引言:
MySQL存储引擎主要分为 InnoDB 存储引擎与 MyISAM 存储引擎。都采用B+数的存储结构。
应用场景:
InnoDB适合:(1)可靠性要求比较高,要求事务;(2)大量 insert 和 update 。
MyISAM适合:(1)没有事务。(2)插入不频繁,大量 select 。
一、 InnoDB 存储引擎
InnoDB 存储引擎是MySQL 的默认事物型引擎,是使用最广泛的存储引擎,采用聚簇索引。
1.支持ACID的事务,支持事务的四种隔离级别。
2.支持行级锁(默认),也支持表级索。
3. 主键索引采用聚簇索引(索引的数据域存储数据文件本身key+行记录),辅索引的数据域存储主键的值;因此从辅索引查找数据,需要先通过辅索引找到主键值,再访问辅索引;最好使用自增主键,防止插入数据时,为维持B+树结构,文件的大调整。
4. 不保存表的总行数
二、 MyISAM 存储引擎
MyISAM 存储引擎是MySQL最早的存储引擎之一,采用非聚簇索引,没有事物和行级锁。MyISAM对整张表加锁,读取时加共享锁,写入时加排他锁。
1. 不支持事物。
2. 支持表级锁,不支持行级锁。
3.采用非聚簇索引,索引文件的数据域存储指向数据文件的指针。辅索引与主索引基本 一致,但是辅索引不用保证唯一性。
4. 保存总行数,MyISAM:select count(*) from table,MyISAM只要简单的读出保存好的行数,注意的是,当count(*)语句包含 where条件时,两种表的操作是一样的
三、聚簇索引与非聚簇索引的区别
1. 聚簇索引的顺序就是数据的物理存储顺序,所以一个表最多只能有一个聚簇索引。如InnoDB主索引。
2. 非聚集索引中的逻辑顺序并不等同于表中行的物理顺序,索引是指向表中行的位置的指针。如MyISAM 主索引与辅索引。
四、索引的实现
1. InnoDB 索引的实现
InnoDB 采用B+ 树的存储结构,树的叶子节点保存了完整的数据记录,该行记录。
InnoDB的辅助索引data域存储相应记录主键的值而不是地址。
辅助索引搜索需要检索两遍索引:首先检索辅助索引获得主键,然后用主键到主索引中检索获得记录。
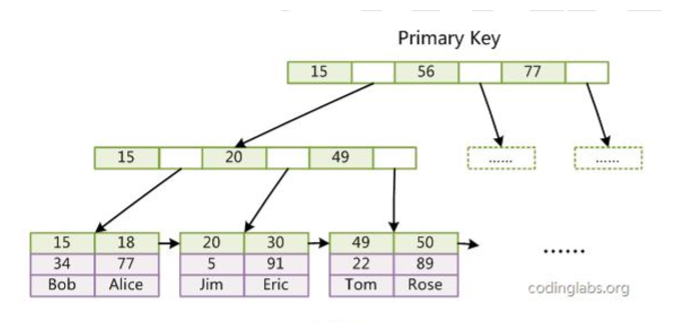
图1. 主索引
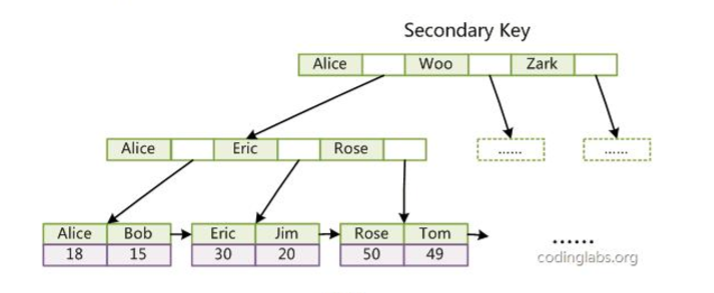
图2. 辅索引
2. MyISAM 索引的实现
MyISAM 存储引采用的是 B+ 树的数据结构。
叶节点的data域存放的是数据记录的地址。
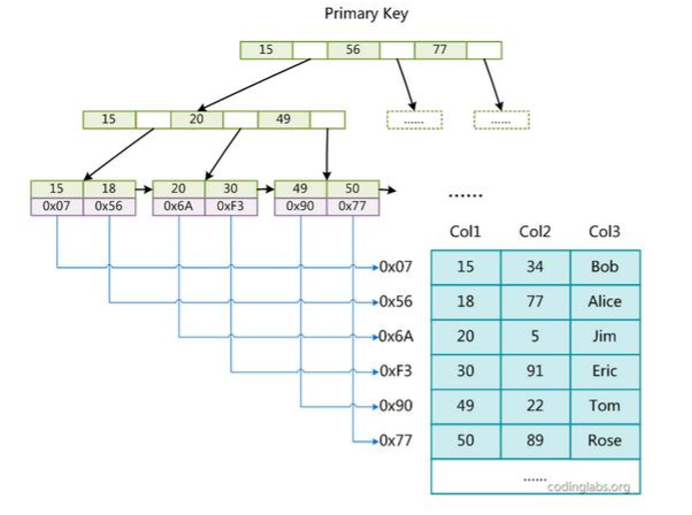
图3. 主键索引
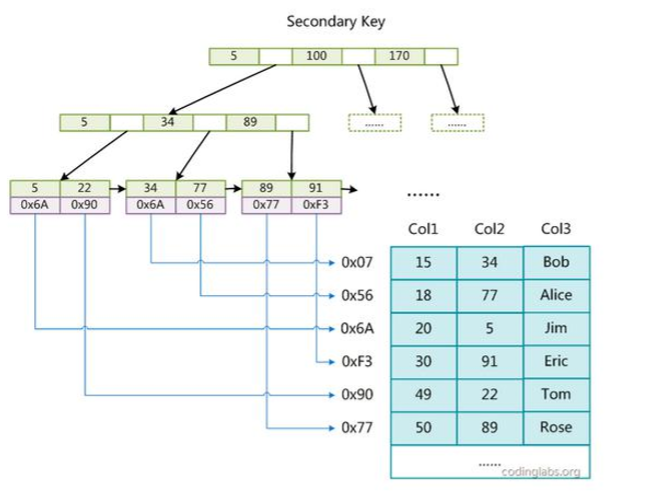
图4. 辅助索引
五、InnoDB 与 MyISAM 索引的区别
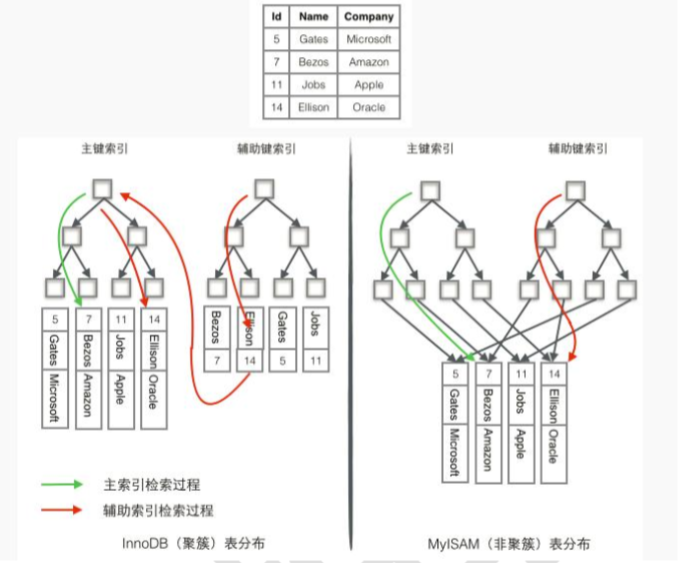
1. InnoDB 使用的是聚簇索引,将主键组织到一棵 B+树中,而行数据就储存在叶子节 点上,若使用"whereid=14"这样的条件查找主键,则按照 B+树的检索算法即可查找到 对应的叶节点,之后获得行数据。若对 Name 列进行条件搜索,则需要两个步骤:第一步 在辅助索引 B+树中检索 Name,到达其叶子节点获取对应的主键。第二步使用主键在主 索引 B+树种再执行一次 B+树检索操作,最终到达叶子节点即可获取整行数据。
2. MyISM 使用的是非聚簇索引,非聚簇索引的两棵 B+树看上去没什么不同,节点 的结构完全一致只是存储的内容不同而已,主键索引 B+树的节点存储了主键,辅助键索引 B+树存储了辅助键。表数据存储在独立的地方,这两颗 B+树的叶子节点都使用一个地址 指向真正的表数据,对于表数据来说,这两个键没有任何差别。由于索引树是独立的,通
过辅助键检索无需访问主键的索引树。
为了更形象说明这两种索引的区别,我们假想一个表如下图存储了 4 行数据。其中 Id 作为主索引,Name 作为辅助索引。图示清晰的显示了聚簇索引和非聚簇索引的差异。