1.用Hive对爬虫大作业产生的文本文件(或者英文词频统计下载的英文长篇小说)进行词频统计。
- 先下载英语长篇文章到wc文件下

- 上传5000-8文件到hdfs

- 进入hive,创建新表
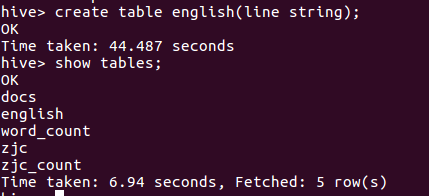
- 在hdfs中的5000-8.txt导入到english表中

- 查看该表中的信息
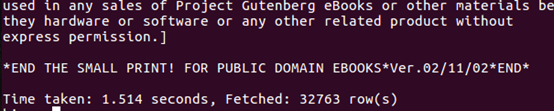
- 进行词频统计存放在english_count表中

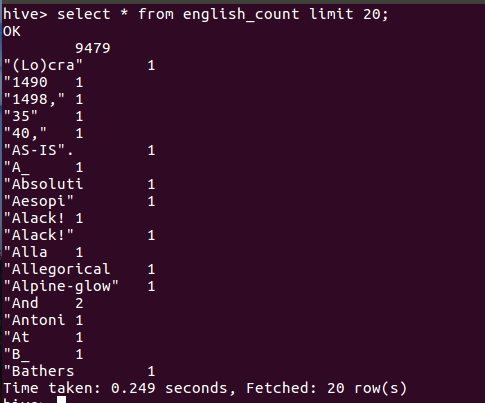
- 查看english_count表的前20行数据
2.用Hive对爬虫大作业产生的csv文件进行数据分析,写一篇博客描述你的分析过程和分析结果。
- 将爬虫大作业的cvs数据传到wc目录下
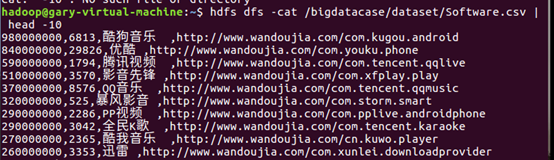
- 将csv文件上传到hdfs中的gigdatacase,并查看

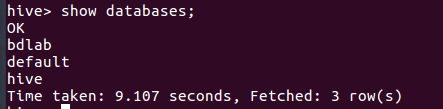
- 显示数据库,并进bdlab数据库
- 创建初始表,并导入数据


- 显示前10行数据
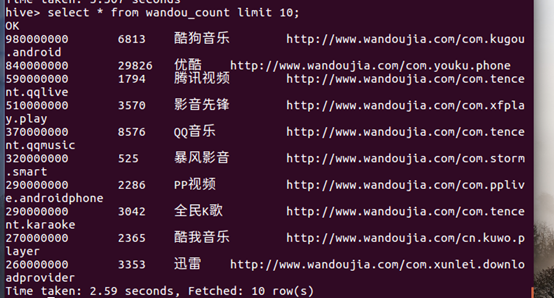
分析数据:
统计该表中有多少条数据行


查看评价人数大于1000的软件数量
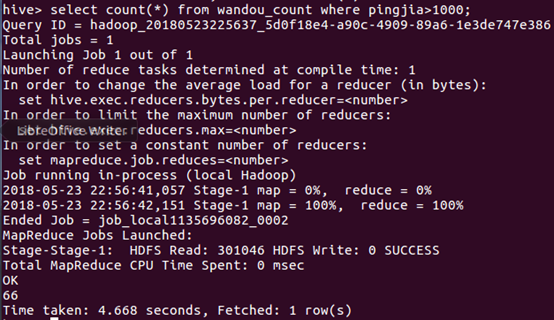
查看显示评价人数大于1000且安装人数大于1亿的全部软件
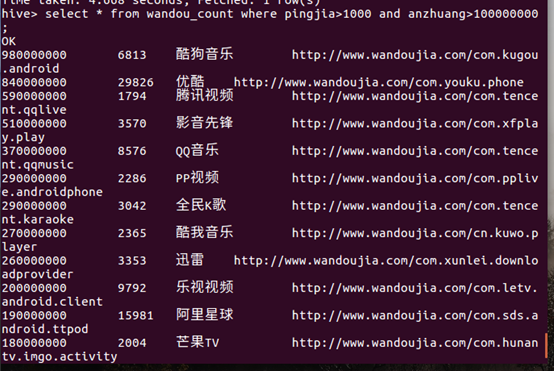
显示的数据均符合预期效果。