写在前面
- 博客链接: 吴沅静, 曹兰英
- github链接:吴沅静,曹兰英,两人代码合并一起的代码(曹兰英)
- 具体分工:
无共同努力
题目描述
我们会将原始字符图片(已上传QQ群)平均切割成九份小图,并随机抠掉一张图充当空格,此时图片为原始状态;
然后我们将小图的顺序打乱并拼接回去,你需要做的事就是移动白色的图片将图片恢复到原始的状态(类似数字华容道)
任务
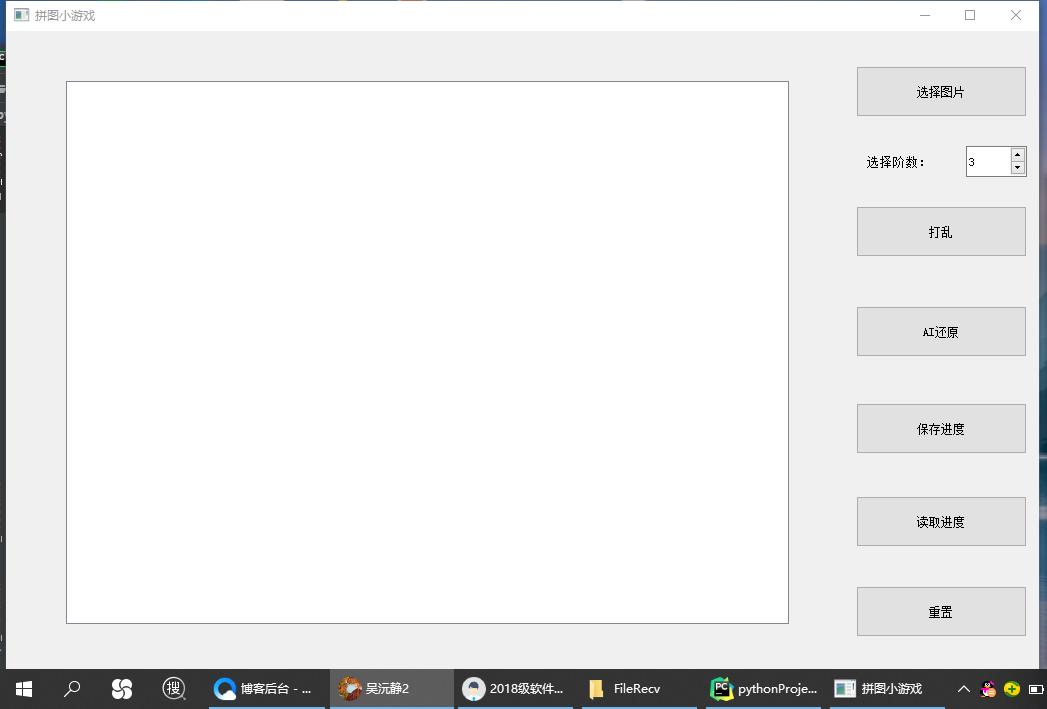
[0.1]作业的设计说明
我们の愿景:
- 开始界面:
STEP 1 :打开图片:一个输入框输入你所要完成拼图的图片
STEP 2 :选择分割图片维数:有下拉框,可选择3*3,4*4.....
STEP 3 :选择第几张图片空缺:决定要扣掉的图片
像这样的:

- 进行界面:
STEP 1:打乱图片:随机打乱图片
STEP 2:开始重排:自动重排
STEP 3:退出
像这样的:

[1]原型设计
[1.1]原型模型设计工具实现:
原型工具:Axure Rp
STEP 1:开始
STEP 2:初始

STEP 3:打乱

STEP 4:还原

[1.2]描述结对的过程:
附上我们讨论的图片

[1.3]遇到的困难及解决方法:
| 问题描述 | 解决尝试 | 是否解决 | 有何收获 |
|---|---|---|---|
| 接着就开始编程,但是思路明白了但是不会实现 | 拥抱开源 | 已解决 | 多向大佬们学习,多借鉴大佬们写的代码 |
| 一开始不知道如何操作,没有具体的思路(甚至想做图片的识别 | 多思考,讨论,百度 | 已解决:将图片进行编号转化为数字华容道 | 多审题,多沟通 |
| 刚开始不知道怎么用那个工具,连图框都不会用,无语子 | 每次遇到不会的操作,就上网百度,可以解决很多问题 | 已解决:最后操作结果就比较简陋,感觉呈现出的东西,不是自己脑中想的那样 | 我变秃了,也变强了。(笑) |
[2]AI与原型设计实现:
[2.1]网络接口的使用
- 上传文件(post请求)
url = 'xxxxxxxxxxxxx' # 接口地址
data = {'file':open(r'C:UsersyssDesktop上传文件.txt','rb')}
# rb表示文件打开方式,b表示二进制,文件上传时需要二进制才行
req = requests.post(url,file=data) # 发送请求
print(req.text) # 返回字符串类型
- 下载文件(get请求)
url = 'http://aliuwmp3.changba.com/userdata/userwork/12107482.mp3'
# 要下载的文件地址
req = requests.get(url) # 发送请求
with open(r'C:UsersyssDesktopaqmm.mp3','wb') as fw:
# 将下载内容写入文件,wb表示二进制写入
fw.write(req.content)
# 写入文件;req.content表示返回结果,content表示指定返回结果为二进制
[2.2]AI的具体实现见“部分三”
[3]代码组织与内部实现设计
[3.1]代码程序的详情
- 如图所示:
SoftWareProject
│ readme
│ requirements.txt
│ setup.py
├─ bin
│ └─ projectname
├─ docs
│ └─ abc.rst
│ └─ conf.py
└─ project
│ main.py 程序入口
│ init.py
└─ tests
└─ test_main.py
└─ init.py
[3.2]说明算法的关键与关键实现部分流程图
- 流程图
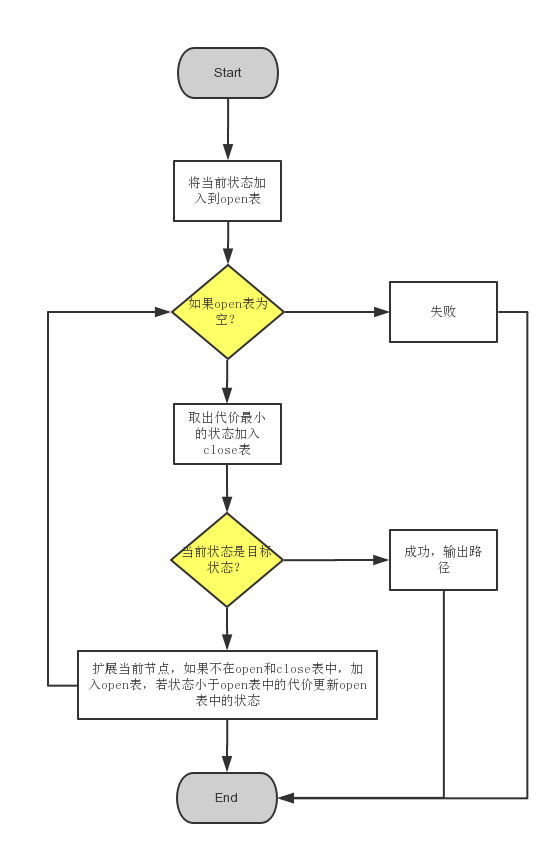
- 关键算法:A*算法
A*是路径搜索中最受欢迎的选择,因为它相当灵活,并且能用于多种多样的情形之中。
和其它的图搜索算法一样,A*潜在地搜索图中一个很大的区域。
和Dijkstra一样,A*能用于搜索最短路径。
和BFS一样,A*能用启发式函数,引导它自己。在简单的情况中,它和BFS一样快。

在凹型障碍物的例子中,A*找到一条和Dijkstra算法一样好的路径:

-
对应A*算法
成功的秘决在于,它把Dijkstra算法(靠近初始点的结点)和BFS算法(靠近目标点的结点)的信息块结合起来。
在讨论A*的标准术语中,g(n)表示从初始结点到任意结点n的代价,h(n)表示从结点n到目标点的启发式评估代价(heuristic estimated cost)。
在上图中,yellow(h)表示远离目标的结点而teal(g)表示远离初始点的结点。
当从初始点向目标点移动时,A*权衡这两者。每次进行主循环时,它检查f(n)最小的结点n,其中f(n) = g(n) + h(n)。
[3.3]透过现象看本质
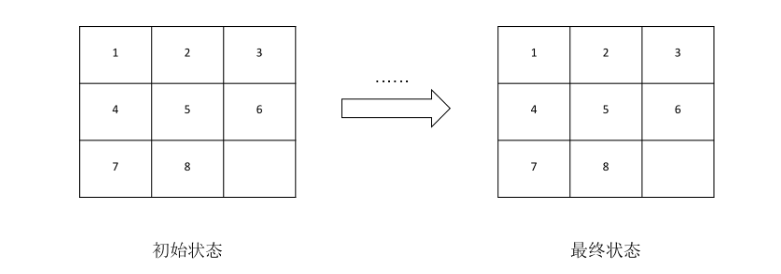
所以,我们这次的拼图复原可以看成8数码问题
问题的本质
step 1.首先我们要简化一下八数码问题,我们移动数字就是相当于移动空格。
这样我们就将问题简化为空格的移动,空格移动的状态只有4种:上、下、左、右。
step 2.然而在八数码问题中并不是每次空格的移动都有四种状态,我们要判断在当前位置也移动的状态才能移动,
我们还要去掉一种状态就是当前状态的父状态,因为如果我们移动到父状态则相当于回退了一步。
step 3.然后,我们要关心的就是给定的初始化状态是否能够通过移动而达到目标状态。
PS:这就涉及到了数学问题:如果初始状态和目标状态的逆序值同为奇数或同为偶数,则可以通过有限次数的移动到达目标状态;否则无解。
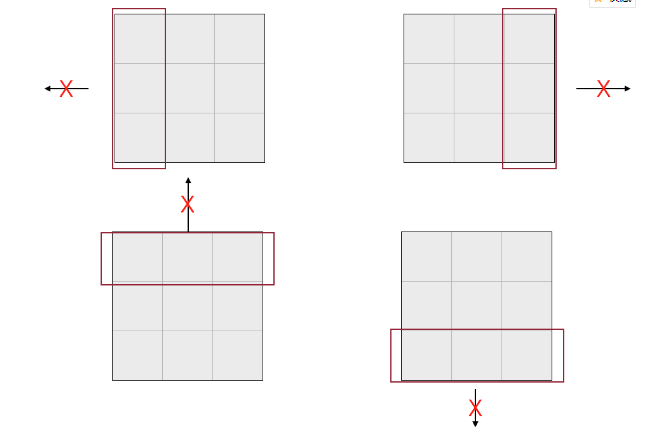
既然我们已经清楚了空格移动的方式,我们讨论一下空格的几种移动的可能方式:
对应的状态如图所示:
[4]贴出你认为重要的/有价值的代码片段,并解释
[4.1]实现自动复原的代码
当然是这个代码最重要了,灵魂!!!!自动复原的灵魂!!!
def run_Axing():
maxcount=10000+m*m*n*n
# 1. 把起始格添加到开启列表。
openList[0]=li0[:]
cost[0]=H_cost(li_goal,openList[0])
before[0]=0
Gn = 0
# 2.重复如下的工作:
while len(closeList)<10000:
# a) 寻找开启列表中H值最低的格子。我们称它为当前格。
mc = cost.index(min(cost))
if cmp(openList[mc][:],li_goal[:])==0:
return mc
x = openList[mc].index(0) + 1
# b) 把它切换到关闭列表。
closeList.append(openList[mc][:])
cost[mc]=maxcount
# c) 对相邻的8格中的每一个进行以下操作
for i in range(0, 4):
if bool_rules(x, x + move[i]):
temp = turn(x, x + move[i], openList[mc][:])[:]
if closeList.count([temp]) == 0: # 如果它不可通过或者已经在关闭列表中,略过它。
if openList.count([temp]) == 0:
openList.append(temp) # 如果它不在开启列表中,把它添加进去。把当前格作为这一格的父节点。记录这一格的H值。
c = H_cost(li_goal, openList[-1])+Gn
cost.append(c)
before.append(mc)
# 如果它已经在开启列表中,用H值为参考检查新的路径是否更好。
# 更低的H值意味着更好的路径。如果是这样,就把这一格的父节点改成当前格,
# 并且重新计算这一格的H值。
else:
t = openList.index(temp)
c = H_cost(li_goal, openList[t])+Gn
if c < cost[t]:
cost[t]=c
before[t] = mc
Gn += 1
return -1
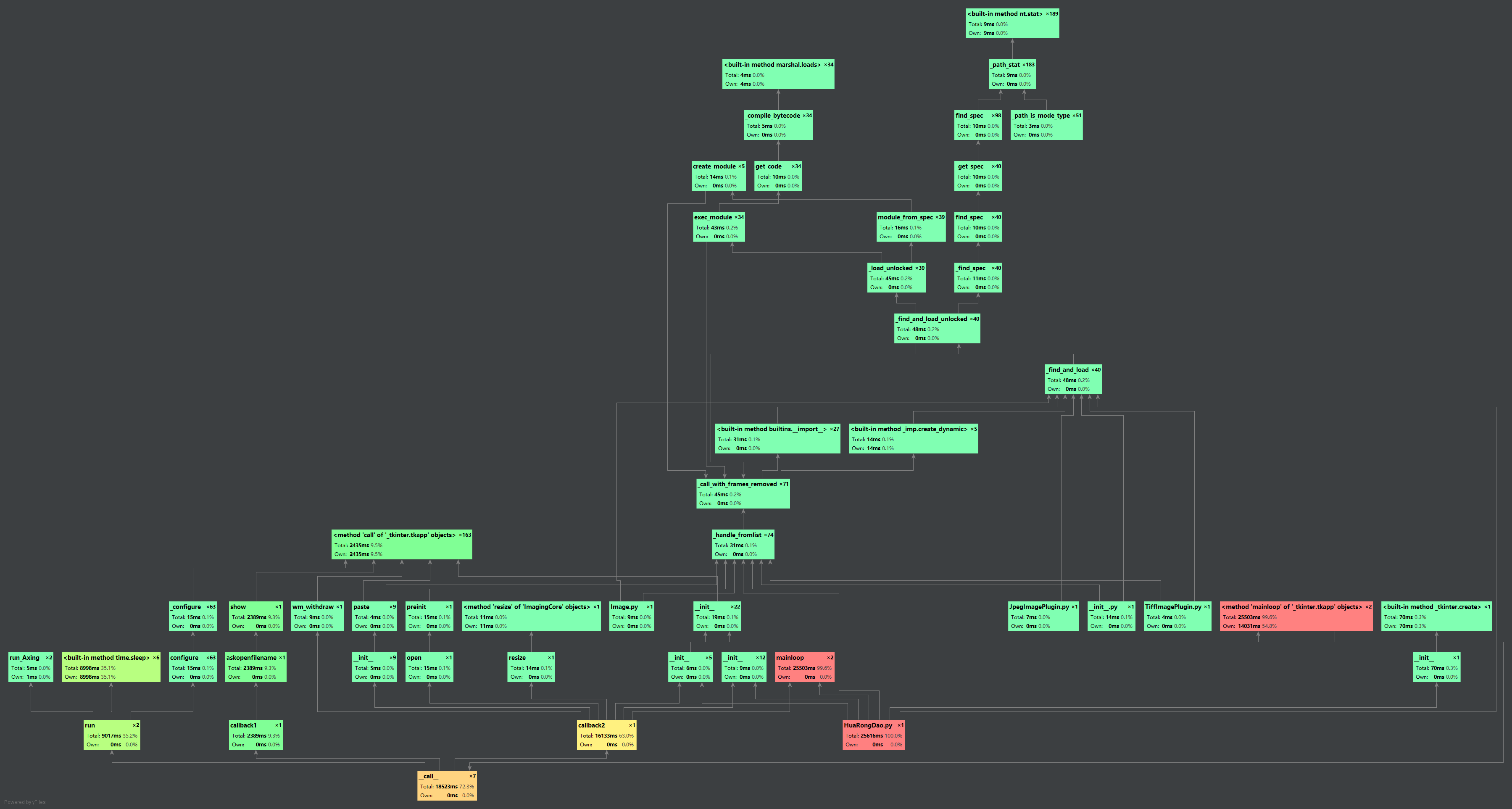
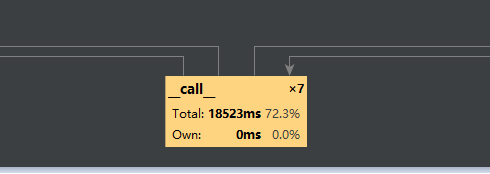
[4.2]性能分析与改进
如图所示:
[4.3]描述你改进的思路
PART ONE:算法
| 开始 | 中间阶段 | 最后 |
|---|---|---|
| 深度优先 | 广度优先 | A* |
| PART TWO:方式过程 | ||
| 开始 | 中间阶段 | 最后 |
| :--: | :----: | :----: |
| 模仿 | 讨论 | 创新 |
[4.4]展示性能分析图和程序中消耗最大的函数
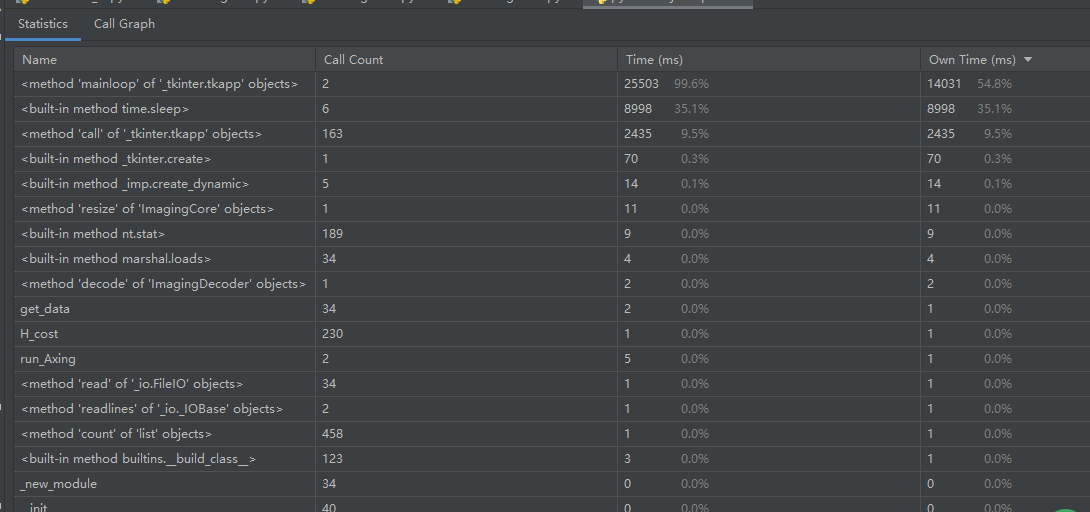
[4.5]要求
- 展示出项目部分单元测试代码,并说明测试的函数,构造测试数据的思路
part one:构造数据结构
class Node(object):
def __init__(self, data, depth):
Node.is_legal_data(data)
self.data = data
self.depth = depth
part two:判断条件(逆序数)
if not Node.get_parity(startpoint) == Node.get_parity(endpoint):
return list()
part three:part two 具体的代码
def get_parity(cls, p_node):
'''return the parity, false to odd, true to oven'''
temp = []
for row in range(len(p_node.data)):
for column in range(len(p_node.data[row])):
temp.append(p_node.data[row][column])
temp.remove(0)
parity_count = 0
for i in range(len(temp)):
for j in range(i):
if temp[j] > temp[i]:
parity_count += 1
return parity_count % 2 == 0
part four:移动的过程(见如下和之前核心代码:A*)
def can_move(cls, p_node, direction_str):
'''return if p_node can move to the specified direction
U for up, D for down, L for left, R for right'''
if direction_str == "U":
# print("w")
return not Node.get_blank_position(p_node)[0] == 0
elif direction_str == "D":
# print("s")
return not Node.get_blank_position(p_node)[0] == 2
elif direction_str == "L":
# print("a")
return not Node.get_blank_position(p_node)[1] == 0
elif direction_str == "R":
# print(d")
return not Node.get_blank_position(p_node)[1] == 2
else:
SystemError("no such direction: {}".format(direction_str))
part five:执行(测试)
def main():
#指定生成有效节点
endpoint = Node([
[8, 0, 7],
[6, 5, 4],
[3, 2, 1] ], 0)
startpoint = Node([
[1,2,3,],
[0,4,5],
[6,7,8], ], 0)
#随机生成有效节点
while True:
startpoint = Node.random_node()
endpoint = Node.random_node()
if Node.get_parity(startpoint) == Node.get_parity(endpoint):
break
# 输出初始节点信息
print('起始状态:
{}'.format(startpoint.__repr__()))
print('结束状态:
{}'.format(endpoint.__repr__()))
# 双向宽度优先
t1 = time.time()
result_list = bi_direction_width_search(startpoint, endpoint)
if result_list:
print('[bi-direction width first search] result found in {:.3}s.'.format(time.time() - t1))
print('path ({} steps):'.format(len(result_list)))
for x in result_list:
print(str(x))
else:
print('no solution!')
#开始执行
if __name__ == '__main__':
main()
- 贴出Github的代码签入记录,合理记录commit信息
[4.6]遇到的代码模块异常或结对困难及解决方法
| 问题描述 | 解决尝试 | 是否解决 | 有何收获 |
|---|---|---|---|
| 列表越界 | 看代码debug,查资料 | 已解决 | 列表的使用更加熟练 |
| 运行结果没有出来(一直在跑 | 已解决 | 多向大佬们学习,多借鉴大佬们写的代码 | |
| 输出结果过于复杂而且重复 | 和上面的一样 | 已解决 | 理清思路,寻求更好的算法,一开始的深度优先搜索,然后找到广度优先,再到A_star,最后到双向广度优先。学会用更好的算法代替 |
| 明明有解,但是显示没解 | 已解决:重做的页面 | 要有辩证的眼光来看待 |
[5]其他要求(PSP和评价)
[5.1]评价你的队友 互吹
见下表:
| 值得学习的地方 | 需要改进的地方 |
|---|---|
| 兰英超级努力,很勤奋,积极沟通,态度超级超级端正 | 可能代打码的能力没有那些大佬们强 |
| 兰英总是会发现我没有注意到的地方 | |
| 计划安排妥当,会督促自己和我积极完成作业 | |
| 写博客也很厉害 |
[5.2]提供此次结对作业的PSP和学习进度条
Part one:PSP总表
| PSP2.1 | Personal Software Process Stages | 预估耗时(小时) | 实际耗时(小时) |
|---|---|---|---|
| Planning | 计划 | 4 | 17 |
| Estimate | 估计这个任务需要多少时间 | 4 | 17 |
| Development | 开发 | 76 | 127.75 |
| Analysis | 需求分析 (包括学习新技术) | 2 | 3 |
| Design Spec | 生成设计文档 | 1 | 2 |
| Design Review | 设计复审 | 5 | 3 |
| Coding Standard | 代码规范 (为目前的开发制定合适的规范) | 4 | 9 |
| Design | 具体设计 | 4 | 5 |
| Coding | 具体编码 | 30 | 55.75 |
| Code Review | 代码复审 | 10 | 20 |
| Test | 测试(自我测试,修改代码,提交修改) | 20 | 30 |
| Reporting | 报告 | 4 | 4 |
| Test Repor | 测试报告 | 1 | 1 |
| 100Size Measurement | 计算工作量 | 2 | 1.25 |
| Postmortem & Process Improvement Plan | 事后总结, 并提出过程改进计划 | 1 | 1.75 |
| Total | 合计 | 84 | 148.75 |
| Part two:学习进度条 | |||
| 第N周 | 新增代码(行) | 累计代码(行) | 本周学习耗时(小时) |
| :--: | :----: | :----: | :----: |
| 第一阶段(9.25~9.30) | 0 | 0 | 2*4 |
| 第二阶段(10.1~10.5) | 56 | 56 | 2.5*5 |
| 第三阶段(10.6~10.10) | 215 | 271 | 2.75*5 |
| 第四阶段(10.11~10.13) | 178 | 449 | 5*3 |
| 第五阶段(10.14~10.16) | 0 | 449 | 5*2+4 |
| 第六阶段(10.17~10.19) | 0 | 449 | 3.5*3 |