为什么使用 Pipeline?
Redis客户端执行一条命令分为如下四个过程:
- 发送命令
- 命令排队
- 命令执行
- 返回结果
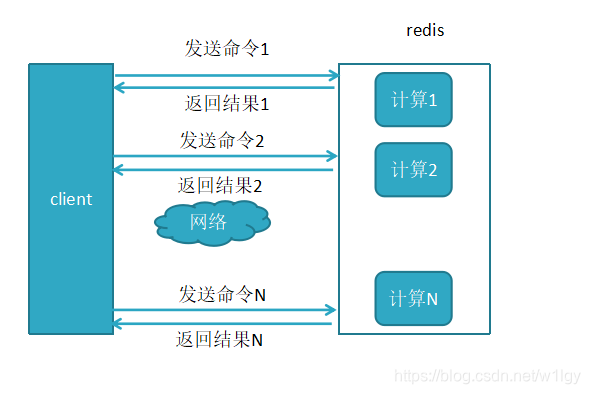
其中,1到4称为Round Trip Time(RTT,往返时间)。
Redis提供了批量操作命令(例如mset、mget等),有效地节省了RTT。但大部分命令是不支持批量操作的,例如要执行n次hgetall命令,并没有mhgetall命令存在,需要消耗n次RTT。Redis的客户端和服务端可能部署在不同的机器上。例如客户端在北京,Redis服务器在上海,两地直线距离1300公里,那么一次RTT时间= 1300 x2 / 3000000 x
2/3) = 13毫秒(光在真空中的传输速度为30万公里/秒,这里假设光纤为光速的2/3),那么客户端在1秒内大约只能执行80次左右的命令,这个Redis的高并发高吞吐特性背道而驰。
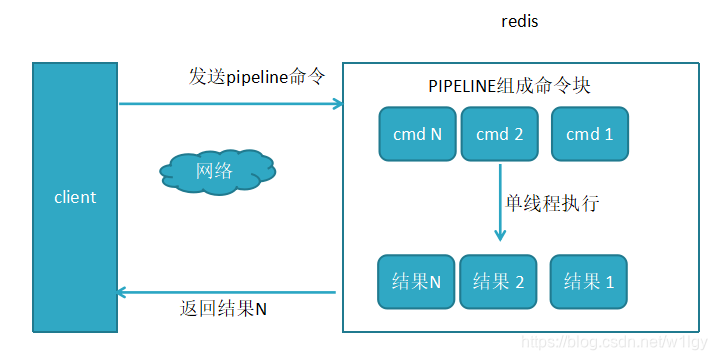
总结:Redis的pipeline功能的原理是 客户端通过一次性将多条redis命令发往Redis 服务端,减少了每条命令分别传输的IO开销。同时减少了系统调用的次数,因此提升了整体的吞吐能力。
未使用pipeline执行N条命令
使用了pipeline执行N条命令
go语言下Pipeline使用
- 获取Redis对象(一般从连接池中获取)
- 获取Redis对象的pipeline对象
- 添加指令
- 执行指令
package main
import (
"github.com/go-redis/redis"
"log"
"strconv"
)
func main() {
client := redis.NewClient(&redis.Options{
Addr: "localhost:6379",
Password: "", // no password set
DB: 0, // use default DB
Network: "tcp",
PoolSize: 50,
})
if _, err := client.Ping().Result(); err != nil {
panic(err)
}
pipe := client.Pipeline()
pipe.Get("key1")
pipe.Get("key2")
pipe.Get("key3")
result, err := pipe.Exec()
defer client.Close()
}
redis-go:
github:https://github.com/alphazero/Go-Redis
原生批量命令(mset, mget)与Pipeline对比
可以使用Pipeline模拟出批量操作的效果,但是在使用时要注意它与原生批量命令的区别,主要包括如下几点:
- 原生批量命令是原子的,Pipeline是非原子的;
- 原生批量命令是一个命令对应多个key,Pipeline支持多个命令;
- 原生批量命令是Redis服务端支持实现的,而Pipeline需要服务端和客户端的共同配合。
参考:
https://blog.csdn.net/w1lgy/article/details/84455579?utm_medium=distribute.wap_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-1.nonecase&depth_1-utm_source=distribute.wap_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-1.nonecase