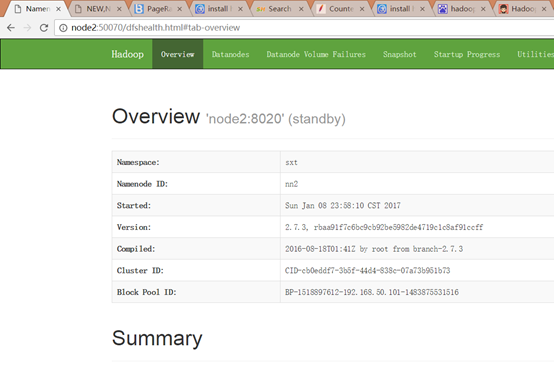
注:来自尚学堂小陈老师上课笔记
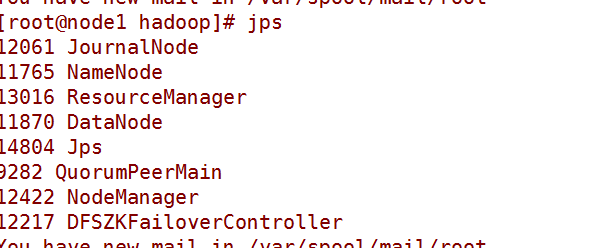
1.安装启动zookeeper
a)上传解压zookeeper包
b)cp zoo_sample.cfg zoo.cfg修改zoo.cfg文件
c)dataDir=/opt/data/zookeeper
server.1=node1:2888:3888
server.2=node2:2888:3888
server.3=node3:2888:3888
这里的node1是自己主机名,可以写ip
d)分别在node1 node2 node3 的数据目录/opt/data/zookeeper下面创建myid文件,里面写对应server.后面的数字
e)配置环境变量并source生效
export ZK_HOME=/opt/soft/zookeeper-3.4.6
export PATH=$JAVA_HOME/bin:$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$ZK_HOME/bin
f)启动 zkServer.sh start启动,隔一分钟,通过zkServer.sh status查看状态
2.配置hadoop配置文件
配置hdfs-site.xml
<property>
<name>dfs.nameservices</name>
<value>sxt</value>
</property>
<property>
<name>dfs.ha.namenodes.sxt</name>
<value>nn1,nn2</value>
</property>
<property>
<name>dfs.namenode.rpc-address.sxt.nn1</name>
<value>node1:8020</value>
</property>
<property>
<name>dfs.namenode.rpc-address.sxt.nn2</name>
<value>node2:8020</value>
</property>
<property>
<name>dfs.namenode.http-address.sxt.nn1</name>
<value>node1:50070</value>
</property>
<property>
<name>dfs.namenode.http-address.sxt.nn2</name>
<value>node2:50070</value>
</property>
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://node1:8485;node2:8485;node3:8485/sxt</value>
</property>
<property>
<name>dfs.client.failover.proxy.provider.sxt</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_rsa</value>
</property>
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
配置core-site.xml
<property>
<name>fs.defaultFS</name>
<value>hdfs://sxt</value>
</property>
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/opt/data/journal</value>
</property>
<property>
<name>ha.zookeeper.quorum</name>
<value>node1:2181,node2:2181,node3:2181</value>
</property>
3.启动所有journalnode
hadoop-daemon.sh start journalnode
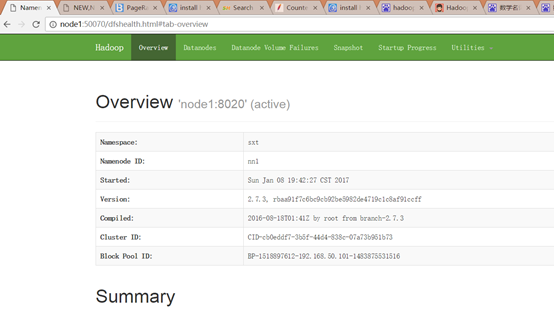
4.其中一个namenode节点执行格式化
hdfs namenode -format
5.另外一个namenode节点格式化拷贝
首先要将刚才格式化之后的namenode启动起来
hadoop-daemon.sh start namenode
hdfs namenode -bootstrapStandby
6.上传配置到zookeeper集群
hdfs zkfc -formatZK
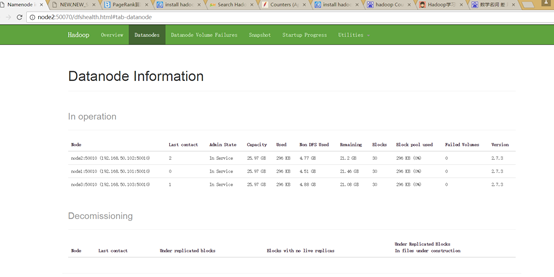
7.启动
先stop-dfs.sh
然后start-dfs.sh
hadoop-daemon.sh start namenode