这是脚本
# coding:utf-8 import requests,re import time import sys import getopt import base64 guizhe='' session='' sth='' txt='' print("========================This is by Nolan========================") print("======================== FOFA ========================") print("======================== GO IT ========================") def use(): print("fofaurl.py -z x.txt -o seesion -i guiz""he") try: opts, args= getopt.getopt(sys.argv[1:],"z:o:i:") for opt ,arg in opts: if opt in ("-o"): session=arg elif opt in("-i"): sth=arg print(sth) c=str(sth) guizhe=base64.b64encode(c.encode('utf-8')) elif opt in ("-z"): txt=arg except: use() #session = "_fofapro_ars_session=1f21b08fc322dae5271d284803f14f11" header = { "Accept":"text/javascript, application/javascript, application/ecmascript, application/x-ecmascript, */*; q=0.01", "Accept-Encoding":"gzip, deflate, br", "Accept-Language":"zh-CN,zh;q=0.9", "Connection":"keep-alive", "User-Agent":"Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36", "X-CSRF-Token":"DpraMUR6PuefxdVpDmbZmgW9572Oz4CKSkqLa4u+astRxa+NSW5t0gfjlRB8cESuUrBvrD+zkGA9GFcfEYAVZA==", "X-Requested-With":"XMLHttpRequest", "Cookie":"_fofapro_ars_session="+session } def Gettxt(str): with open(txt,"a") as f: f.write(str) def Geturl(url): try: r=requests.get(url=url,headers=header,timeout=10) r.close() if r.status_code == 200: print("===============================This is firt respone ===============================") link_list = re.findall(r'href=\"(h.*?)"', r.text, re.S|re.I) for link in link_list: print(link[0:-1]) else: print("===============================This is third respon ===============================") time.sleep(15) r=requests.get(url=url,headers=der,timeout=10) if r.status_code == 200: link_list = re.findall(r'href=\"(h.*?)"', r.text, re.S|re.I) for link in link_list: print(link[0:-1) Gettxt(link[01]+" ") excecpt: print("==============================This is four respon ===============================") time.sleep(15) try: r=requests.get(url=url,headers=header,timeout=10) if r.status_code == 200: link_list = re.findall(r'href=\"(h.*?)"', r.text, re.S|re.I) for link in link_list: print(link[0:-1]) Gettxt(link[0:-1]+" ") except: print("===============================This is five respon ===============================") time.sleep(15) try: r=requests.get(url=url,headers=header,timeout=10) if r.status_code == 200: link_list = re.findall(r'href=\"(h.*?)"', r.text, re.S|re.I) for link in link_list: print(link[0:-1]) Gettxt(link[0:-1]+" ") except: print("=========no methods to solve it =================")
图形化采用的QT5设计 很简单(但是C#好些 努力学习ing)
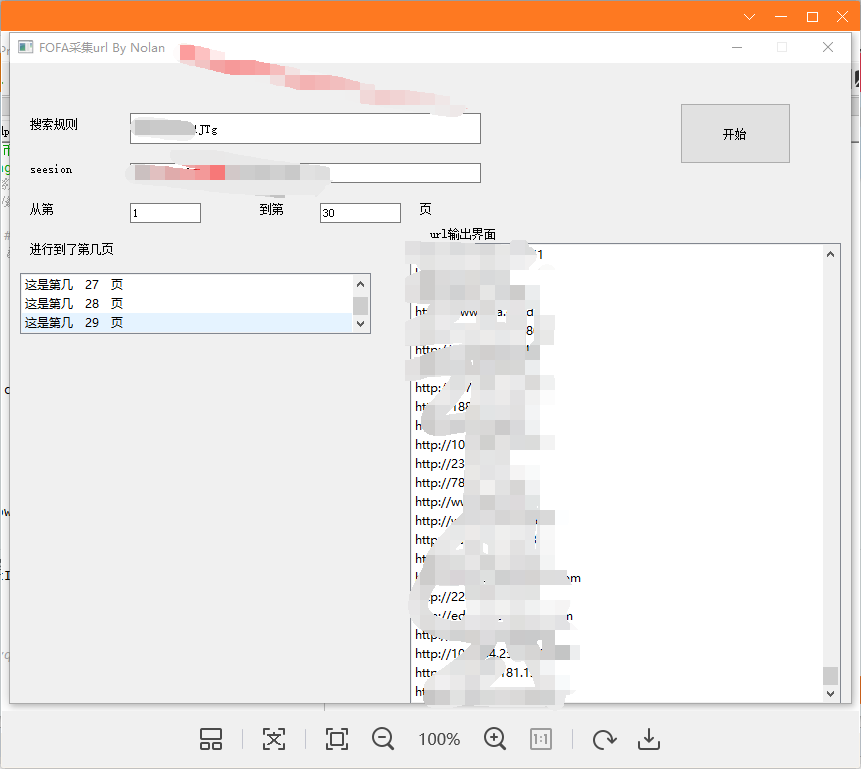
此脚本仅提供学习使用 切勿用于任何非法用途
一切后果与本人无关且勿违反法律道德,后果自负。