第五章 排序模型
基于上一章的特征模型来进行后续的处理.
下面使用机器学习模型来对构造好的特征进行学习,然后对测试集进行预测,得到测试集中的每个候选集用户点击的概率;返回点击率最大的top-K个文章,作为最终的结果。
排序阶段选择三个比较有代表性的排序模型,它们分别是:
- LGB的排序模型
- LGB的分类模型
- 深度学习的分类模型DIN
得到了最终的排序模型输出的结果之后,还选择了两种比较经典的模型集成的方法:
- 输出结果加权融合
- Staking(将模型的输出结果再使用一个简单模型进行预测)
00 导包
import numpy as np
import pandas as pd
import pickle
from tqdm import tqdm
import gc, os
import time
from datetime import datetime
import lightgbm as lgb
from sklearn.preprocessing import MinMaxScaler
import warnings
warnings.filterwarnings('ignore')
1.0 LGB排序模型 原理介绍
"""
Learning to Rank(LTR) 的简单介绍
https://blog.csdn.net/wuzhongqiang/article/details/110521519
直接返回一个排序列表,例如用户点击方面的主题--会直接预测最后商品或者文章的一个相对顺序,返回一个排序后的列表.
当然,排序算法也应用于在线广告、协同过滤、多媒体检索等领域。
LGBMRanker模型相对于分类和回归的模型,有几个参数是专门为排序任务定制的:
group: group值的是每个query,在我们这里就是user对应的item列表
eval_group: 与group类似,只不过这个是用在验证集合中的用户item列表
eval_metric: 这里的eval_metric指的就是上面提到的用于优化排序模型的评估指标,默认是使用ndcg
eval_at:这个指的是排序指标中的参数,例如NDCG@5, NDCG@10
"""
"""
相关的LTR算法模型的思路:
此次的新闻推荐中, 我们是根据用户的历史点击来预测最后的一次点击。
而我们最后给出结果的时候, 是给出了最有可能的5篇文章, 这5篇文章我们是按照模型的预测分值score进行排序。
第一个方式就是可以用一个分类模型,训练的时候就根据特征+label的形式训练, 然后直接预测点击概率,把这个当做score进行排序, 这种属于PointWise的方法,因为它的输入和输出呢? 都是基于的单个样本。
而另一个方式呢, 就是排序这里的思路, 我不是基于单个的样本进行训练和预测, 而是针对一个query(用户)对应的所有点击行为, 我预测的是这些点击行为与对应的用户信息的一个相关度排序列表; 训练的时候这里的训练集就变成了一个query对应的所有点击行为的特征(这算是一个样本了), 而label变成了这些点击行为与query的一个相关度排序列表。 通过这个去计算损失,然后优化模型。 这是一种Listwise Approach,LGBMRanker基于排序的思路去做的。
当然中间还有种PointWise的方法,这个看名字也知道,这个是预测某个query对应的点击行为里面两两之间的一个相对顺。
"""
1.1 LGB排序模型 示例
# 定义特征列
lgb_cols = ['sim0', 'time_diff0', 'word_diff0','sim_max', 'sim_min', 'sim_sum',
'sim_mean', 'score','click_size', 'time_diff_mean', 'active_level',
'click_environment','click_deviceGroup', 'click_os', 'click_country',
'click_region','click_referrer_type', 'user_time_hob1', 'user_time_hob2',
'words_hbo', 'category_id', 'created_at_ts','words_count']
# 排序模型分组
trn_user_item_feats_df_rank_model = None # 演示
val_user_item_feats_df_rank_model = None # 演示
trn_user_item_feats_df_rank_model.sort_values(by=['user_id'], inplace=True)
g_train = trn_user_item_feats_df_rank_model.groupby(['user_id'], as_index=False).count()["label"].values
g_val = val_user_item_feats_df_rank_model.groupby(['user_id'], as_index=False).count()["label"].values
# 排序模型定义
lgb_ranker = lgb.LGBMRanker(boosting_type='gbdt', num_leaves=31, reg_alpha=0.0, reg_lambda=1,
max_depth=-1, n_estimators=100, subsample=0.7, colsample_bytree=0.7, subsample_freq=1,
learning_rate=0.01, min_child_weight=50, random_state=2018, n_jobs= 16)
1.2 LGB排序模型
# 模型预测
tst_user_item_feats_df = None # 演示
tst_user_item_feats_df['pred_score'] = lgb_ranker.predict(tst_user_item_feats_df[lgb_cols], num_iteration=lgb_ranker.best_iteration_)
#%% 排序训练模型
val_user_item_feats_df_rank_model = None # 暂缺
g_val = None #
lgb_ranker.fit(trn_user_item_feats_df_rank_model[lgb_cols], trn_user_item_feats_df_rank_model['label'], group=g_train,
eval_set=[(val_user_item_feats_df_rank_model[lgb_cols], val_user_item_feats_df_rank_model['label'])],
eval_group= [g_val], eval_at=[1, 2, 3, 4, 5], eval_metric=['ndcg', ], early_stopping_rounds=50, )
# 将这里的排序结果保存一份,用户后面的模型融合
tst_user_item_feats_df[['user_id', 'click_article_id', 'pred_score']].to_csv('save_path' + 'lgb_ranker_score.csv', index=False)
# 预测结果重新排序, 及生成提交结果
rank_results = tst_user_item_feats_df[['user_id', 'click_article_id', 'pred_score']]
rank_results['click_article_id'] = rank_results['click_article_id'].astype(int)
# submit(rank_results, topk=5, model_name='lgb_ranker')
# 还支持五折交叉验证,这里的五折交叉是以用户为目标进行五折划分
"""
这里省去
"""
2.0 LGB分类模型
基本同回归模型,只输出0,1;预测每篇文章是否点击,
2.1 LGB的分类模型及参数的定义
模型及参数的定义
lgb_Classfication = lgb.LGBMClassifier(boosting_type='gbdt', num_leaves=31, reg_alpha=0.0, reg_lambda=1,
max_depth=-1, n_estimators=500, subsample=0.7, colsample_bytree=0.7, subsample_freq=1,
learning_rate=0.01, min_child_weight=50, random_state=2018, n_jobs= 16, verbose=10)
3.0 DIN 模型
- DIN的全称是Deep Interest Network,可以通过考虑【给定的候选广告】和【用户的历史行为】的相关性,来计算用户兴趣的表示向量。
- DIN具体来说就是通过引入局部激活单元,通过软搜索历史行为的相关部分来关注相关的用户兴趣,并采用加权和来获得有关候选广告的用户兴趣的表示。与候选广告相关性较高的行为会获得较高的激活权重,并支配着用户兴趣。该表示向量在不同广告上有所不同,大大提高了模型的表达能力。
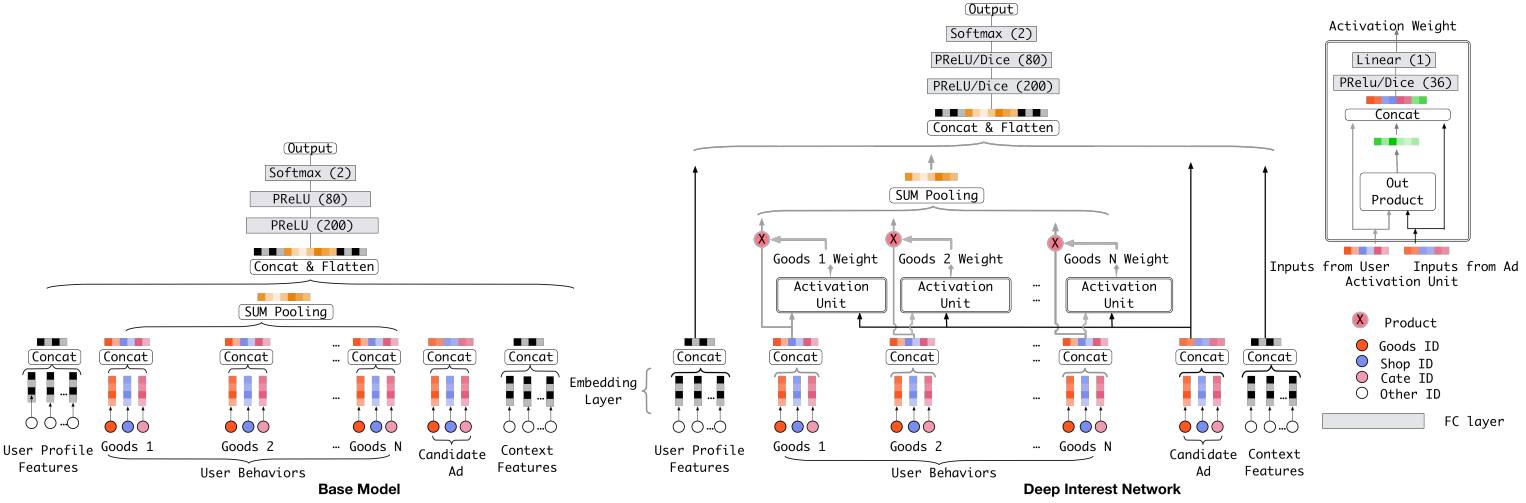
3.1 直接调包使用DIN
def DIN(dnn_feature_columns, history_feature_list, dnn_use_bn=False,
dnn_hidden_units=(200, 80), dnn_activation='relu', att_hidden_size=(80, 40), att_activation="dice",
att_weight_normalization=False, l2_reg_dnn=0, l2_reg_embedding=1e-6, dnn_dropout=0, seed=1024,
task='binary'):
"""
- dnn_feature_columns: 特征列, 包含数据所有特征的列表
- history_feature_list: 用户历史行为列, 反应用户历史行为的特征的列表
- dnn_use_bn: 是否使用BatchNormalization
- dnn_hidden_units: 全连接层网络的层数和每一层神经元的个数, 一个列表或者元组
- dnn_activation_relu: 全连接网络的激活单元类型
- att_hidden_size: 注意力层的全连接网络的层数和每一层神经元的个数
- att_activation: 注意力层的激活单元类型
- att_weight_normalization: 是否归一化注意力得分
- l2_reg_dnn: 全连接网络的正则化系数
- l2_reg_embedding: embedding向量的正则化稀疏
- dnn_dropout: 全连接网络的神经元的失活概率
- task: 任务, 可以是分类, 也可是是回归
"""
more 模型融合
同之前的内容,略