
int -2147483648~2147483647
eb级别:bat滴滴美团头条
主要解决海量数据的存储和分析计算问题
大数据四个特点:大量,高速(增加速度快),多样(结构化和非结构化-音频视频图片网络日记,低价值密度
大数据能干吗:物流仓库的选址性价比最高,物流仓库存点啥东西最赚钱,旅游行业:分析数据提前预判。商品广告推荐,抖音推荐视频
大数据业务流程:产品人员找到需求,数据部门搭建平台数据分析,数据可视化展示
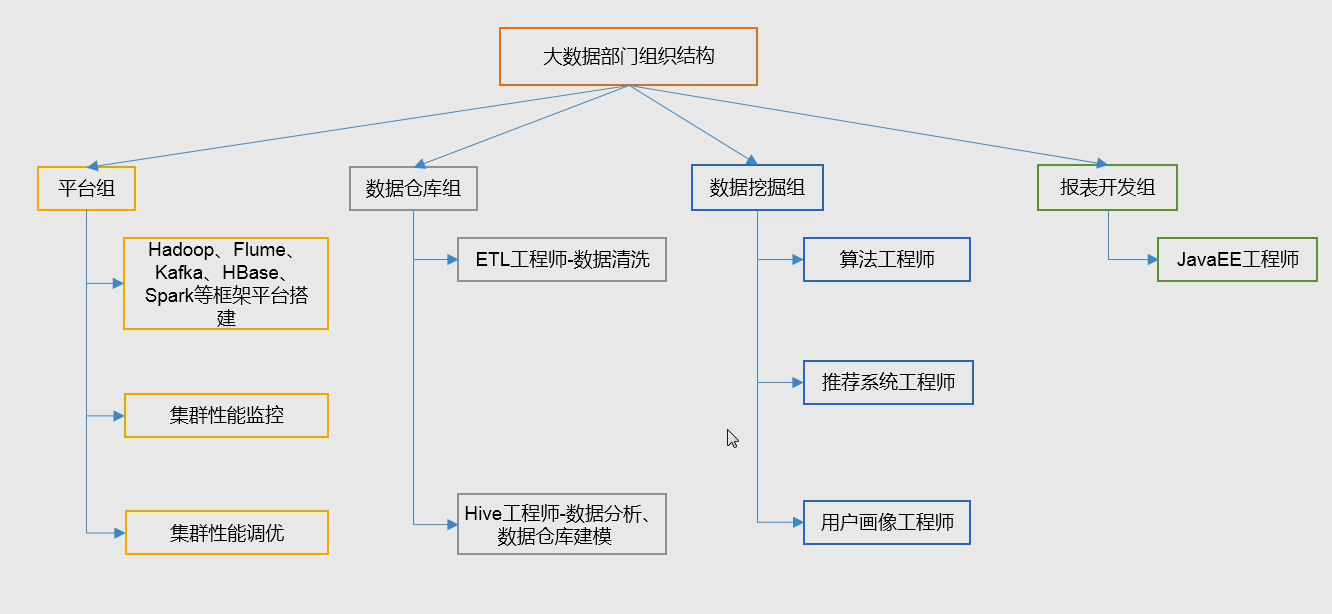
大数据部门组织结构:
平台组:搭建平台,偏累一点
分布式系统:一个业务需要多台服务器来运行解决。
hadoop是分布式系统基础架构。解决海量数据的存和算。hadoop是一个生态圈。

hadoop的Apache版本自己手动解决bug,CDH就是公司的包装好的解决方法。

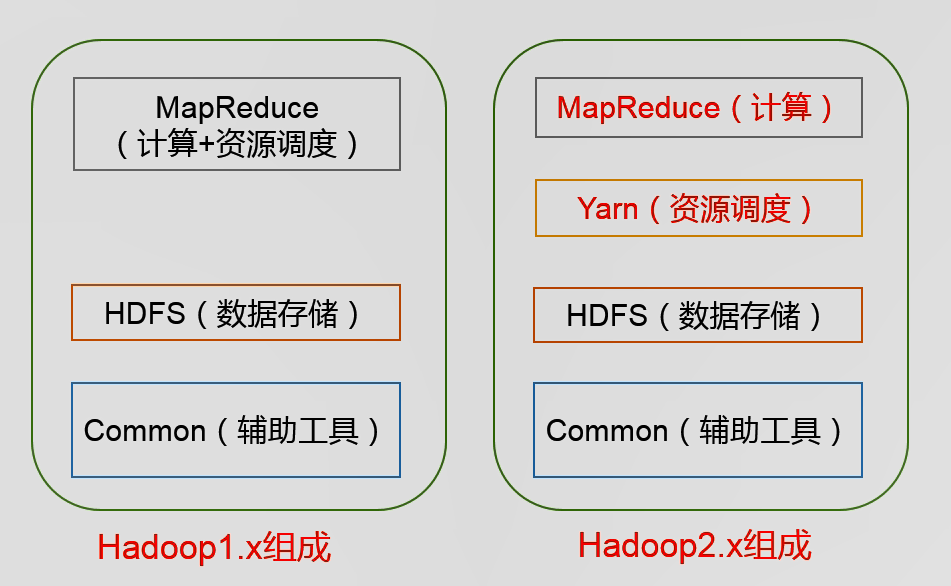

HDFS:有namenode,存储文件名目录结构 datenode:就是实实在在的数据 secondnode辅助namenode的工作。
yarn:包括:资源调度:整个集群的老大
单个节点资源的老大
管理具体任务


半结构化数据:结构化数据的一种,名字可以有一个,属性可以有好多个。
HBase:非关系型数据库 HDFS文件存储。
etc下面是配置文件,lib 本地库文件 sin 启动服务命令,各种启动脚本文件
hadoop多个框架共同执行,进行数据的处理和运行工作
单节点模式:没有运行hdfs,就是运行本地的文件系统
伪分布式:通过运行多个进程模拟分布式存储系统
完全分布式:有三个或者三个以上的虚拟机或者实体机进行完全分布式存储。
伪分布式步骤:1:配置三个文件 2:格式化NameNode 3:启动NameNode。4:jps命令查看java进程是否有namenode进程。
捡到env文件就修改java_home的地址。
备份数据一个服务器只有同一份文件,因为这个挂掉了就没了,多少份都一样。当服务器增加的时候会自动增加上去,自动完成。
伪分布式格式化NameNode时候,必须关闭进程。不关闭到时候自动就又有了。然后删除data文件夹,logs文件夹,然后再进行格式化
logs就是日记信息的存放地址
namenode不能一直格式化:namenode和datanode需要一个id号进行通讯,namenode格式化之后这个id号就变了,两个通讯不达标。
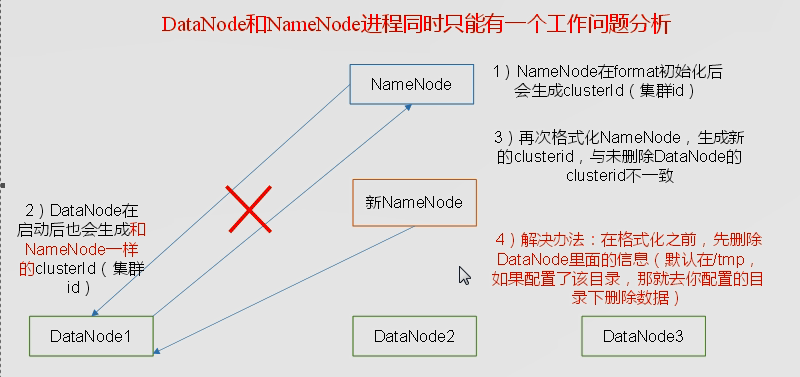 解决方法:把两个进程都关掉之后吧log文件删除掉
解决方法:把两个进程都关掉之后吧log文件删除掉
配置yarn:resourceManager和nodemanager两个东西
9000 namenode端口号 50070 hdfs端口号 8088 yarn端口号,19888 历史服务群端口号 50090:second节点端口号
历史服务器操作过程也需要进行配置
完全式集群配置:scp -r model root@hadoop102:/opt/model 批量复制文件,推送功能 拉取功能:scp -r atguigu@hadoop101:/opt/model ./ 拷贝到当前文件夹图纸图纸
图纸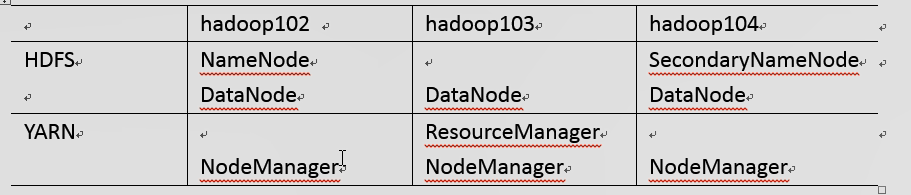 然后对应节点启动对应datanode。
然后对应节点启动对应datanode。
SSH实现无密码登录
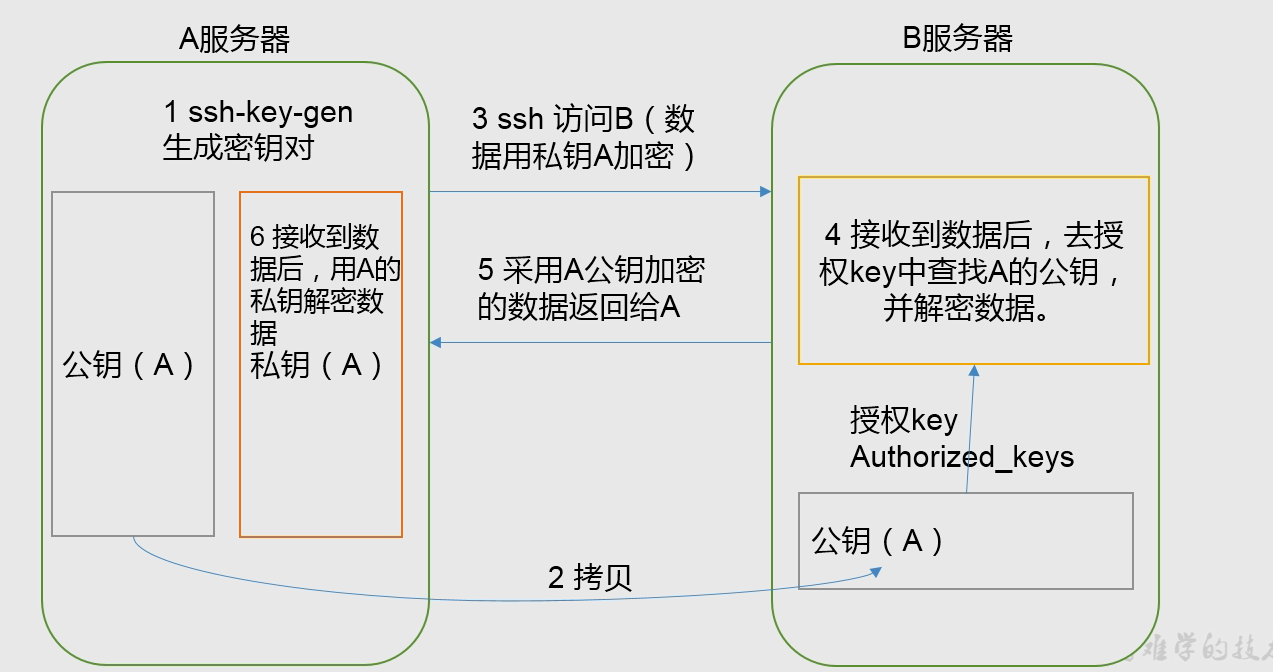
当公共钥匙弄出来之后,发送给103,104,但是还需要给自己发送一份,因为自己登陆自己也是去授权文件家里面找的。
同样的,给103也授权。因为103里面有Resourcemanage节点,需要管102和104的nodemanagernode节点
可以通过 echo $path 输出目录查找当前用户是否在path里面存在
自动执行命令行
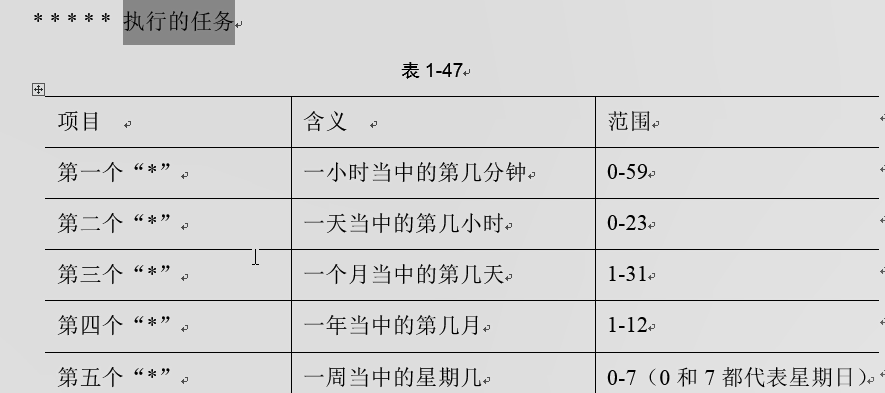

搭建集群一定要搭建时间一致性检查,把一个服务器当做时间准则,其他服务器找这个机器来校准时间。
为什么要编译jar包?Apache给的jar包是32位的,需要编译出来。


大数据的结构
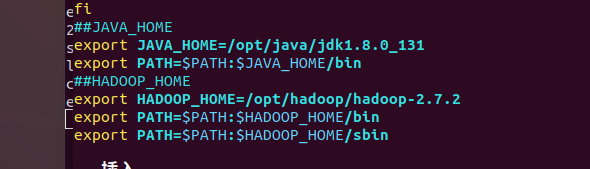 PATH路径
PATH路径
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar wordcount wcinput/ wcouput