pandas常用数据类型:
1. Series一维,带标签数组(标签即索引)
2. DataFrame二维,Series容器


import pandas as pd import numpy as np import string # 数组形式创建 demo = pd.Series(np.arange(10),index=list(string.ascii_uppercase[:10])) print(demo) """ A 0 B 1 C 2 D 3 E 4 F 5 G 6 H 7 I 8 J 9 dtype: int32 """ #字典形式创建 dataDic = {"name":"goodDog", "age": 12, "sex": "1"} demo2 = pd.Series(dataDic) print(demo2) """ name goodDog age 12 sex 1 dtype: object """ # 修改数据类型 demo1 = demo.astype(float) print(demo1.dtype) # float64 # 标签索引 print(demo2["age"]) # 12 # 位置索引 print(demo2[1]) # 12 # bool索引 print(demo[demo>5]) """ G 6 H 7 I 8 J 9 dtype: int32 """ # 取出索引 demo.index # 取出值 demo.values # 切片 ##连续 print(demo2[:2]) """ name goodDog age 12 dtype: object """ ##离散 print(demo2[[1,2]]) #/ print(demo2[["age", "sex"]]) """ age 12 sex 1 dtype: object """
import pandas as pd import numpy as np #数组创建 demo = pd.DataFrame(np.arange(12).reshape(3,4)) print(demo) """ 0 1 2 3 # columns 列索引 axis = 1 0 0 1 2 3 1 4 5 6 7 2 8 9 10 11 # index axis = 0 行 索 引 """ demo1 = pd.DataFrame(np.arange(12).reshape(3,4),index=list("abc"),columns=list("WXYZ")) print(demo1) """ W X Y Z a 0 1 2 3 b 4 5 6 7 c 8 9 10 11 """ # 字典创建 dataDic = {"name": ["xiaoming", "xiaohong"], "age": [18,18], "tel":[10086,10010]} demo2 = pd.DataFrame(dataDic) print(demo2) """ name age tel 0 xiaoming 18 10086 1 xiaohong 18 10010 """ dataDic1 = [{"name":"xiaoming", "age": 18, "tel":10086}, {"name":"xiaohong", "age": 18, "tel":10010}] demo3 = pd.DataFrame(dataDic1) print(demo3) """ name age tel 0 xiaoming 18 10086 1 xiaohong 18 10010 """ # 行索引 demo3.index # 列索引 demo3.columns #值 demo3.values # 维度 print(demo3.ndim) # 2 #DataFrame整体查询 # 前几行,默认五行 head() demo3.head(2) #前两行 # 末尾几行,默认五行tail() demo3.tail(2) #后两行 #展示概况 print(demo3.info()) """ <class 'pandas.core.frame.DataFrame'> RangeIndex: 2 entries, 0 to 1 Data columns (total 3 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 name 2 non-null object 1 age 2 non-null int64 2 tel 2 non-null int64 dtypes: int64(2), object(1) memory usage: 176.0+ bytes """ # describe()对数字类型快速进行统计 print(demo3.describe()) """ age tel count 2.0 2.000000 mean 18.0 10048.000000 std 0.0 53.740115 min 18.0 10010.000000 25% 18.0 10029.000000 50% 18.0 10048.000000 75% 18.0 10067.000000 max 18.0 10086.000000 """
pandas读取外部数据
import pandas as pd
filePath = r" "
#读取CSV文件
data = pd.read_csv(filePath)
#读取excel文件
data1 = pd.read_excel(filePath)
# 读取剪切板中的数据
data2 = pd.read_clipboard()
# 读取MYSQL中的数据
data3 = pd.read_sql()
pandas取行取列
1. df.loc通过标签索引行数据
2. df.iloc通过位置获取行数据
#取前20行
df[:20]
# 取列
df["name"]
#取行取列
df[:20]["name"]
import pandas as pd import numpy as np demo1 = pd.DataFrame(np.arange(12).reshape(3,4),index=list("abc"),columns=list("WXYZ")) print(demo1) """ W X Y Z a 0 1 2 3 b 4 5 6 7 c 8 9 10 11 """ print(demo1.loc["a", "Z"]) # 3 print(demo1.loc["a"]) #/print(demo1.loc["a",:]) /demo1.iloc[1] """ W 0 X 1 Y 2 Z 3 """ print(demo1.loc[:,"Y"]) /demo1.iloc[:,2] """ a 2 b 6 c 10 """ # 取多行多列 # 不连续 print(demo1.loc[["a", "c"],["W", "Z"]]) /demo1.iloc[[0, 2], [0, 3]] """ W Z a 0 3 c 8 11 """ # 连续 print(demo1.loc["a":"c","W":"Y"])/demo1.iloc[0:2, 0:2] """ W X Y a 0 1 2 b 4 5 6 c 8 9 10 """ # bool索引 # 大于3小于8 demo1[(demo1["W"] > 3)&(demo1["W"] < 8)]
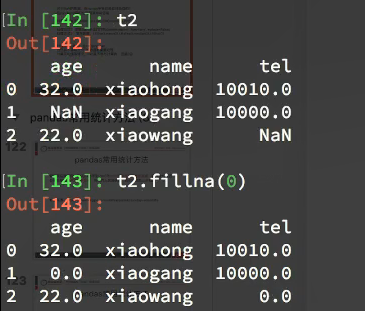
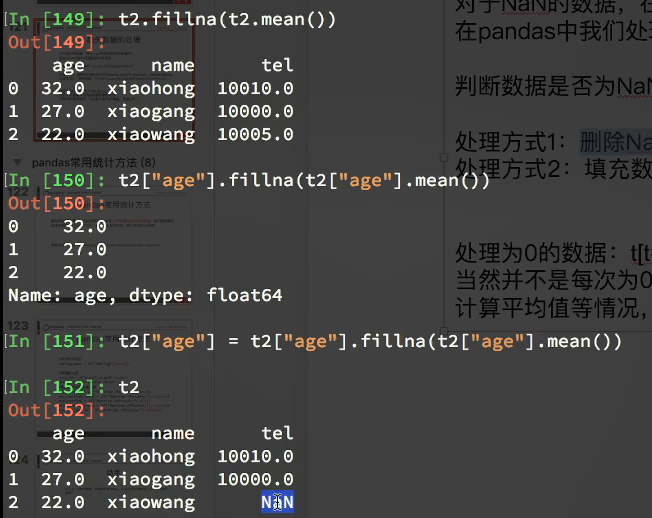
pandas缺失数据的处理
一种是空,None等,在pandas是NaN;另外一种是0。

import pandas as pd import numpy as np demo1 = pd.DataFrame(np.arange(12).reshape(3,4),index=list("abc"),columns=list("WXYZ")) print(demo1) """ W X Y Z a 0 1 2 3 b 4 5 6 7 c 8 9 10 11 """ # 是NaN print(pd.isnull(demo1)) """ W X Y Z a False False False False b False False False False c False False False False """ # 不是NaN print(pd.notnull(demo1)) #选取W列不为NaN的行 print(demo1[pd.notnull(demo1["W"])]) """ W X Y Z a 0 1 2 3 b 4 5 6 7 c 8 9 10 11 """ print(pd.notnull(demo1["W"])) """ a True b True c True Name: W, dtype: bool """
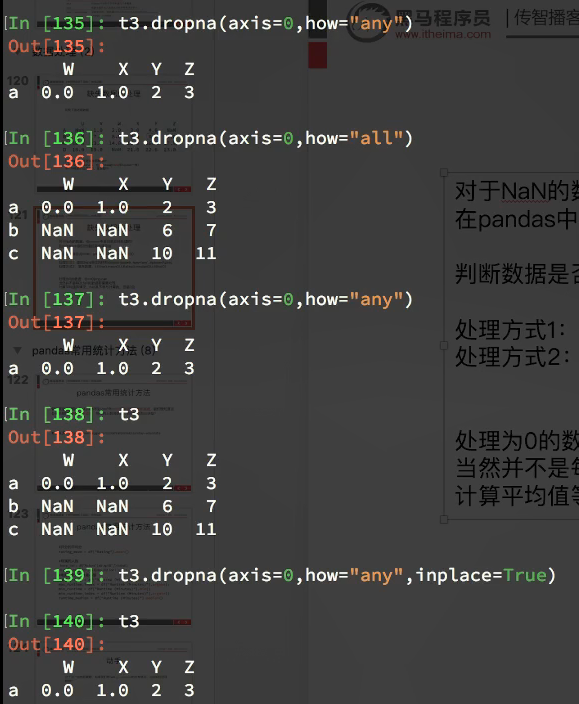
填充数据: