该节课中提到了一种叫作softmax的函数,因为之前对这个概念不了解,所以本篇就这个函数进行整理,如下:
维基给出的解释:softmax函数,也称指数归一化函数,它是一种logistic函数的归一化形式,可以将K维实数向量压缩成范围[0-1]的新的K维实数向量。函数形式为:
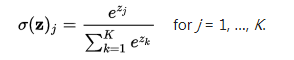
(1)
其中,分母部分起到归一化的作用。至于取指数的原因,第一是要模拟max的行为,即使得大的数值更大;第二是方便求导运算。
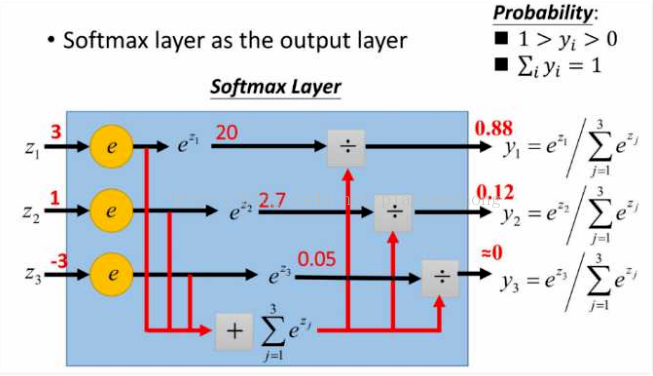
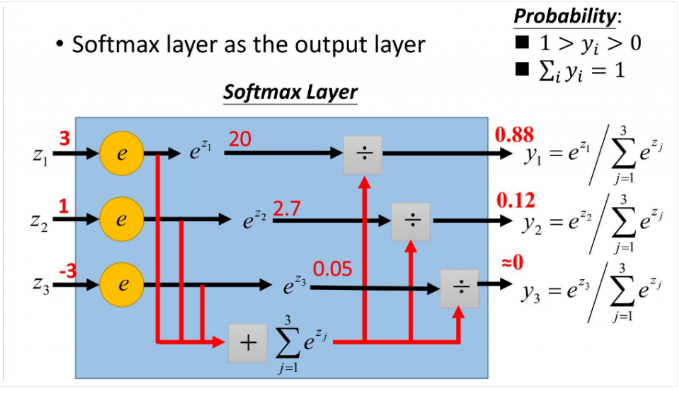
在概率论中,softmax函数输出可以代表一个类别分布--有k个可能结果的概率分布。
从定义中也可以看出,softmax函数与logistic函数有着紧密的的联系,对于logistic函数,定义如下:

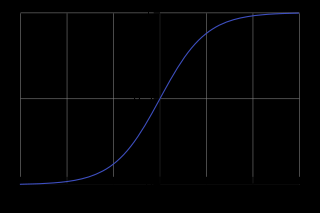
最显著的区别:logistic 回归是针对二分类问题,softmax则是针对多分类问题,logistic可看成softmax的特例。
二分类器(two-class classifier)要最大化数据集的似然值等价于将每个数据点的线性回归输出推向正无穷(类1)和负无穷(类2)。逻辑回归的损失方程(Loss Function):
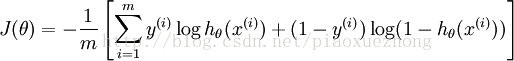
对于给定的测试输入  ,假如想用假设函数针对每一个类别j估算出概率值
,假如想用假设函数针对每一个类别j估算出概率值 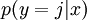 。即估计 的每一种分类结果出现的概率。因此,假设函数将要输出一个
。即估计 的每一种分类结果出现的概率。因此,假设函数将要输出一个  维的向量(向量元素的和为1)来表示这 个估计的概率值。 假设函数
维的向量(向量元素的和为1)来表示这 个估计的概率值。 假设函数 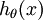 形式如下:
形式如下:
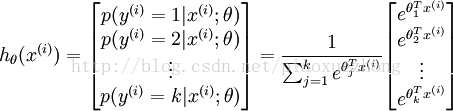
其中 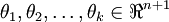 是模型的参数。请注意
是模型的参数。请注意 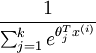 这一项对概率分布进行归一化,使得所有概率之和为 1 。
这一项对概率分布进行归一化,使得所有概率之和为 1 。
其代价函数可以写为

其中,1{真}=1,1{假}=0.
12.23补充:
关于代价函数,softmax用的是cross-entropy loss,信息论中有个重要的概念叫做交叉熵cross-entropy, 公式是:

香农熵的公式:
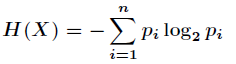
交叉熵与 loss的联系,设p(x)代表的是真实的概率分布,那么可以看出上式是概率分布为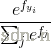
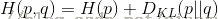
softmax的应用:
在人工神经网络(ANN)中,Softmax常被用作输出层的激活函数。其中,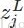
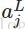
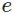
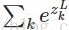
不仅是因为它的效果好,而且它使得ANN的输出值更易于理解,即神经元的输出值越大,则该神经元对应的类别是真实类别的可能性更高。
12.17补充:softmax求导
由公式(1)可知,softmax函数仅与分类有关:
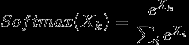
其负对数似然函数为:
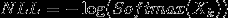
对该似然函数求导,得:
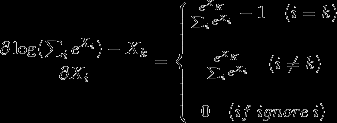
注:参考博客里上面求导公式有误,已更正。
对于①条件:先Copy一下Softmax的结果(即prob_data)到bottom_diff,再对k位置的unit减去1
对于②条件:直接Copy一下Softmax的结果(即prob_data)到bottom_diff
对于③条件:找到ignore位置的unit,强行置为0。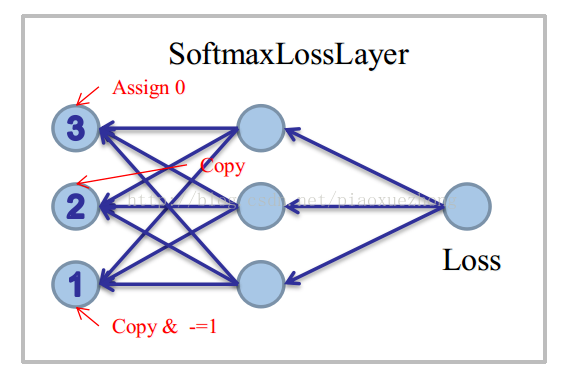
转自:https://blog.csdn.net/liusandian/article/details/80370214