本节主要内容:
一、DStream与RDD关系的彻底的研究
二、StreamingRDD的生成彻底研究
Spark Streaming RDD思考三个关键的问题:
RDD本身是基本对象,根据一定时间定时产生RDD的对象,随着时间的积累,不对其管理的话会导致内存会溢出,所以在BatchDuration时间内执行完RDD操作后,需对RDD进行管理。
1、DStream生成RDD的过程,DStream到底是怎么生成RDD的?
2、DStream和RDD到底什么关系?
3、运行之后怎么对RDD处理?
所以研究Spark Streaming的RDD,RDD产生的全生命周期,产生、运行、运行后的管理尤其重要。
源码解读:

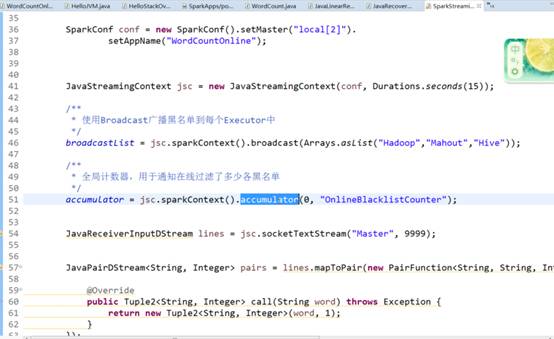
温馨提示:广播和计数器并不像看上去简单,在实际的最佳实践中,通过广播和计数器可以实现非常复杂的算法。
看代码逻辑,逻辑是一种想法,上述代码的socketTextStream,就可以想象数据的输入?,数据处理?数据怎么来?
在获得数据后进行一系列的transformations、最后进行foreachRDD的操作。
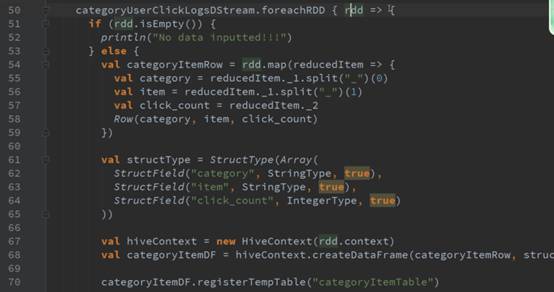
1、直接用foreachRDD 在这里面直接定义了对action操作,可以直接写对RDD处理的操作函数,如图:
2、从RDD的角度讲,操作DStream 的print函数,其实是转过来操作foreachRDD的print:

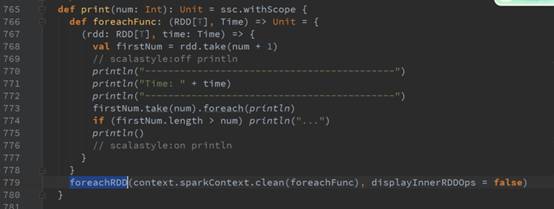
在RDD中操作action不会产生新的RDD,DStream和它完全对应,在DStream中操作action不会产生新的DStream。
foreachDStream是transformation操作,在整个Spark Streaming的操作中,foreachDStream不一定会触发job的执行
,但会触发Job的产生。
Job产生由timer产生,根据业务逻辑代码产生,和foreachDStream没什么关系。
1、foreachDStream和Job的执行没有关系,不会触发Job执行。
2、有foreachDStream执行会产生Job是不对的,只根据框架来调度Job的执行。
foreachRDD的代码中对RDD的操作,如果没有action操作则不会执行action的操作。
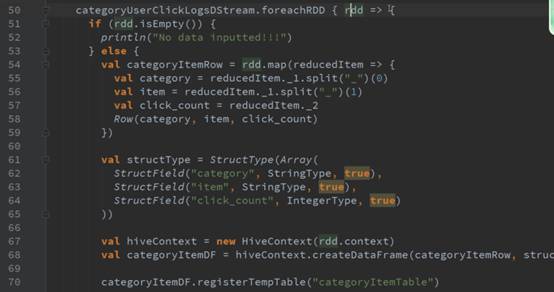

foreachRDD是Spark Streaming的后门,直接对rdd的操作,背后封装成foreachRDD的操作。
总结:
在Spark Streaming的所有逻辑操作都是对DStream的操作,对DStream的操作其实就是对RDD的操作,DStream是RDD的模板。
后面的DStream对前面的DStream有依赖:

对map操作产生map的DStream:
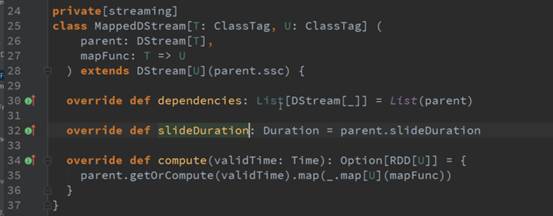
基于DStream怎么产生rdd?通过batchInterval。研究DStream是怎么生成,看DStream的操作触发RDD的生成。

根据时间实例产生RDDs,和batchDuration对齐的,如:timer实例就是1秒,1秒生成一个RDD,
每个RDD对应一个Job,因为RDD就是DStream操作的时间间隔的最后一个RDD,后面的RDD对前面
的RDD有依赖关系,后面对前面有依赖可以推到出整个依赖链条。
看下官方:
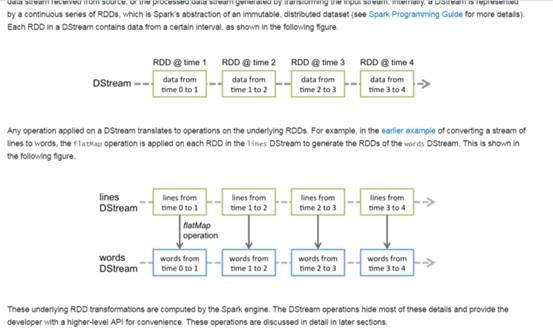
计算从后往前推,计算只需要获取最后一个的RDD的句柄。根据时间从后往前找出
RDD的依赖关系,从而找出对应的空间关系。
看下generateRDD是怎么获取的?
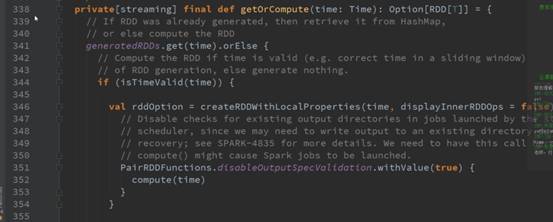
后的rdd和batchDuration对应的rdd,DStream有个getOrComputer方法,根据batchDuration生成rdd的,可以是
缓存或计算级别算出来。
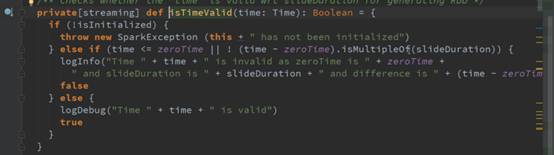
到此处,RDD变量生成了,但是并没有执行,只是在逻辑级别的代码,可以在框架级别进行优化管理。
注意:SparkStreaming实际上在没有输入数据的时候仍然会产生RDD,可以在此处修改源码,提升性能。
新浪微博:http://weibo.com/ilovepains
微信公众号:DT_Spark
博客:http://blog.sina.com.cn/ilovepains
手机:18610086859
QQ:1740415547
邮箱:18610086859@vip.126.com
Spark发行笔记8