1.逻辑回归是怎么防止过拟合的?为什么正则化可以防止过拟合?(大家用自己的话介绍下)
什么是过拟合?关于这个百度了一下,知乎上有一些很有趣的回答(https://www.zhihu.com/question/32246256)
就像是我们高三在刷题的过程中,你刷遍了所有的题,但考试的时候改了点数字你就做不出来了,你刷题刷出来的做题模式就类似一个过拟合的模型。
过拟合产生的原因在于数据量太少而变量过多,虽然可以拟合所有数据样本,但拟合出来的模型曲线比较曲折,无法对其他的数据做出正确的预测(以下图片来自https://blog.csdn.net/quiet_girl/article/details/70243583)
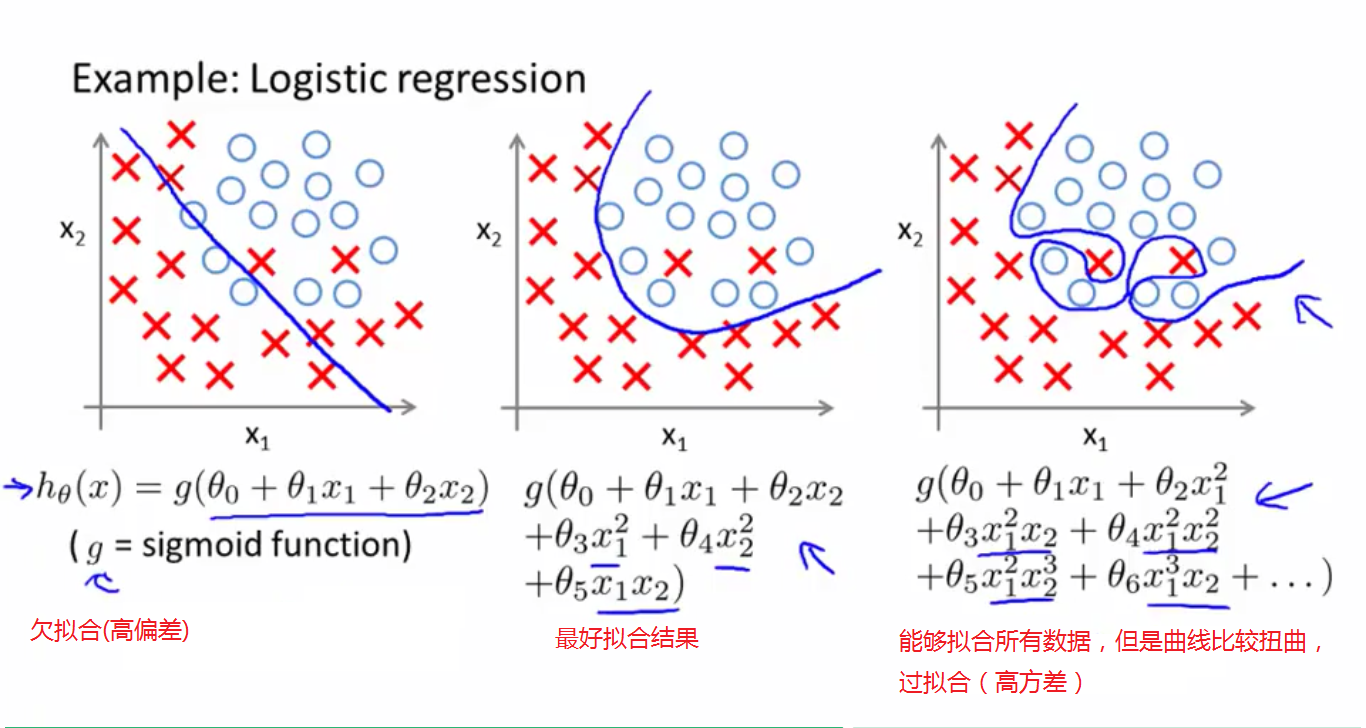
知晓什么是过拟合及造成过拟合的原因后,该怎么去防止过拟合呢?
针对造成的原因,可以通过增大数据量并手动减少特征数,但在舍弃特征也会丢掉有用的信息。因此,我们通过引入一个λ来降低θ的值,来减少不重要的特征值对拟合的影响,即正则化,但我们不惩罚θ0,因为 照约定θ0是最大的。具体如下图所示:

λ的值要适当,太大会造成欠拟合。
2.用logiftic回归来进行实践操作,数据不限。
import pandas as pd from sklearn.model_selection import train_test_split from sklearn.preprocessing import StandardScaler from sklearn.metrics import classification_report from sklearn.linear_model import LogisticRegression
逻辑回归应用:
def logistic(): # 读取数据 data = pd.read_csv('./titanic_data.csv') # 数值型转换,性别女为0 男为1,有缺失值的行直接删除,删除我觉得毫无影响的id列 data.loc[data['Sex'] == 'male', 'Sex'] = 0 data.loc[data['Sex'] == 'female', 'Sex'] = 1 data = data.dropna() data = data.drop(columns=["PassengerId"],axis = 1) print(data) # 训练集和测试集划分 x_train, x_test, y_train, y_test = train_test_split(data.iloc[:, 1:], data.iloc[:, 0], test_size=0.3) # 特征值和目标值进行标准化处理(需要分别处理),实例标准化API std = StandardScaler() x_train = std.fit_transform(x_train) x_test = std.transform(x_test) # 逻辑回归预测 lg = LogisticRegression() lg.fit(x_train, y_train) print(lg.coef_) lg_predict = lg.predict(x_test) print('准确率:', lg.score(x_test, y_test)) print('召回率:', classification_report(y_test, lg_predict, target_names=['生还', '离世'])) if __name__ == '__main__': logistic();
结果:
