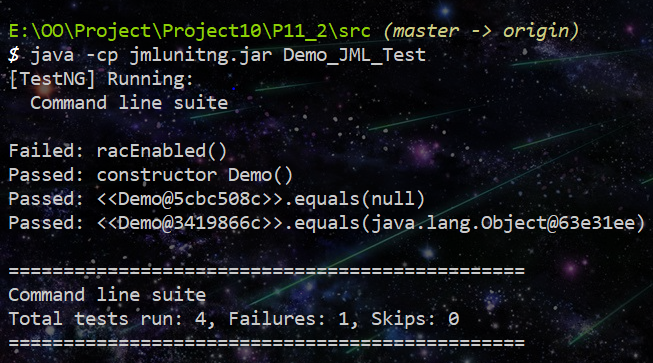
我们发现测试用例真的十分简单,并且对类型实例无法显示正确的对象属性。但是从以上两个例子可以看出jmlunitng的最大特点是构造边界数据,比如此处的空指针,上一个例子中的int的上下界。从这个意义上看来,JMLUNITNG的作用挺关键的。
第一次作业
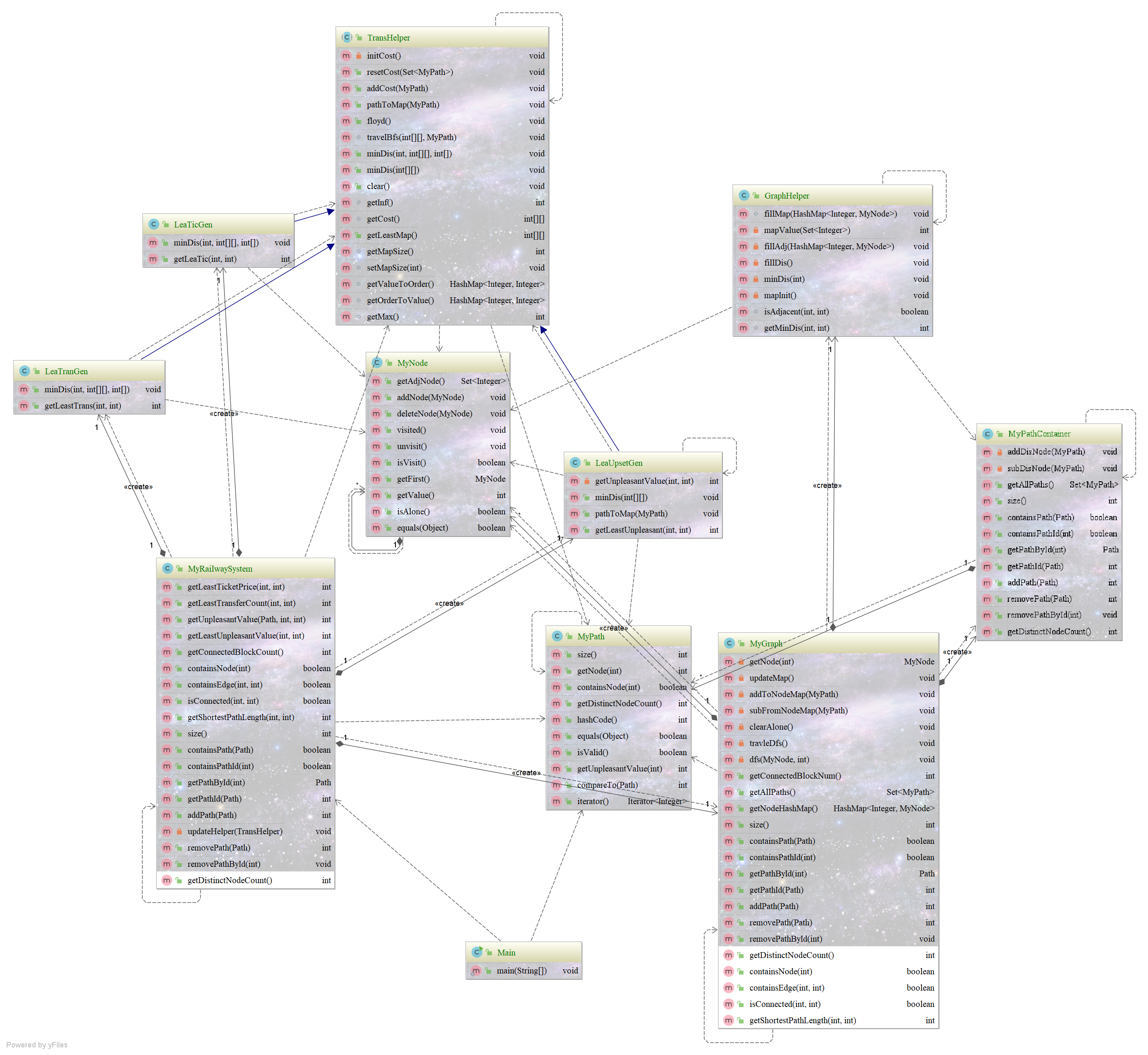
第一次作业主要是考察同学们阅读JML代码的能力,规格说明已经为我们设计好一个方法的实现效果,并且设置了前置条件、后置条件以及副作用,同学们只需要严格的按照JML的说明进行编码,则正确性可以保证,时间的开销问题主要集中在查询不同节点上,我们可以新建一个数据容器来管理不同的结点数,将时间复杂度分散到路径变更指令上。
UML类图

架构设计:
-
MyPath作为一个数据管理类,管理着该条PATH上的结点,我所采用的数据结构是利用一个ArrayList并且初始化为相应的路径长度(依据指导书的规定而设计),这样可以避免在List长度不够,在内存中开辟新空间带来的时间开销。并且,使用ArrayList好处有以下几点:
-
List自带迭代器模式,所以在为PATH适配迭代器接口的时候,就可以直接使用Arraylist的迭代器。
-
可以向数组一样直接通过下标访问容器内的元素。
-
MyPathContainer作为更高层次的数据管理类,管理着多条PATH,我为其设置了三个HASHMAP分别用来保存路径号到路径、路径到路径号、不同的结点到使用次数的映射。PATH的增删查改操作都是建立在这三个MAP之上的,利用hashmap带来的好处就是,查询的复杂度可降为O(1),大大缩减了时间复杂度。
-
MyNode是我自己构建的一个邻接表结构,主要是保存了一个结点的所有相邻结点,之后的并查集染色中用到。
bug分析
一个需要注意的点:OVERFLOW
在实现比较器接口的时候,为了偷懒,我采取了如下方式:
@Override
public int compareTo(Path o) {
MyPath myPath = (MyPath) o;
for (int i = 0; i < Math.min(myPath.size(), this.size()); i++) {
if (nodes.get(i) != myPath.getNode(i)) {
return nodes.get(i) - myPath.getNode(i);
}
}
return this.size() - myPath.size();
}
此时,两个整型变量相减的时候会发生算术溢出,但系统不会抛出异常,导致的结果就是——强测60…GG。究其原因,大一学C语言的时候没好好学,基础没有打牢,导致编码经验不足,连最基本的算术溢出也没有考虑到。
后来将比较部分换乘if-else语句,顺利修复了bug。
第二次作业
第二次作业在第一次作业的基础之上,添加了判断是否存在某个结点,两个节点之间是否存在边,两个结点是否连通。很明显,题目的发展正在朝图(GRAPH)的方向发展。
UML类图

架构设计:
新建了一个类:MyGraph包含了一个PathContainer对象和GraphHelper对象,以及自身管理者一个结点值映射到结点的Hashmap。此时,再添加路径的时候,我采用了组合模式的设计思想,每次添加路径的时候,MyPathContainer也要添加相应的路径。适配了相应的方法来调整自身的属性,如:添加结点和删除结点。
GraphHelper:这个类主要是用来处理两个问题:最短路径和邻接问题。在这个类中我维护了两个矩阵:邻接矩阵和距离矩阵,距离矩阵是由邻接矩阵生成的。由于第二次作业涉及到的tu都是无向图,所以,我采用了bfs的方式遍历图。
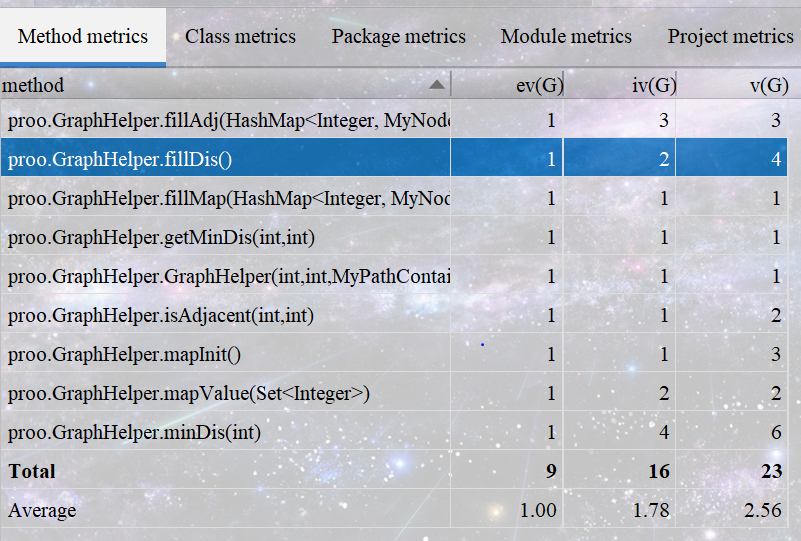
程序的圈复杂度和结构依赖度都保持在较低的水平:
程序bug分析:
在构建图的时候,在PATH_ADD的方法中,忘记考虑了路径已经存在于图中的情况,导致同一条路径有可能重复添加到数据管理容器中,这是一个致命失误。主要原因是对JML规格的理解出现了遗漏。
修复情况:添加了去掉重复的判断。
第三次作业
第三次作业在第二次的基础之上引入了换乘的概念,导致作业的难度大大增加。
UML类图
换乘
P11中多个接口涉及换乘的概念:至少涉及两条路径才叫换乘。比如:从沙河校区到学院路校区,经过沙河的地铁线路只有13号线,而学院路校区靠近知春路(13/10号线)地铁站和西土城(10号线)地铁站,所以我们需要找到一个换乘站(西二旗)进行路线的更换才能到达学院路校区。
构造相应的中间数据来表达换乘:
在此感谢要感谢wjy大佬在讨论区分享的算法:
-
权重:可以是:换乘次数/最少票价/最少不满意度
-
位于一条Path上的点,是不需要换乘的,所以,在新添加一条路径的时候,基于该路径利用最短路径算法(floyd/Dijkstra)进行操作,此时得到的图是不包含换乘信息的;然后,将Path生成的图合并到大图中(合并:如果小图两结点间的权重小于大图,那么用较小的权重代替较大的权重)。
在此提取最短票价的初始化path的小图部分代码。
if (pathMap[w][start] + 2 < getCost()[w][start]) {
// w和start为两个换乘点
getCost()[w][start] = pathMap[w][start] + 2;
getCost()[start][w] = pathMap[w][start] + 2;
} -
构造前,使用hashMap把int范围内的整数映射到0-120这个范围内;在构造PATH小图和GRAPH大图的时候要注意结点值与数组索引下标的一一对应关系。
-
对大图使用一次最短路径算法就可以得到包装的信息,在取用的时候减去换乘代价就是真实的信息。
架构设计:
为了处理换乘问题,我采用了工厂模式,分别生产负责最小换乘代价、最小不满意度和最小票价的矩阵。
三个问题看似不同,但是可以进行同一的处理:
初始化矩阵:最小换乘代价把一条PATH中所有的结点之间的权重设为1;最小票价矩阵把一条PATH中所有结点间的权重设置为路径长度加上换乘代价2;最小不满意度矩阵把一条PATH中相应的点间的权重设置为这两点间的权重加上换乘代价32。
利用最短路径算法对生成的图进行处理,即可得到包含换乘信息的图。
程序的bug:
终于强测满分了。
设计模式:
适配器模式:
Path继承了迭代器接口和比较器接口,所以必须为该类配置相应的方法来实现这一功能。
观察者模式:
在本次作业中的应用,每次添加路径之后,如果需要查询图,那么更新保存图信息的矩阵。
组合模式:
PathContainer作为Graph的组成部分,Graph作为RailWaySystem的组成部分。这样大大减少了代码重构带来的时间开销和bug隐患。
工厂模式:
三个“最少”矩阵,可以利用三个工厂来进行生产。
装饰器模式:
面对新需求,使用装饰器模式为原来的类增加相应的方法。
思想与体会
-
代码规范化
正所谓磨刀不误砍柴工,提前将类职责和方法指责规定好,对于全局而言,实际上并不降低效率。
这一单元的第一次作业可能是我写的最轻松的一次作业,因为有了课程组提供的规格,那么我们只需要提供一个方法的具体实现即可,这让我更深刻的体会到面向对象和面向接口编程带来的优越感。
-
规格的主体性
所谓主体性就是规格对于不同的对象有着不同的作用,对于用户(客户)来说,规格就像一封说明书,如果按照正确的方式使用这段程序,那么就可以得到正确的结果。此时,用户并不关心该程序的内部的具体实现,他们关心的往往是程序结果的正确性和产生结果的效率。时间效率在这次作业中有着明显的体现,为了降低时间开销,是不能暴力遍历所有路径求出最小值的,而应该先将所有信息计算出来,整合到一个缓存中,用户每次查询只从缓存中查找,这样很大程度上降低了计算的时间。
对于开发人员来说,规格就像一封承诺书,因为我们需要按照规格指定的输入返回可靠的结果。开发人员必须保证程序的正确性。在这一单元中,我所采用的测试方法为:
-
利用JUNIT对方法的正确性进行精确计算,考虑合法与非法的情况,考虑成环或者直线的情况,考虑各种不相交的情况……
-
与其他人写的程序进行“对拍”,其实这次程序的对拍是很好实现的,只要拥有了大量的数据,对拍起来相当容易;在第二次作业中,我在与同学对拍的过程中发现了自己add和remove方法上的漏洞;在第三次对拍中,我发现自己程序的运行时间过长然后进行了算法的优化。
-
-
利用已有的算法来保证正确性。
许多最短路径算法都是经过几代人开发总结出来的算法,算法的正确性是可以得到保证的,在这次作业中,我们需要做的仅仅是考虑如何将这些算法融入到我们的架构中,来提高程序的性能。在这次作业中我发现,主流的做法主要分为两种,一种是“拆点做法”,另一种是wjy同学提供的“wjy算法”
(姑且这么叫吧)