目录
OS模块
os模块---operating system
与操作系统交互,控制文件/文件夹
对文件操作
对文件夹操作
import os
##对文件操作
###判断参数中的具体绝对路径是否为文件
resu = os.path.isfile(r'C:Users龘Desktoppythonpython12期正课day16 est16.py')
print(resu)
resu = os.path.isfile(r'C:Users龘Desktoppythonpython12期正课day16')
print(resu)
###删除文件
#os.remove(r'')
#os.rename(r'',r'')
##对文件夹操作
###判断参数中的具体绝对路径是否为文件夹
#os.path.isdirdir()
###根据参数中的具体绝对路径创建文件夹,如果该具体绝对路径已经有文件夹占用会报错
# os.mkdir(r'C:Users龘Desktoppythonpython12期正课day16 est.dir') #make directory
###删除文件夹
# os.rmdir(r'C:Users龘Desktoppythonpython12期正课day16 est.dir')
###获取文件夹内所有文件的文件名,将每个文件名以字符串形式放入列表中 *****
res = os.listdir(r'C:Users龘Desktoppythonpython12期正课day15')
print(res)
##辅助性的操作
###获取当前文件的所在文件夹的具体绝对路径,不会具体到当前文件名
res = os.getcwd() #current working directory,不需要参数
print(res)
###获取当前文件所在的具体绝对路径,具体到当前文件名
print(__file__) #__file__是pycharm独有,与python解释器无关
print(os.path.abspath(__file__)) #根据不同的操作系统自释义不同的斜杠 /(Linux) 或 (Windows) 以兼容不同的操作系统
###获取当[前文件或文件夹]的上一层文件夹的具体绝对路径,需要[前文件或文件夹]的具体绝对路径作参数
res = os.path.dirname(r'C:Users龘Desktoppythonpython12期正课day16 est.dir est_dir_file.py')
print(res)
res = os.path.dirname(os.path.dirname(r'C:Users龘Desktoppythonpython12期正课day16 est.dir est_dir_file.py'))
print(res)
###将第一个参数中的[文件或文件夹]的具体绝对路径往下一层级拼接,每多一个参数就新加一个层级
res2 = os.path.join(res,'img','test.jpg')
print(res)
###判断参数中的具体绝对路径是否存在(对文件或文件夹都可以可以)
res = os.path.exists(res)
print(res)
res = os.path.exists(res2)
print(res)
##了解内容
###往终端中输入参数中的命令并执行
# os.system('dir')
###生成一个生成器对象,该生成器对象存放以参数中的具体绝对路径为树根的文件夹树,树的每一个分支为一个三元组(包含根节点绝对路径(顶层文件夹具体绝对路径),分支节点相对路径(文件夹名),节点相对路径(文件名)
res = os.walk(r'C:Users龘Desktoppythonpython12期正课') #walk 遍历
print(res)
for i in res:
# print(i)
abs_,k,l = i
# print(abs_) #所有文件夹具体绝对路径
# print(k) #所有文件夹名(以某文件夹作为根文件夹时,下一层级无文件夹时则为空)
# print(l) #所有文件名,每一个层级的文件名放在同一个列表中
for path in l:
res = abs_ + path
print(res)
#给定一个文件夹的具体绝对路径,可以获取该文件夹下所有文件的具体绝对路径,即为每个元组中第一个元素(绝对路径)与第三个元素(相对路径)拼接形成的具体绝对路径 *****
python自动化统计文件代码行数
import os
def count_code(file_path):
count = 0
if not os.walk(file_path):
pass
with open(file_path,'r',encoding='utf8') as fr:
for i in fr:
count += 1
return count
def count_code_all(dir_path):
res = os.walk(dir_path)
count_sum = 0
for i in res:
file_,k,l = i
for path in l:
file_path = os.path.join(file_,path)
if file_path.endswith('py'):
count = count_code(file_path)
count_sum += count
return count_sum
dir_path = input('请输入统计的文件夹/文件绝对路径:')
count_sum = count_code_all(dir_path)
print(count_sum)
sys模块
sys模块---与python解释器交互
import sys
res = sys.argv #argument variable 参数变量
print(res[0])
# print(res[1])
#1.获取运行python文件的时候输入的命令行参数,并且以列表形式存储参数
#2.sys.argv[0]表示代码文件本身绝对路径
import jieba
print(sys.modules) #字典形式打印所有当前导入的模块
print(sys.modules.keys())
request = __import__('requests') #根据给定的字符串导入模块
request.get_data()
json和pickle模块
json模块
import json
dic = {'a':1,'b':None}
res = json.dumps(dic) #json串中没有单引号,因为c中单引号只能放单个字符,可以跨平台交互
print(res)
print(type(res)) #python中json数据类型表示为字符型
res = json.loads(res)
print(type(res))
##常用(*****)
#序列化字典为json串,并保存文件
with open('test.json','w',encoding='utf8') as fw:
json.dump(dic,fw) #dump针对文件,dumps针对内存
#反序列化
with open('test.json','r',encoding='utf8') as fr:
data = json.load(fr)
print(type(data),data) #python集合不能转换成json串
#方便即时读取和修改第三方公用数据库文件
pickle模块
#pickle模块:不跨平台,针对所有python数据类型例如集合/函数(但函数只存了内存地址),使用方式和json一模一样
import pickle
s = {1,2,3}
with open('test.pkl','wb') as fw:
pickle.dump(s,fw) #打开文件用'wb'模式,产生的'pkl'文件不能打开
with open('test.pkl','rb') as fr:
data = pickle.load(fr)
print(type(data),data)
def f():
print('f') #针对地址而言只存了一个函数名,而非函数地址,函数名如果未定义会报错
with open('test.pkl','wb') as fw:
pickle.dump(f,fw)
with open('test.pkl','rb') as fr:
data = pickle.load(fr)
print(type(data),data)
#未来存对象(存对象名) 两者区别很重要(*****)
logging模块
logging模块提供了两种记录日志的方式:
- 第一种方式是使用logging提供的模块级别的函数(V1和V2版本)
- 第二种方式是使用Logging日志系统的四大组件(V3版本)
一.低配logging模块
日志总共分为以下五个级别,这五个级别自下而上进行匹配
debug-->info-->warning-->error-->critical,默认最低级别为warning级别
V1版本
V1版本无法指定日志级别,无法指定日志格式,只能往屏幕打印,无法写入文件.
import logging
logging.debug('调试信息')
logging.info('正常信息')
logging.warning('警告信息')
logging.error('报错信息')
logging.critical('严重错误信息')
V2版本
V2版本添加日志输出信息的基本配置,控制打印到日志文件中,此时控制台无显示,可以看到新生成的basicConfig参数中指定名称的文件,改文件记录了相应的日志信息
import logging
logging.basicConfig(filename='v2版本.log',
format='%(asctime)s - %(name)s - %(levelname)s -%(module)s: %(message)s',
datefmt='%Y-%m-%d %H:%M:%S %p',
level=10)
#logging.basicConfig()函数用于为logging日志系统做一些基本配置
logging.debug('调试信息') # 10
logging.info('正常信息') # 20
logging.warning('警告信息') # 30
logging.error('报错信息') # 40
logging.critical('严重错误信息') # 50
V3版本
V3版本添加日志的配置信息,即可打印到终端,又可打印到文件,而且可以对不同的用户打印不同的日志文件
logging日志模块四大组件
日志器---Logger---提供了应用程序可直接一直使用的接口
处理器---Handler---将logger创建的日志记录发送到合适的目的地(终端或文件)输出
过滤器---Filter---提供了更细粒度的控制工具来决定输出哪条日志记录,丢弃哪条日志记录
格式器---Formatter---决定日志记录的最终输出格式
logging模块就是通过这些组件来完成日志处理的,上面所使用的logging模块级别的函数也是通过这些组件对应的类来实现的
四大组件之间的关系描述
- 日志器(logger)需要通过处理器(handler)将日志信息输出到目标位置,如终端/日志文件
- 不同的处理器(handler)可以将日志输出到不同的位置)
- 日志器(logger)可以设置多个处理器(hanler)将同一条日志记录输出到不同的位置
- 每个处理器(handler)都可以设置自己的格式器(formatter)实现同一条记录以不同的格式输出到不同的地方
总结:简单来说就是:日志器(logger)是入口,真正干活的是处理器(handler),处理器(handler)还可以通过过滤器(filter)做过滤或者通过格式器(formatter)做格式化等处理操作
import logging
fh = logging.FileHandler('V3.log')
sm = logging.StreamHandler()
f_f_standard = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s -%(module)s: %(message)s',
datefmt='%Y-%m-%d %H:%M:%S %p',)
f_f_simple = logging.Formatter('%(asctime)s : %(message)s',
datefmt='%Y-%m-%d %H:%M:%S %p',)
s_f = logging.Formatter('%(name)s %(message)s',)
fh.setFormatter(f_f_standard)
sm.setFormatter(s_f)
logger = logging.getLogger('大帅比蔡启龙')
logger.addHandler(fh)
logger.addHandler(sm)
logger.setLevel(10)
logger.debug('debug')
logger.info('大帅比蔡启龙创建的V3版本日志')
logger.warning('warning')
logger.error('error')
logger.critical('critical')
二.高配logging模块
- 导入
logging.config()方法通过定义一个配置字典来配置logger对象 - 需要导入os模块自定义日志文件路径
- 字典中的格式器控制的具体格式为了简洁需在字典外用变量存储
import os
import logging.config
# 定义三种日志输出格式 开始
standard_format = '[%(asctime)s][%(threadName)s:%(thread)d][task_id:%(name)s][%(filename)s:%(lineno)d]'
'[%(levelname)s][%(message)s]' # 其中name为getLogger()指定的名字;lineno为调用日志输出函数的语句所在的代码行
simple_format = '[%(levelname)s][%(asctime)s][%(filename)s:%(lineno)d]%(message)s'
id_simple_format = '[%(levelname)s][%(asctime)s] %(message)s'
# 定义日志输出格式 结束
logfile_dir = os.path.dirname(os.path.dirname(os.path.abspath(__file__))) # log文件的目录,需要自定义文件路径 # atm
logfile_dir = os.path.join(logfile_dir, 'log') # C:UsersoldboyDesktopatmlog
logfile_name = 'log.log' # log文件名,需要自定义路径名
# 如果不存在定义的日志目录就创建一个
if not os.path.isdir(logfile_dir): # C:UsersoldboyDesktopatmlog
os.mkdir(logfile_dir)
# log文件的全路径
logfile_path = os.path.join(logfile_dir, logfile_name) # C:UsersoldboyDesktopatmloglog.log
# 定义日志路径 结束
# log配置字典
LOGGING_DIC = {
'version': 1,
'disable_existing_loggers': False,
'formatters': {
'standard': {
'format': standard_format
},
'simple': {
'format': simple_format
},
},
'filters': {}, # filter可以不定义
'handlers': {
# 打印到终端的日志
'console': {
'level': 'DEBUG',
'class': 'logging.StreamHandler', # 打印到屏幕
'formatter': 'simple'
},
# 打印到文件的日志,收集info及以上的日志
'default': {
'level': 'INFO',
'class': 'logging.handlers.RotatingFileHandler', # 保存到文件
'formatter': 'standard',
'filename': logfile_path, # 日志文件
'maxBytes': 1024 * 1024 * 5, # 日志大小 5M (*****)
'backupCount': 5,
'encoding': 'utf-8', # 日志文件的编码,再也不用担心中文log乱码了
},
},
'loggers': {
# logging.getLogger(__name__)拿到的logger配置。如果''设置为固定值logger1,则下次导入必须设置成logging.getLogger('logger1')
'': {
# 这里把上面定义的两个handler都加上,即log数据既写入文件又打印到屏幕
'handlers': ['default', 'console'],
'level': 'DEBUG',
'propagate': False, # 向上(更高level的logger)传递
},
},
}
def load_my_logging_cfg():
logging.config.dictConfig(LOGGING_DIC) # 导入上面定义的logging配置
logger = logging.getLogger(__name__) # 生成一个log实例
logger.info('It works!') # 记录该文件的运行状态
return logger
if __name__ == '__main__':
load_my_logging_cfg() #测试配置函数
一个项目是如何从无到有的
UI-->前端-->后端-->测试-->运维
1.需求分析
开发项目前,让客户给提出项目的需求,拿到需求后再提取出一系列功能。
2.程序的架构设计
- 如果进行架构设计,那么程序的耦合度高,维护性低,可扩展性低,要修改某处代码其他耦合代码也需修改
- 项目开发前,应该设计程序,让程序解开耦合,从而提高项目的管理以及开发的效率。
3.分任务开发
- UI:通过一些炫酷的软件外观设计,提高用户对软件的体验感
- 前端:UI只是把外观图设计出来,前端需根据UI的设计图对软件界面进行排版
- 后端(python,高并发go):项目里业务及功能的逻辑处理
4.测试
- 黑盒测试:
- 对用软件的界面进行测试,测试一些能让用户看到的bug,如CF中的卡箱子
- 白盒测试:
- 对进行性能测试,如每秒钟能承受多少用户的访问量
- Unittest:接口测试模块
5.上线运行
- 把测试好的项目交给运维人员部署到服务器上线运行
需求分析
从需求中提取功能,一个需求可能提取一个至多个功能
ATM+购物车 项目需求如下:
- 额度 15000或自定义-->注册功能
- 实现购物商城,买东西加入 购物车,调用信用卡接口结账-->购物车功能,支付功能
- 可以提现,手续费5%-->体现功能
- 支持多账户登录-->登录功能
- 支持账户间转账-->转账功能
- 记录流水-->流水功能
- 提供还款接口-->还款功能
- ATM记录操作日志-->日志功能
- 提供管理接口,包括添加账户、用户额度,冻结账户等...-->管理员功能
- 用户认证功能-->登录认证,首选装饰器
将功能分类
- 展示给用户看的功能
- 登录
- 注册
- 查看余额
- 转账
- 取款
- 查看流水
- 购物
- 查看商品
- 管理员功能
- 退出登录
程序的架构设计
三层主题程序架构
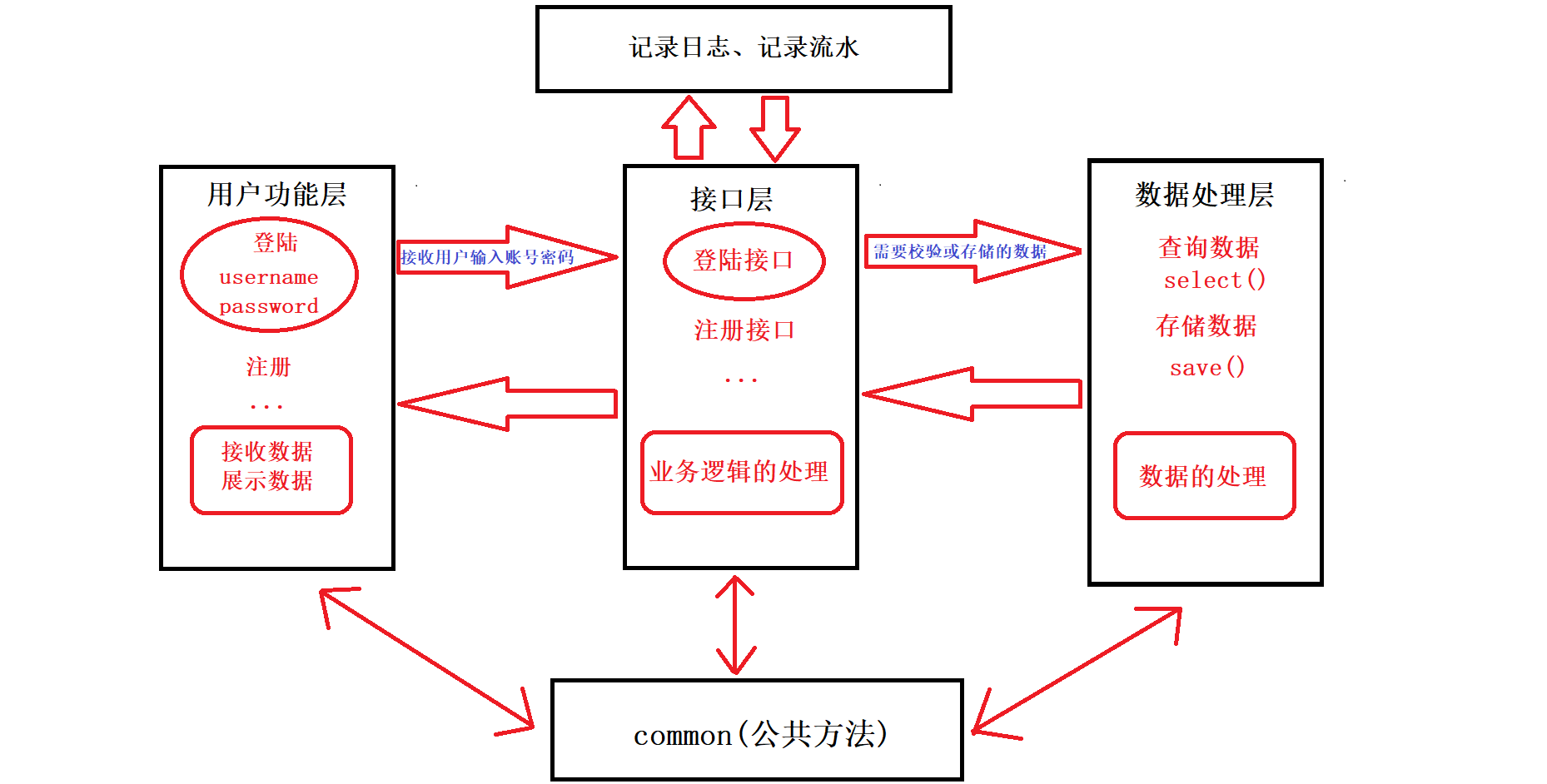
好处
- 逻辑清晰
- 方便即时修改和之后维护
- 所有交互都会经过接口层,日志模块放在接口层可方便记录
程序的目录搭建
常见目录文件(夹)名称及含义
|-- core/ #业务核心文件夹
| |-- src.py # 资源定位文件
|-- api/ #application program interface
| |-- api.py # 接口文件
|-- db/ #data base---数据库(对数据处理)文件夹
| |-- db_handle.py # 操作数据文件
| |-- db.txt # 存储数据文件
|-- lib/ #公共方法库文件夹
| |-- common.py # 共享功能
|-- conf #配置文件夹
| |-- settings.py # 配置相关
|-- bin/ #binary---存放二进制编译结果,即程序运行文件夹
| |-- run.py
'''
程序的启动文件,一般放在项目的根目录下,因为在运行时会默认将运行文件所在的文件夹作为sys.path的第一个路径,这样就省去了处理环境变量的步骤
'''
|-- log/
| |-- log.log # 日志文件
|-- requirements.txt # 存放软件依赖的外部Python包列表
|-- README # 项目说明文件