第四章学习记录和心得
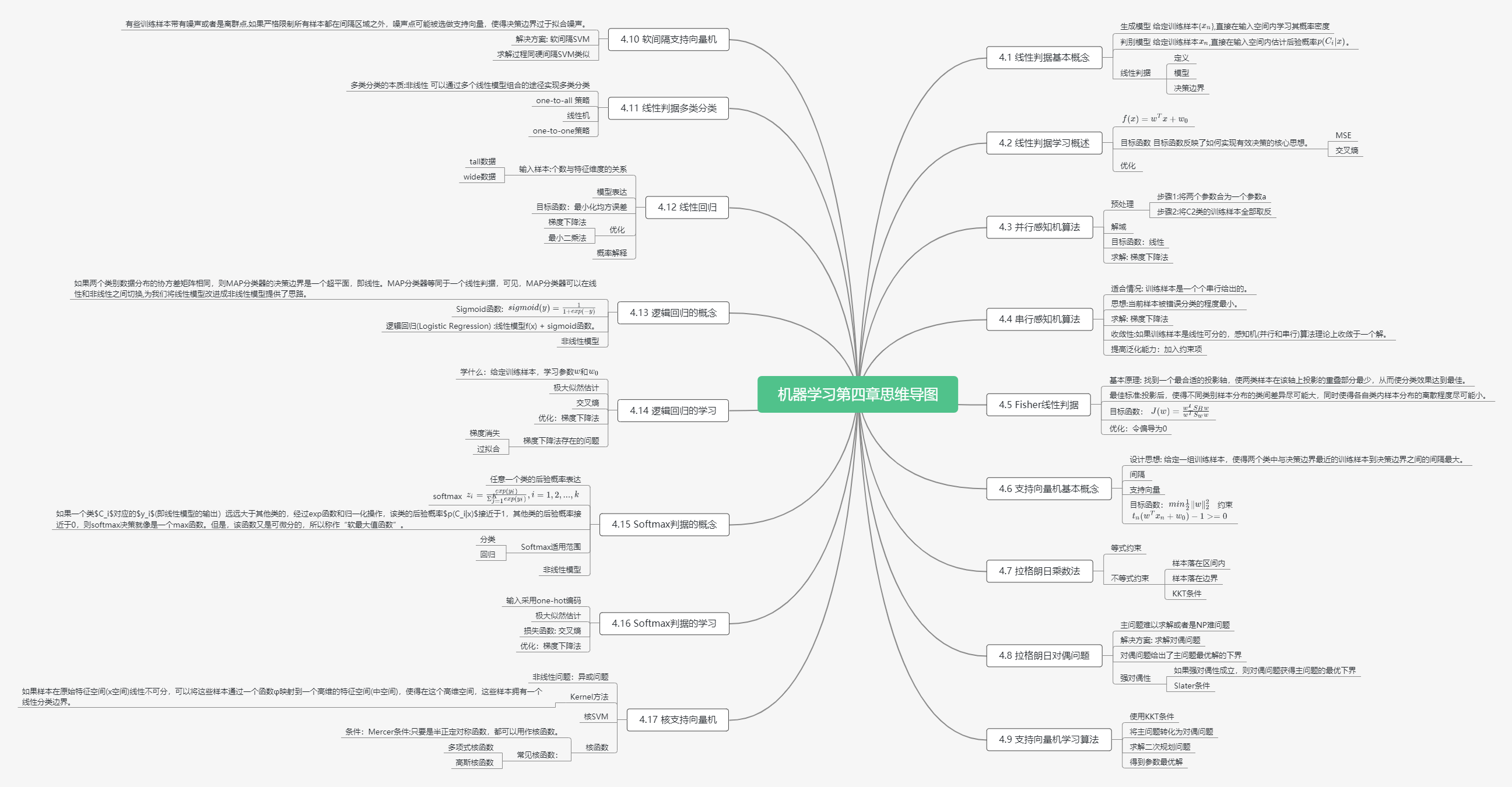
4.1 线性判据基本概念
判别模型:给定训练样本({x_n}),直接在输入空间内估计后验概率(p(C_i|x))。
- 优势: 快速直接、省去了耗时的高维观测似然概率估计。
线性判据
定义: 如果判别模型f(x)是线性函数,则f(x)为线性判据。
- 可以用于两类分类,决策边界是线性的。
- 也可以用于多类分类,相邻两类之间的决策边界也是线性的。



4.2 线性判据学习概述


4.3 并行感知机算法
并行感知机
- 预处理


对目标函数求偏导

- 梯度下降法



4.4 串行感知机算法
- 适合情况: 训练样本是一个个串行给出的。
- 目标函数:

目标函数求解


收敛性:如果训练样本是线性可分的,感知机(并行和串行)算法理论上收敛于一个解。

- 提高感知机泛化能力
- 问题:当样本位于决策边界边缘时,对该样本的决策有很大的不确定性
- 解决思路:

- 目标函数

- 目标函数求解

4.5 Fisher线性判据



- 目标函数新表达


最优解

4.6 支持向量机基本概念
- 设计思想: 给定一组训练样本,使得两个类中与决策边界最近的训练样本到决策边界之间的间隔最大。



4.7 拉格朗日乘数法







4.8 拉格朗日对偶问题

-
主问题难以求解或者是NP难问题
-
解决方案: 求解对偶问题

- 对偶问题给出了主问题最优解的下界


4.9 支持向量机学习算法



- 该问题是一个二次优化问题,可以直接调用相关算法求解



4.10 软间隔支持向量机
有些训练样本带有噪声或者是离群点.如果严格限制所有样本都在间隔区域之外,噪声点可能被选做支持向量,使得决策边界过于拟合噪声。
解决方案: 软间隔SVM




4.11 线性判据多类分类
-
多类分类的本质:非线性
可以通过多个线性模型组合的途径实现多类分类
- one-to-all 策略


存在混淆区域

- 线性机


one-to-one策略

4.12 线性回归


- 目标函数: 均方误差


使用梯度下降法求解

得出最优解(W=(x^TX)^{-1}X^TT)
4.13 逻辑回归的概念
- 如果两个类别数据分布的协方差矩阵相同,则MAP分类器的决策边界是一个超平面,即线性。MAP分类器等同于一个线性判据,可见,MAP分类器可以在线性和非线性之间切换,为我们将线性模型改进成非线性模型提供了思路。
- Logit变换



在每类数据是高斯分布且协方差矩阵相同的情况下,x属于C1类的后验概率与属于C2类的后验概率之间的对数比率就是线性模型f(x)的输出。

由于Logit变换等同于线性判据的输出,所以在此情况下Logit(z)是线性的。

- Sigmoid函数

- 逻辑回归

- 决策过程:

单个逻辑回归就是一个神经元模型
- 总结
- 逻辑回归本身是一个非线性模型。
- 逻辑回归用于分类:仍然只能处理两个类别线性可分的情况。但是,sigmoid函数输出了后验概率,使得逻辑回归成为一个非线性模型。因此,逻辑回归比线性模型向前迈进了一步。
- 逻辑回归用于拟合:可以拟合有限的非线性曲线。

4.14 逻辑回归的学习
- 学什么:给定训练样本,学习参数w和(w_0)


针对训练样本((x_n,t_n)),如果模型输出概率较低,说明参数不是最优的
- 似然函数



- 交叉熵


- 使用梯度下降法对目标函数优化




-
当y = wTx+w0较大时,sigmoid函数输出z会出现饱和:输入变化量△y很大时,输出变化量△z很小。
-
在饱和区,输出量z接近于1,导致sigmoid函数梯度值接近于0,出现梯度消失问题。
-
如果迭代停止条件设为训练误差为0,或者所有训练样本都正确分类的时候才停止,则会出现过拟合问题。
-
所以,在达到一定训练精度后,提前停止迭代,可以避免过拟合。
4.15 Softmax判据的概念


- 得到任意正类的后验概率p((C_i|x))

- 重新审视参考负类的后验概率(p(C_i|x))

- 得到任意类的后验概率(p(C_i|x))

- Softmax函数

- 如果一个类(C_i)对应的(y_i)(即线性模型的输出)远远大于其他类的,经过exp函数和归一化操作,该类的后验概率(p(C_i|x))接近于1,其他类的后验概率接近于0,则softmax决策就像是一个max函数。
- 但是,该函数又是可微分的,所以称作“软最大值函数”。
- Softmax判据:K个线性判据+ softmax函数。



-
Softmax适用范围:分类/回归
-
前提:每个类和剩余类之间是线性可分的。
-
范围:可以拟合指数函数(exp)形式的非线性曲线。
-
总结

4.16 Softmax判据的学习

- 给定训练样本,学习K组参数



目标函数



对参数(w_k)求偏导



对参数(w_{0k})求偏导

- 采用梯度下降法更新所有{({w_i},w_{0i})}
- 设当前时刻为k,下一个时刻为k +1
- η为更新步长。

4.17 核支持向量机
- 提出问题:异或问题分类边界是非线性曲线





- 核函数:在低维X空间的一个非线性函数,包含向量映射和点积功能,即作为X空间两个向量的度量,来表达映射到高维空间的向量之间的点积:


决策边界方程也由N个非线性函数的线性组合来决定。因此,在X空间是一条非线性边界。
-
Kernel SVM的学习
-
由于kernel SVM在高维o空间是线性的,所以kernel SVM的对偶函数可以表达为:


- 核函数如何设计?核函数如何影响分类边界?
Mercer条件:只要是半正定对称函数,都可以用作核函数。即对于N个样本,如下矩阵K是半正定对称矩阵。

- 多项式核函数

- 不同的核函数参数值,决定了不同的支持向量和分类边界。
- ρ,m:取值越高,分类边界非线性程度越高。
- 高斯核函数

- 不同的核函数参数值,决定了不同的支持向量和分类边界。
- 方差越小,分类边界越不平滑,甚至出现孤岛(过拟合)。
思维导图