这几天一个叫做"Dirty COW"的linux内核竞争条件漏洞蛮火的,相关公司不但给这个漏洞起了个洋气的名字,还给它设计了logo(见下图),首页,Twitter账号以及网店。恰逢周末,闲来无事的我也强势围观了一波,在这之前,好好的学习了一下竞争条件以及看了一下近几年关于竞争条件漏洞。

1:什么是竞争条件以及竞争条件为什么会产生漏洞
竞争条件是系统中的一种反常现象,由于现代Linux系统中大量使用并发编程,对资源进行共享,如果产生错误的访问模式,便可能产生内存泄露,系统崩溃,数据破坏,甚至安全问题。竞争条件漏洞就是多个进程访问同一资源时产生的时间或者序列的冲突,并利用这个冲突来对系统进行攻击。一个看起来无害的程序如果被恶意攻击者利用,将发生竞争条件漏洞。
用简单代码讲的更清楚:
//myThreadTest
#include <stdio.h> #include <pthread.h> #include <unistd.h> int i = 1; void *mythread1() { if(i == 1){ <a> sleep(3); if(i == 2) <b> printf("hack it! "); else printf("you can try again! "); } } void *mythread2() { sleep(1); i=2; } int main(int argc, const char *argv[]) { pthread_t id1,id2; pthread_create(&id1, NULL, (void *)mythread1,NULL); pthread_create(&id2, NULL, (void *)mythread2,NULL); pthread_join(id1,NULL); pthread_join(id2,NULL); return 0;
}
单独看mythread1()函数,显然肯定是输出 "you can try again! ",但是,由于i是全局共享的资源可以通过线程的方式来使i值在<a>的之后<b>之前进行改变,可以改变函数的流程

为了使结果清晰明了,所以手动利用sleep()函数进行设置了,实际利用过程中,可能是一些会耗时较长的函数,如memcpy()
流程如下:

这也是竞争条件的核心思想,这也是一个数据竞争引发条件竞争的典型例子。
2:以cve-2014-0496为例
由于Android的崛起起,Linux内核的安全性受到了极大地考验,很多潜藏的安全也慢慢被安全研究眼发现。这个漏洞的主要成因是因为在pty/tty设备驱动中在访问某些资源的时候没有正确的加锁处理,准确来说,加锁的范围较小。首先,先看一下理解这个漏洞必要的两个数据结构
struct tty_buffer { struct tty_buffer *next; char *char_buf_ptr; unsigned char *flag_buf_ptr; int used; int size; int commit; int read; /* Data points here */ unsigned long data[0]; }; struct tty_struct { int magic; struct kref kref; struct device *dev; struct tty_driver *driver; const struct tty_operations *ops; struct tty_bufhead buf; };
tty_buffer是一个动态大小的数据结构,其中,char_buf_ptr指向该对象后面的第一字节,即(char_buf_ptr = tty_buffer+sizeof(tty_buffer)大小为size... flag_buf_ptr=tty_buffer+sizeof(tty_buffer)+size。大小为size。used为已经使用的buffer大小。tty_struct为tty的数据结构,其中ops为tty设备的一些操作函数,如open(),write()。
该漏洞的函数调用为write(pty_fd) in userspace -> sys_write() in kernelspace -> tty_write() -> pty_write() -> tty_insert_flip_string_fixed_flag()。看 tty_insert_flip_string_fixed_flag()函数:
int tty_insert_flip_string_fixed_flag(struct tty_struct *tty, const unsigned char *chars, char flag, size_t size) { int copied = 0; do { int goal = min_t(size_t, size - copied, TTY_BUFFER_PAGE); int space = tty_buffer_request_room(tty, goal); struct tty_buffer *tb = tty->buf.tail; if (unlikely(space == 0)) break; memcpy(tb->char_buf_ptr + tb->used, chars, space); memset(tb->flag_buf_ptr + tb->used, flag, space); tb->used += space; copied += space; chars += space; } while (unlikely(size > copied)); return copied; }
这个函数的大致流程为通过tty_buffer_request_room来申请函数空间,如果没有,则另外申请。利用memcpy进行复制内存。最后再递增used。其中memcpy调用时间较长,由于没有加锁,存在竞争条件的问题,查看tty_buffer_request_room,看是否能够利用:
int tty_buffer_request_room(struct tty_struct *tty, size_t size)
{
struct tty_buffer *b, *n;
int left;
unsigned long flags;
spin_lock_irqsave(&tty->buf.lock, flags);
if ((b = tty->buf.tail) != NULL)
left = b->size - b->used;
else
left = 0;
if (left < size) { <1>
/* This is the slow path - looking for new buffers to use */
if ((n = tty_buffer_find(tty, size)) != NULL) {
if (b != NULL) {
b->next = n;
b->commit = b->used;
} else
tty->buf.head = n;
tty->buf.tail = n;
} else
size = left;
}
spin_unlock_irqrestore(&tty->buf.lock, flags);
return size;
}
这里有一个整数溢出的问题,由于程序员的疏忽size为unsigned,而left为int,根据c语言规则,left为转化为无符号,在<1>中,如果left为负数,转化为无符号数,便可以实现size大于left,即需要的空间大于空余的空间,但是仍不进行内存分配,再通过tty_insert_flip_string_fixed_flag函数里的memcpy来溢出,对内存进行读写。left = b->size - b->used,其中size不能改变,但是可以改变used的值,通过条件竞争,来对used进行连续多次写,使used大于size。
详细流程图如下:
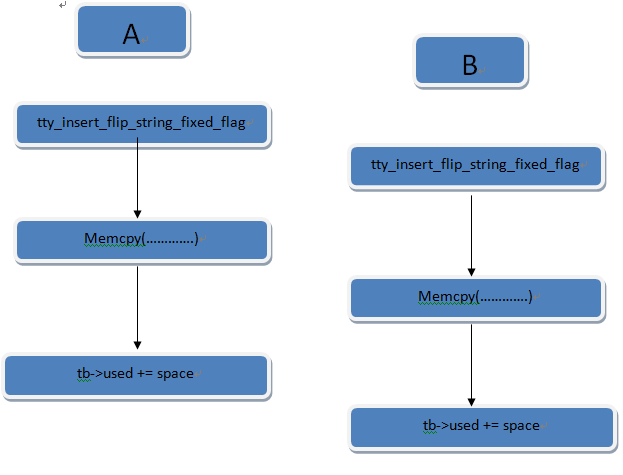
由于memcpy函数将会持续较长时间,只要对一个tty连续多次利用多线程对该函数进行申请空间,使used > size,这样就可以在使用memcpy时,进行内存溢出。
这个漏洞,是一个非常典型的竞争条件漏洞。其实也就是上面那个测试代码也是这个函数的简化版。
3:结语
在现代操作系统,竞争条件是不可避免的,只要两个两个执行线程访问同一个数据结构,由于我们无法预测linux调度的顺序,就会产生混合,就可能产竞争条件。我们如果需要对内核或驱动编写,应该尽量避免资源的共享,如果不可避免,需要利用锁来对原子数据进行锁定。