HashMap深入浅出
HashMap数据结构
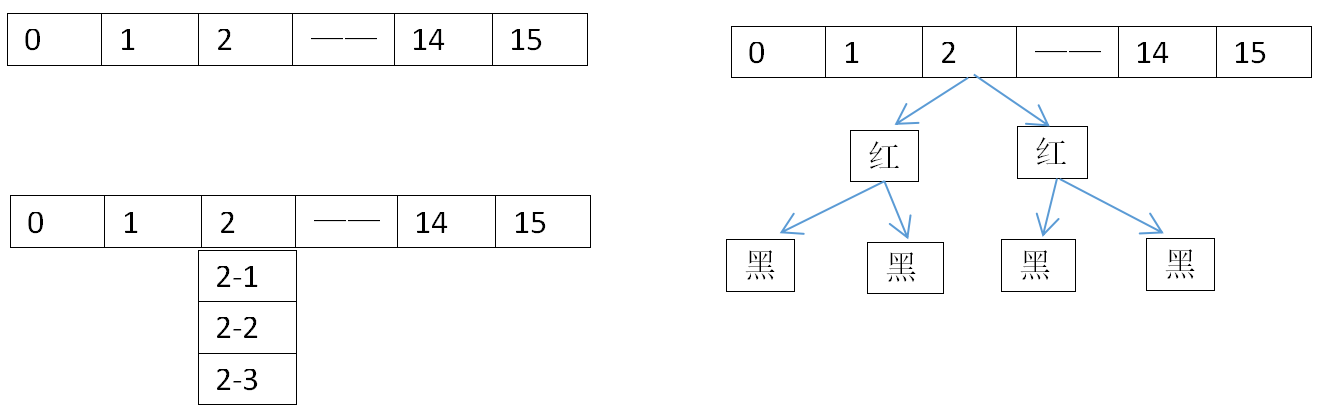
HashMap的本质就是一个数组加链表,数组默认长度是16,存储的元素达到总长度的75%就会扩容一倍。map.put(key,val),实际上就是根据hash散列对数组长度取模,来均匀的打到每一个下标上,填满数组每个下标位。但世事不可能这么完美,可能两个元素经过hash取模后下标会一样,为了避免hash冲突,hashmap就维护了一个链接的数据结构,相同下标的元素存到一个链表中。但是这样get(key)的时候会有一个问题,如果仅仅只是get数组上的元素速度会很快,但是get链表上的元素就会非常耗时,假使链表的深度为n,那么get所需的时间复杂度就是O(N),所以jdk1.8的时候做了一个优化,就是在原有的数据结构中加了一个红黑树,当链表的长度>=8时,会转成红黑树。
为何初始容量要是2的整数次幂
/** * The default initial capacity - MUST be a power of two. */ static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16 这是jdk8中的初始容量,同时告诉我们默认的初始容量-必须是2的幂。可是我们创建 HashMap<String,String> map = new HashMap<String,String>(7); 也不会报错啊。实际上在初始化时,通过下面的代码它会初始化成一个大于我们值,且最接近它的一个2的幂次方。比如我们指定的7,那么它的初始值就是8,我们指定17那么初始值就是32。 /** * Returns a power of two size for the given target capacity. */ static final int tableSizeFor(int cap) { int n = cap - 1; n |= n >>> 1; n |= n >>> 2; n |= n >>> 4; n |= n >>> 8; n |= n >>> 16; return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1; } 那么问题就来了,为什么jdk8非要转一下呢?就用默认值难道不香吗? 其实我们在put(key,value)的时候点进去开一下源码就知道了,它其实是通过位与运算来计算出下标的,这样的效率比取模更高。当然这和初始长度为什么是2的整次幂没关系,但如果长度不是2的整数次幂的话,位与运算和取模运算的出来的下标就会不一样,所以这也是jdk8的高明之处。
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
/** * Returns index for hash code h. */ static int indexFor(int h, int length) { return h & (length - 1); }
HashMap的加载因子
加载因子为什么是0.75?这里面其实就涉及到 时间复杂度和空间复杂度的平衡。因为loadfactor为1的话,这意味着一定要把整个数组填满才扩容,正常情况下是很难填满的,肯定会有很多hash碰撞,导致链表太长。如果loadfactor为0.5的话,数组填充一半就扩容,又会对空间利用率不高。所以取一个折中值0.75
JDK8对hashmap数据结构的优化
/** * nodes in bins follows a Poisson distribution * (http://en.wikipedia.org/wiki/Poisson_distribution) with a * parameter of about 0.5 on average for the default resizing * threshold of 0.75, although with a large variance because of * resizing granularity. Ignoring variance, the expected * occurrences of list size k are (exp(-0.5) * pow(0.5, k) / * factorial(k)). The first values are: * * 0: 0.60653066 * 1: 0.30326533 * 2: 0.07581633 * 3: 0.01263606 * 4: 0.00157952 * 5: 0.00015795 * 6: 0.00001316 * 7: 0.00000094 * 8: 0.00000006 * more: less than 1 in ten million */ 当我们的链表长度达到8时,就会转换为红黑树的结构。源码的注释里也说了,这是根据"泊松分布"概率学得出来的一个结论,计算公式就是 (exp(-0.5) * pow(0.5, k) /* factorial(k)) ,而一个链表深度想要达到8的深度,它的概率只有0.00000006,所以这个红黑树对于整个hashmap数据结构的性能提升没有特别大。很多博客都说加载因子是为了满足做泊松分布,这其实是错误的,它们没有半毛钱的关系。
HashMap线程安全问题
【1.】 put的时候,导致数据不一致问题。 1. 线程1计算好了桶的索引坐标,希望插入一个key-value对到HashMap中,但此时cpu时间片耗尽了,进入阻塞状态。 2. 线程2开始正在执行put操作,假使它的桶索引恰好和线程1是一样的,并数据插入成功。 3. 线程1现在被唤醒了再次运行,他还是持有的之前的链表头,继续往计算好的地方插入数据。 4. 最后就覆盖了线程2插入的记录,导致了线程2插入的记录就凭空消失了。 【2.】 扩容时形成环形链表,导致后续遍历时出现死循环,CPU过高。 比如我现在有一个map,初始长度为2,扩容阈值为0.5。此时散列地址0处有元素A和B,这时候要添加元素C,C的散列值为1,由于超过了临界值就会进行扩容, HashMap<String,String> map = new HashMap<String,String>(2,0.5f); map.put("A","A"); map.put("B","B"); 在多线程条件下,会出现条件竞争,模拟过程如下:
(1) 线程1读取到hashmap情况正准备扩容 (我们for(Entry<K,V> e : table) 实际就是遍历这个链表,e的指针指向A,e.next指向的就是B) 此时线程2介入

(2) 线程2读取hashmap,进行扩容。(同样的线程2的 e指针指向A,e.next指向B。newTable[i]假如i=2,待它循环完之后,AB的元素的位子就反过来了)
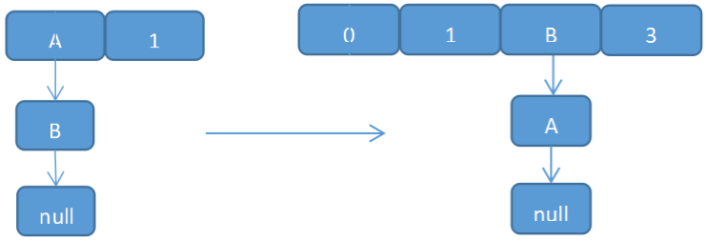
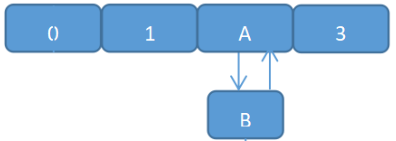
(3) 线程1继续执行(循环完之后A的next是指向B的,而由于另一条线程B的next又是指向A。由此,环形链表出现:B.next=A; A.next=B )
ArrayList与LinkedList
数组数据结构
数组是一种线性表数据结构,开辟了一组连续内存来存储同一类型的数据。每一个节点主要存储数据信息和下标信息。比如现在有一个数组String[] arr = new String[3],里面顺序添加了a、b、c 3个元素;我现在想要在第2个地方添加一个 d 元素,那么就需要重新调整第2个和后面所有元素的角标。但是访问第 2 个元素 直接通过下标就能访问到了。所以说数组的特点是:高效的随机访问,低效的新增和删除。

为什么数组下标要从0开始
这个主要从两个方面说起:
1. C语言的下标是从0开始,所以后面的高级语言都沿用了这一个特性。
2. 根据下标访问元素会更快。
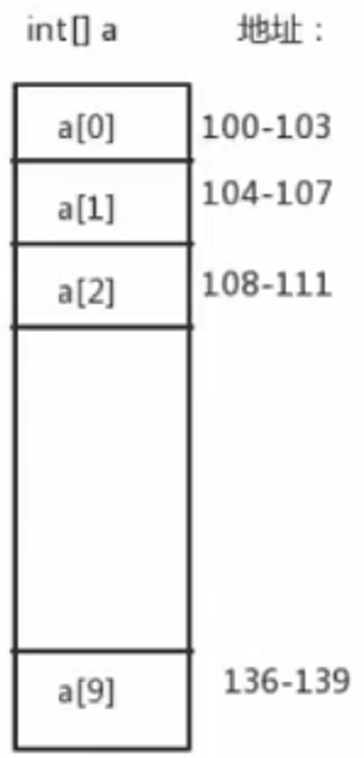
假如我们现在有一个数组 int [] a = new int [10]。
计算机给它分配的连续空间为100~139,内存起始值baseAddress=100;因为存的是int类型,所以dataTypeSize=4
那么我们访问一个元素的寻址公式就是:a[i] = baseAddress + i * dataTypeSize
而如果下标从1开始的话,寻址公式就为 a[i] = baseAddress + (i-1)*dataTypeSize
对比可以发现:下标从1开始,那么寻址时需要多计算一下,性能会下降一点。
链表数据结构
链表是一个零散的内存结构。每一个节点除了存储数据本身信息,还会记录其他数据内存地址的指针域。如果计算机还剩100mb的内存,我们可以用它来创建一个100mb的链表、却无法创建100mb的数组。我们新增节点只需要其中一个节点指向新节点就好、不用做大规模的调整;而我们访问一个节点时,由于内存地址时无序的,只能通过遍历每个节点,来找到指定元素。所以说数组的特点是:低效的随机访问,高效的新增和删除。
常见的几种链表类型
单链表:单链表就是通过指针域把零散内存串起来。每一个节点都指向下一个节点的地址。只有头节点和尾节点不一样。头节点还记录了链表的基地址,而尾节点最后指向的null。
循环链表:循环链表和单链表一样,只有一个方向。但是尾节点的指针域时指向头节点的。

双向列表:相比于单链表,更加的占用内存,但是支持双向遍历,更具备灵活性。

双向循环列表:同样的尾节点指向头节点。

ArrayList与LinkedList比较
1. ArrayList基于数组实现,LinkedList基于双向链表实现。所以前者查询快、后者编辑快。
2. LinkedList比ArrayList占内存,前者要存两个引用地址,后者只需要存下标。
如何保证线程安全
1. 直接 synchronized 锁住变量,在jvm层面获取到锁标识才能操作对象。
2. 使用 Collections 的线程安全api,所有的操作都是被 synchronized 加持的。
List<Object> list = Collections.synchronizedList(new ArrayList<>());

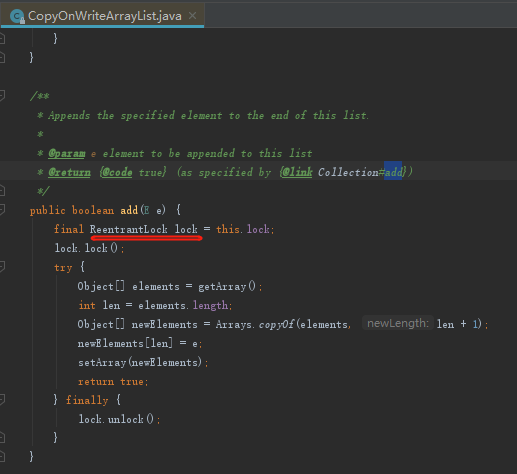
3. CopyOnWriteArrayList创建对象,它是用 ReentrantLock 来保证线程安全的
CopyOnWriteArrayList<Object> objects = new CopyOnWriteArrayList<>();