上一篇文章中,我们讲述了如何用查词典的方法对中文语句分词,但这种方式不能百分百地解决中文分词问题,比如对于未登录词(在已有的词典中,或者训练语料里面没有出现过的词),无法用查词典的方式来切分,这时候可以用隐马尔可夫模型(HMM)来实现。在实际应用中,一般也是将词典匹配分词作为初分手段,再利用其他方法提高准确率。
HMM介绍
隐马尔可夫模型(Hidden Markov Model,HMM)是统计模型,是关于时序的概率图模型,它用来描述一个含有隐含未知参数的马尔可夫过程,即由一个隐藏的马尔可夫链随机生成不可观测的状态随机序列,再由各个状态生成一个观测而产生观测随机序列的过程。序列的每一个位置又可以看作是一个时刻,其结构见下图。其难点是从可观察的参数中确定该过程的隐含参数,然后利用这些参数来作进一步的分析,例如中文分词。
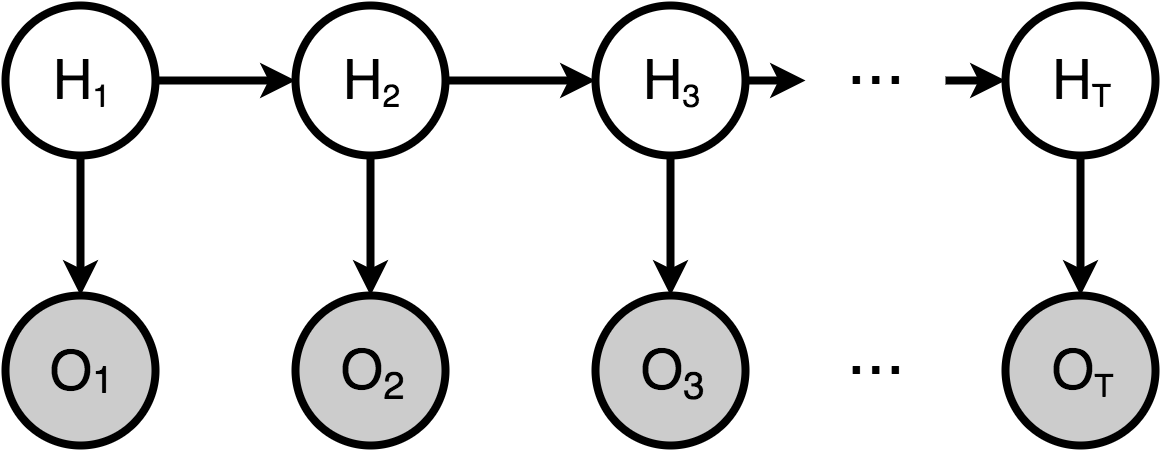
如上图所示,状态序列H可表示为:
假设总共有n个状态,即每个状态序列必为状态集合之一,状态值集合Q为:
观测序列O表示为:
假设观测值总共有m个,则观测值集合为:
一个模型,两个假设,三个问题
1、一个模型
HMM的基本元素可以表示为
Q:状态值集合
V: 观测值集合
π:初始概率分布
A:([a_{ij}]) 状态转移矩阵
B:([b_{j(k)}]) 给定状态下,观测值概率矩阵,即发射矩阵
2、两个假设
- 齐次Markov
即假设观测序列中t时刻的状态,只跟上一时刻t-1有关,
- 观测独立
即每个时刻的观测值只由该时刻的状态值决定
3、三个问题
HMM在实际应用中主要用来解决3类问题:
-
评估问题(概率计算问题)
即给定观测序列 (O=O_{1},O_{2},O_{3}…O_{t})和模型参数λ=(A,B,π),怎样有效计算这一观测序列出现的概率.
(Forward-backward算法) -
解码问题(预测问题)
即给定观测序列(O=O_{1},O_{2},O_{3}…O_{t})和模型参数λ=(A,B,π),怎样寻找满足这种观察序列意义上最优的隐含状态序列S。(viterbi算法,近似算法)
-
学习问题
即HMM的模型参数λ=(A,B,π)未知,如何求出这3个参数以使观测序列(O=O_{1},O_{2},O_{3}…O_{t})的概率尽可能的大.
(即用极大似然估计的方法估计参数,Baum-Welch,EM算法)
HMM模型在中文分词中的应用
在中文分词中,我们经常用sbme的字标注法来标注语料,即通过给每个字打上标签来达到分词的目的,其中s表示single,代表单字成词;b表示begin,代表多字词的开头;m表示middle,代表三个及以上字词的中间部分;e表示end,表示多字词的结尾。这样我是中国人就可以表示为ssbme。
对于字标注的分词方法来说,输入就是n个字,输出就是n个标签。我们用(λ=λ_{1}λ_{2}…λ_{n})(表示输入的句子,)(o=o_{1}o_{2}…o_{n})表示输出。那最优的输出从概率的角度来看,就是求条件概率
即要求上式概率最大,根据独立性假设,即每个字的输出只与当前字有关,上式可表示为:
由bayes定理,
同样地由独立性假设,
由HMM的markov假设:每个输出仅和上一个时刻相关,有
因此,最初的求解可以转化为
其中(P(lambda_{k}|o_{k}))(为发射概率,)(P(o_{k}|o_{k-1}))为转移概率
代码实现
用HMM模型来实现中文分词,状态值集合有四种,分别是 s, b, m, e;观测值集合,即所有汉子;转移状态集合有['ss','sb','bm','be','mm','me','es','eb'], 其他组合都为0,即不可能的情况,比如bs, ms这些状态不可能转移。这里从jieba分词的github下载了一份字典库dict.txt.small,需要的朋友可以去官方github下载。我们先看看该词典的格式
[zhuzf@localhost test]$ head -n 5 dict.txt.small
的 3188252 uj
了 883634 ul
是 796991 v
在 727915 p
和 555815 c
[zhuzf@localhost test]$ tail -n 5 dict.txt.small
龙胜 10 nr
龙蛇混杂 10 i
龙骨山 10 nr
龚松林 10 nr
龟板 10 n
代码实现1:
我们根据这份词典统计每个字是s,b,m,e的发射概率, 计算方法为将词典中所有的一字词都计入s标签下,把多字词的首字都计入b标签下,最后一个字计入e标签下,其余的计入m标签中。此外计算过程中还使用了对数概率,防止溢出;
hmm_model = {i: Counter(i) for i in 'sbme'}
with open('data/dict.txt.small', encoding='utf-8') as f:
for line in f:
lines = line.strip('
').split(' ')
if len(lines[0]) == 1:
hmm_model['s'][lines[0]] += int(lines[1])
else:
hmm_model['b'][lines[0][0]] += int(lines[1])
hmm_model['e'][lines[0][-1]] += int(lines[1])
for m in lines[0][1:-1]:
hmm_model['m'][m] += int(lines[1])
log_total = {i: log(sum(hmm_model[i].values())) for i in 'sbme'}
初始概率,第一个词只可能是b或者s
start_p={'b': -0.26268660809250016,
'e': -3.14e+100,
'm': -3.14e+100,
's': -1.4652633398537678}
转移概率,根据结巴分词的状态转移矩阵prob_trans.p得到, value值为概率对数
P={'B': {'E': -0.510825623765990, 'M': -0.916290731874155},
'E': {'B': -0.5897149736854513, 'S': -0.8085250474669937},
'M': {'E': -0.33344856811948514, 'M': -1.2603623820268226},
'S': {'B': -0.7211965654669841, 'S': -0.6658631448798212}}
trans = {}
for key, values in P.items():
for k,v in values.items():
trans[(key+k).lower()] = v
print(trans)
output
{'be': -0.51082562376599,
'bm': -0.916290731874155,
'eb': -0.5897149736854513,
'es': -0.8085250474669937,
'me': -0.33344856811948514,
'mm': -1.2603623820268226,
'sb': -0.7211965654669841,
'ss': -0.6658631448798212}
viterbi算法, 动态规划算法实现,得到最优路径,即得到概率最大的sbme组合, 对于概率估算,简单采用了加1平滑法,没出现的单字都算1次。
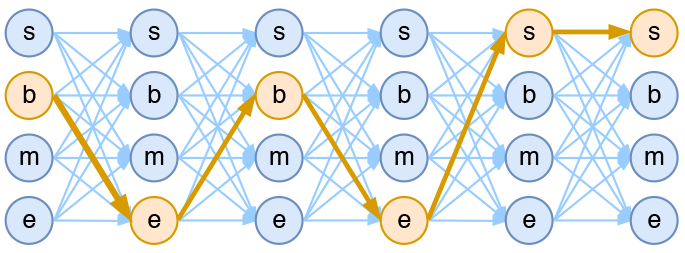
viterbi算法的核心就是,计算如上图序列中每个时刻(此处为token)的最大概率路径,因为每个词都有可能是sbme中的一个,可以减少计算量。比如具有n个词的输入序列,所有可能路径有(4^{n})条,穷举法也可以得到所有路径中概率最大的一条,但是如果隐状态可能取值的个数m太大的话,(m^{n})会变得非常大,从而导致计算量太大。
def viterbi(start_p, nodes, trans):
# paths以字典的方式缓存状态序列,以及概率值,初始位置只有start_p
paths = start_p
# 从第二个词开始计算可能的最大概率路径
for l in range(1, len(nodes)):
paths_ = paths # paths_缓存上一刻的状态
print(paths_)
paths = {}
# 在l时刻,即第l个词的位置,分别对s,b,m,e四种状态值分析,计算在该状态值中最大概率路径,并保存到缓存paths中
for i in nodes[l]:
nows = {} # 当前时刻状态值为i的所有可能路径缓存
# j为所有之前时刻缓存的路径
for j in paths_:
# j[-1]为j路径最后一个状态值,比如j为'bess',判断s+i是否是可能组合,比如se就不可能
if j[-1]+i in trans:
# l时刻下状态值i的路径概率 = 之前路径概率 + token到i的发射概率 + j[-1]i的转移概率
nows[j+i] = paths_[j]+nodes[l][i]+trans[j[-1]+i]
# 选取nows中概率最大的路径
prob_i, path_i = max((v, k) for k,v in nows.items())
paths[path_i] = prob_i
print(paths)
# 求出最后一个字哪一种状态的对应概率最大,最后一个字只可能是两种情况:e(结尾)和s(独立词)
prob, states = max((v, k) for k,v in paths.items() if k[-1] in 'es')
return prob, states
HMM模型,对输入句子做分词
def hmm_cut(s):
# nodes 为输入语句s中每个token分别为sbme的概率
nodes = [{i: log(j[t]+1)-log_total[i] for i, j in hmm_model.items()} for t in s]
_, tags = viterbi(start_p, nodes, trans)
print(tags)
words = [s[0]]
for i in range(1, len(s)):
if tags[i] in ['b', 's']:
words.append(s[i])
else:
words[-1] += s[i]
return words
测试
text = '华为手机深得大家的喜欢'
print(' '.join(hmm_cut(text)))
# '华为 手机 深得 大家 的 喜欢'
text = '王五的老师经常夸奖他'
print(' '.join(hmm_cut(text)))
# '王五 的 老师 经常 夸奖 他'
以第一个语句为例,我们把每个时刻保存的paths打印出来看一下
0: {'b': -0.26268660809250016, 'e': -3.14e+100, 'm': -3.14e+100, 's': -1.4652633398537678}
1: {'ss': -6.7477507587683565, 'sb': -8.514824192919416, 'bm': -7.803021856684376, 'be': -5.779768469237251}
2: {'bes': -13.546372927012078, 'beb': -12.721481505265722, 'bmm': -16.329054443981185, 'bme': -14.38750591207887}
3: {'bess': -22.58204745531191, 'besb': -20.100674738295005, 'bebm': -20.053773324661236, 'bebe': -19.39785648454214}
4: {'bebes': -28.147928301644228, 'bebeb': -26.84139484673273, 'besbm': -29.56559469156299, 'bebme': -28.614871482566265}
5: {'bebess': -34.21920088939125, 'bebesb': -35.64550863881571, 'bebebm': -33.966633148962686, 'bebebe': -33.14651295553467}
6: {'bebebes': -39.29135543196375, 'bebebeb': -38.32672117128855, 'bebebmm': -38.95179717057812, 'bebebme': -39.73898048704186}
7: {'bebebess': -46.54991062378507, 'bebebesb': -46.739964735908735, 'bebebebm': -44.26298344994734, 'bebebebe': -43.90148032305975}
8: {'bebebebes': -46.94960190563267, 'bebebebeb': -52.88266343174185, 'bebebebmm': -52.64274104579346, 'bebebebme': -51.34076405809046}
9: {'bebebebess': -55.923380851692144, 'bebebebesb': -55.24166000635461, 'bebebebebm': -62.67816509870802, 'bebebebmme': -61.51714578556312}
10: {'bebebebesss': -66.66337116442051, 'bebebebessb': -64.60666567893038, 'bebebebesbm': -65.49347468402344, 'bebebebesbe': -63.772287447683404}
tags: bebebebesbe
华为 手机 深得 大家 的 喜欢
可见对于未登录词,王五,HMM模型可以发现这是个人名,分词时组合在一起,而查字典方法做不到。
代码实现2
以下是结巴分词的代码,其实和上面差不多:
hmm_model = {i: Counter(i) for i in 'SBME'}
with open('data/dict.txt.small', encoding='utf-8') as f:
for line in f:
lines = line.strip('
').split(' ')
if len(lines[0]) == 1:
hmm_model['S'][lines[0]] += int(lines[1])
else:
hmm_model['B'][lines[0][0]] += int(lines[1])
hmm_model['E'][lines[0][-1]] += int(lines[1])
for m in lines[0][1:-1]:
hmm_model['M'][m] += int(lines[1])
log_total = {i: log(sum(hmm_model[i].values())) for i in 'SBME'}
# 转移矩阵
trans_p={'B': {'E': -0.510825623765990, 'M': -0.916290731874155},
'E': {'B': -0.5897149736854513, 'S': -0.8085250474669937},
'M': {'E': -0.33344856811948514, 'M': -1.2603623820268226},
'S': {'B': -0.7211965654669841, 'S': -0.6658631448798212}}
# 发射矩阵
emit_p = {i: {t: log(j[t]+1)-log_total[i] for t in j.keys()} for i, j in hmm_model.items()}
# 初始概率
start_p={'B': -0.26268660809250016,
'E': -3.14e+100,
'M': -3.14e+100,
'S': -1.4652633398537678}
# 状态转移集合,比如B状态前只可能是E或S状态
PrevStatus = {
'B': 'ES',
'M': 'MB',
'S': 'SE',
'E': 'BM'
}
MIN_FLOAT = -3.14e100
# HMM模型中文分词中,我们的输入是一个句子(也就是观察值序列),输出是这个句子中每个字的状态值
# HMM的解码问题
def jieba_viterbi(obs, states, start_p, trans_p, emit_p):
V = [{}] # 状态概率矩阵
path = {}
for y in states: # 初始化状态概率
V[0][y] = start_p[y] + emit_p[y].get(obs[0], MIN_FLOAT)
path[y] = [y] # 记录路径
for t in range(1, len(obs)):
V.append({})
newpath = {}
for y in states:
em_p = emit_p[y].get(obs[t], MIN_FLOAT)
# t时刻状态为y的最大概率(从t-1时刻中选择到达时刻t且状态为y的状态y0)
(prob, state) = max([(V[t - 1][y0] + trans_p[y0].get(y, MIN_FLOAT) + em_p, y0) for y0 in PrevStatus[y]])
V[t][y] = prob
newpath[y] = path[state] + [y] # 只保存概率最大的一种路径
path = newpath
# 求出最后一个字哪一种状态的对应概率最大,最后一个字只可能是两种情况:E(结尾)和S(独立词)
(prob, state) = max((V[len(obs) - 1][y], y) for y in 'ES')
return (prob, path[state])
def hmm_cut(s):
# viterbi算法得到sentence 的切分
prob, tags = jieba_viterbi(s, 'SBME', start_p, trans_p, emit_p)
print(tags)
words = [s[0]]
for i in range(1, len(s)):
if tags[i] in ['B', 'S']:
words.append(s[i])
else:
words[-1] += s[i]
return words
测试:
text = '小明硕士毕业于中国科学院计算所'
print(' '.join(hmm_cut(text)))
# >> ['B', 'E', 'B', 'E', 'B', 'M', 'E', 'B', 'E', 'B', 'M', 'E', 'B', 'E', 'S']
# >> '小明 硕士 毕业于 中国 科学院 计算 所'
文章参考:
1、https://blog.csdn.net/sinat_33741547/article/details/78690440
2、https://github.com/ustcdane/annotated_jieba/blob/master/jieba/finalseg/init.py