需求:并发检测1000台web服务器状态(或者并发为1000台web服务器分发文件等)如何用shell实现?
方案一:(这应该是大多数人都第一时间想到的方法吧)
思路:一个for循环1000次,顺序执行1000次任务。
实现:

#!/bin/bash
start_time=`date +%s` #定义脚本运行的开始时间
for ((i=1;i<=1000;i++))
do
sleep 1 #sleep 1用来模仿执行一条命令需要花费的时间(可以用真实命令来代替)
echo 'success'$i;
done
stop_time=`date +%s` #定义脚本运行的结束时间
echo "TIME:`expr $stop_time - $start_time`"
运行结果:
[root@iZ94yyzmpgvZ ~]# . test.sh success1 success2 success3 success4 success5 success6 success7 ........此处省略 success999 success1000 TIME:1000
代码解析以及问题:
一个for循环1000次相当于需要处理1000个任务,循环体用sleep 1代表运行一条命令需要的时间,用success$i来标示每条任务.
这样写的问题是,1000条命令都是顺序执行的,完全是阻塞时的运行,假如每条命令的运行时间是1秒的话,那么1000条命令的运行时间是1000秒,效率相当低,而我的要求是并发检测1000台web的存活,如果采用这种顺序的方式,那么假如我有1000台web,这时候第900台机器挂掉了,检测到这台机器状态所需要的时间就是900s!
所以,问题的关键集中在一点:如何并发
方案二:
思路:一个for循环1000次,循环体里面的每个任务都放入后台运行(在命令后面加&符号代表后台运行)。
实现:
#!/bin/bash
start=`date +%s` #定义脚本运行的开始时间
for ((i=1;i<=1000;i++))
do
{
sleep 1 #sleep 1用来模仿执行一条命令需要花费的时间(可以用真实命令来代替)
echo 'success'$i;
}& #用{}把循环体括起来,后加一个&符号,代表每次循环都把命令放入后台运行
#一旦放入后台,就意味着{}里面的命令交给操作系统的一个线程处理了
#循环了1000次,就有1000个&把任务放入后台,操作系统会并发1000个线程来处理
#这些任务
done
wait #wait命令的意思是,等待(wait命令)上面的命令(放入后台的)都执行完毕了再
#往下执行。
#在这里写wait是因为,一条命令一旦被放入后台后,这条任务就交给了操作系统
#shell脚本会继续往下运行(也就是说:shell脚本里面一旦碰到&符号就只管把它
#前面的命令放入后台就算完成任务了,具体执行交给操作系统去做,脚本会继续
#往下执行),所以要在这个位置加上wait命令,等待操作系统执行完所有后台命令
end=`date +%s` #定义脚本运行的结束时间
echo "TIME:`expr $end - $start`"
运行结果:
[root@iZ94yyzmpgvZ /]# . test1.sh
......
[989] Done { sleep 1; echo 'success'$i; }
[990] Done { sleep 1; echo 'success'$i; }
success992
[991] Done { sleep 1; echo 'success'$i; }
[992] Done { sleep 1; echo 'success'$i; }
success993
[993] Done { sleep 1; echo 'success'$i; }
success994
success995
[994] Done { sleep 1; echo 'success'$i; }
success996
[995] Done { sleep 1; echo 'success'$i; }
[996] Done { sleep 1; echo 'success'$i; }
success997
success998
[997] Done { sleep 1; echo 'success'$i; }
success999
[998] Done { sleep 1; echo 'success'$i; }
[999]- Done { sleep 1; echo 'success'$i; }
success1000
[1000]+ Done { sleep 1; echo 'success'$i; }
TIME:2
代码解析以及问题:
shell中实现并发,就是把循环体的命令用&符号放入后台运行,1000个任务就会并发1000个线程,运行时间2s,比起方案一的1000s,已经非常快了。
可以看到输出结果success4 ...success3完全都是无序的,因为大家都是后台运行的,这时候就是cpu随机运行了,所以并没有什么顺序
这样写确实可以实现并发,然后,大家可以想象一下,1000个任务就要并发1000个线程,这样对操作系统造成的压力非常大,它会随着并发任务数的增多,操作系统处理速度会变慢甚至出现其他不稳定因素,就好比你在对nginx调优后,你认为你的nginx理论上最大可以支持1w并发了,实际上呢,你的系统会随着高并发压力会不断攀升,处理速度会越来越慢(你以为你扛着500斤的东西你还能跑的跟原来一样快吗)
方案三:
思路:基于方案二,使用linux管道文件特性制作队列,控制线程数目
知识储备:
一.管道文件
1:无名管道(ps aux | grep nginx)
2:有名管道(mkfifo /tmp/fd1)
有名管道特性:
1.cat /tmp/fd1(如果管道内容为空,则阻塞)
实验:
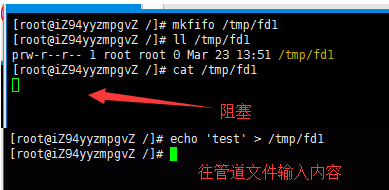
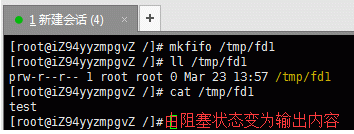
2.echo "test" > /tmp/fd1(如果没有读管道的操作,则阻塞)
总结:
利用有名管道的上述特性就可以实现一个队列控制了
你可以这样想:一个女士公共厕所总共就10个蹲位,这个蹲位就是队列长度,女厕 所门口放着10把药匙,要想上厕所必须拿一把药匙,上完厕所后归 还药匙,下一个人就可以拿药匙进去上厕所了,这样同时来了1千
位美女上厕所,那前十个人抢到药匙进去上厕所了,后面的990人 需要等一个人出来归还药匙才可以拿到药匙进去上厕所,这样10把药匙就实现了控制1000人上厕所的任务(os中称之为信号量)
二.文件描述符
1.管道具有存一个读一个,读完一个就少一个,没有则阻塞,放回的可以重复取,这正是队列特性,但是问题是当往管道文件里面放入一段内容,没人取则会阻塞,这样你永远也没办法往管道里面同时放入10段内容(想当与10把药匙),解决这个问题的关键就是文件描述符了。
2. mkfifo /tmp/fd1
创建有名管道文件exec 3<>/tmp/fd1,创建文件描述符3关联管道文件,这时候3这个文件描述符就拥有了管道的所有特性,还具有一个管道不具有的特性:无限存不阻塞,无限取不阻塞,而不用关心管道内是否为空,也不用关心是否有内容写入引用文件描述符: &3可以执行n次echo >&3 往管道里放入n把钥匙
exec命令用法:http://blog.sina.com.cn/s/blog_7099ca0b0100nby8.html
实现:
#!/bin/bash
start_time=`date +%s` #定义脚本运行的开始时间
[ -e /tmp/fd1 ] || mkfifo /tmp/fd1 #创建有名管道
exec 3<>/tmp/fd1 #创建文件描述符,以可读(<)可写(>)的方式关联管道文件,这时候文件描述符3就有了有名管道文件的所有特性
rm -rf /tmp/fd1 #关联后的文件描述符拥有管道文件的所有特性,所以这时候管道文件可以删除,我们留下文件描述符来用就可以了
for ((i=1;i<=10;i++))
do
echo >&3 #&3代表引用文件描述符3,这条命令代表往管道里面放入了一个"令牌"
done
for ((i=1;i<=1000;i++))
do
read -u3 #代表从管道中读取一个令牌
{
sleep 1 #sleep 1用来模仿执行一条命令需要花费的时间(可以用真实命令来代替)
echo 'success'$i
echo >&3 #代表我这一次命令执行到最后,把令牌放回管道
}&
done
wait
stop_time=`date +%s` #定义脚本运行的结束时间
echo "TIME:`expr $stop_time - $start_time`"
exec 3<&- #关闭文件描述符的读
exec 3>&- #关闭文件描述符的写
运行结果:
[root@iZ94yyzmpgvZ /]# . test2.sh
success4
success6
success7
success8
success9
success5
......
success935
success941
success942
......
success992
[992] Done { sleep 1; echo 'success'$i; echo 1>&3; }
success993
[993] Done { sleep 1; echo 'success'$i; echo 1>&3; }
success994
[994] Done { sleep 1; echo 'success'$i; echo 1>&3; }
success998
success999
success1000
success997
success995
success996
[995] Done { sleep 1; echo 'success'$i; echo 1>&3; }
TIME:101
代码解析以及问题:
两个for循环,第一个for循环10次,相当于在女士公共厕所门口放了10把钥匙,第二个for
循环1000次,相当于1000个人来上厕所,read -u3相当于取走一把药匙,{}里面最后一行代码echo >&3相当于上完厕所送还药匙。
这样就实现了10把药匙控制1000个任务的运行,运行时间为101s,肯定不如方案二快,但是比方案一已经快很多了,这就是队列控制同一时间只有最多10个线程的并发,既提高了效率,又实现了并发控制。
注意:创建一个文件描述符exec 3<>/tmp/fd1 不能有空格,代表文件描述符3有可读(<)可写(>)权限,注意,打开的时候可以写在一起,关闭的时候必须分开关,exec 3<&-关闭读,exec 3>&-关闭写