单表查询语法:
select 字段1,字段2... from 表名
where 条 件
group by field
having 筛选
order by 字段
limit
限制条数 关键字的优先级:from > where > group by > having > select > distinct > order by > limit;
1.找到表:from
2.拿着where指定的约束条件,去文件/表中取出一条条记录
3.将取出的一条条记录进行分组group by,如果没有group by,则整体作为一组
4.按照select后的字段得到一张新的虚拟表,如果有聚合函数,则将组内数据进行聚合
5.将4的结果过滤:having,如果有聚合函数也是先执行聚合再having过滤
6.查出结果:select
7.去重 distinct
8.将结果按条件排序:order by desc(降序,默认升序)
9.限制结果的显示条数 limit
where是一种约束条件,mysql会拿着where指定的条件去表中取数据,而having则是在取出数据后进行过滤.
where字句中可以使用:
1. 比较运算符:> < >= <= <> !=
2. between 80 and 100 值在10到20之间
3. in(80,90,100) 值是10或20或30
4. like '王%'
可以是%或_,
%表示任意多字符
_表示一个字符
5. 逻辑运算符:在多个条件直接可以使用逻辑运算符 and or not
group by 分组查询:以按照任意字段分组,但分完组后,只能查看分组的那个字段,要想取的组内的其他字段信息,需要借助函数。


聚合函数:
group_concat 只跟group by 连用 查看分组后的组内成员
count() 统计成员个数
avg() 计算平均值
sum() 计算和
max() 找到最大值
min() 找到最小值
having 过滤:
执行优先级从高到低:where > group by > 聚合函数 > having
1. Where 是一个约束声明,使用Where约束来自数据库的数据,Where是在结果返回之前起作用的(先找到表,按照where的约束条件,从表(文件)中取出数据),Where中不能使用聚合函数。
2. Having是一个过滤声明,是在查询返回结果集以后对查询结果进行的过滤操作(先找到表,按照where的约束条件,从表(文件)中取出数据,然后group by分组,如果没有group by则所有记录整体为一组,然后执行聚合函数,然后使用having对聚合的结果进行过滤),在Having中可以使用聚合函数。
3. having可以放到group by之后,而where只能放到group by之前
4. 在查询过程中聚合语句(sum,min,max,avg,count)要比having子句优先执行。而where子句在查询过程中执行优先级高于聚合语句。
order by 排序

限制查询的记录数:limit
多表连接查询:
内连接:..... inner join...on 连接条件........
左连接:....... left join... on 连接条件.,.......
右连接:....... right join ... on 连接条件....
全连接:......union.........
子查询:
1:子查询是将一个查询语句嵌套在另一个查询语句中。
2:内层查询语句的查询结果,可以为外层查询语句提供查询条件。
3:子查询中可以包含:IN、NOT IN、ANY、ALL、EXISTS 和 NOT EXISTS等关键字
4:还可以包含比较运算符:= 、 !=、> 、< 等
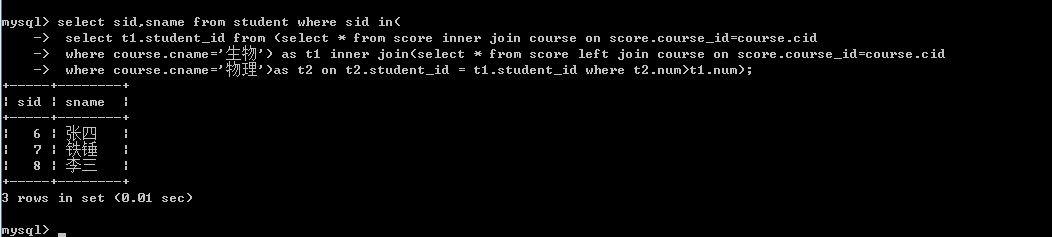
附:连接查询跟子查询同时查询题一道
查询物理课程比生物课程高的学生的姓名和学号