本篇文章主要从二个方面展开:
一、Exactly Once
二、输出不重复
事务:
银行转帐为例,A用户转账给B用户,B用户可能收到多笔钱,如何保证事务的一致性,也就是说事务输出,能够输出且只会输出一次,即A只转一次,B只收一次。
从事务视角解密SparkStreaming架构:
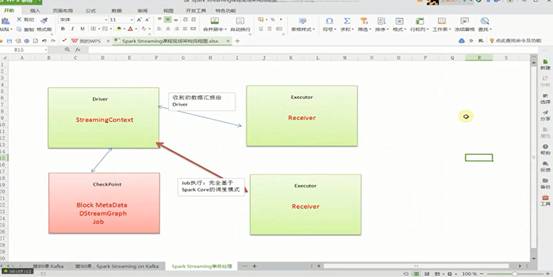
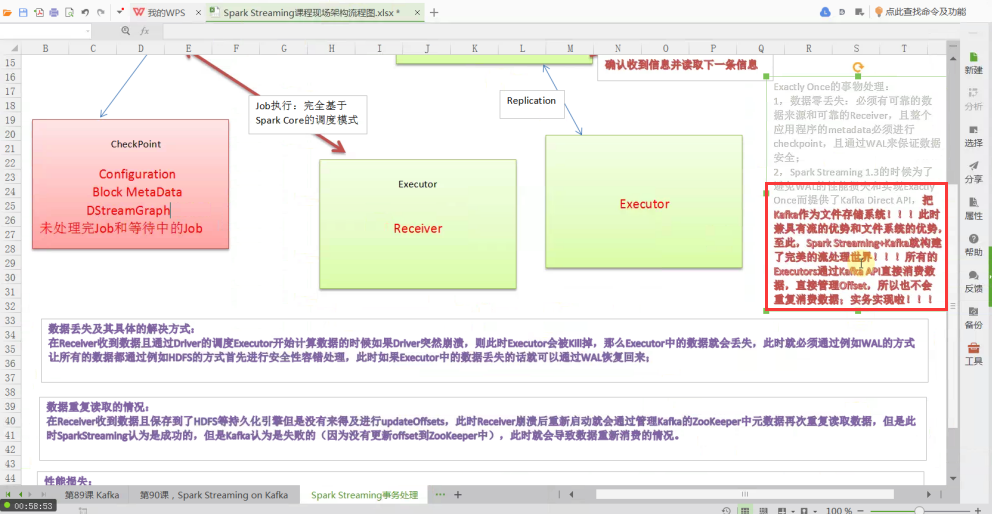
SparkStreaming应用程序启动,会分配资源,除非整个集群硬件资源奔溃,一般情况下都不会有问题。SparkStreaming程序分成而部分,一部分是Driver,另外一部分是Executor。Receiver接收到数据后不断发送元数据给Driver,Driver接收到元数据信息后进行CheckPoint处理。其中CheckPoint包括:Configuration(含有Spark Conf、Spark Streaming等配置信息)、Block MetaData、DStreamGraph、未处理完和等待中的Job。当然Receiver可以在多个Executor节点的上执行Job,Job的执行完全基于SparkCore的调度模式进行的。
Executor只有函数处理逻辑和数据,外部InputStream流入到Receiver中通过BlockManager写入磁盘、内存、WAL进行容错。WAL先写入磁盘然后写入Executor中,失败可能性不大。如果1G数据要处理,Executor一条一条接收,Receiver接收数据是积累到一定记录后才会写入WAL,如果Receiver线程失败时,数据有可能会丢失。
Driver处理元数据前会进行CheckPoint,SparkStreaming获取数据、产生作业,但没有解决执行的问题,执行一定要经过SparkContext。Dirver级别的数据修复从Driver CheckPoint中需要把数据读入,在其内部会重新构建SparkContext、StreamingContext、SparkJob,再提交Spark集群运行。Receiver的重新恢复时会通过磁盘的WAL从磁盘恢复过来。

SparkStreaming和Kafka结合不会出现WAL数据丢失的问题,SparkStreaming必须考虑外部流水线的方式处理。
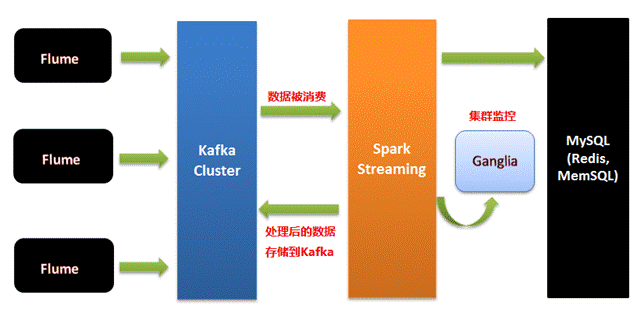
怎么能完成完整的语义、事务的一致性,保证数据的零丢失,Exactly Once的事务处理:
1、怎么保证数据零丢失?
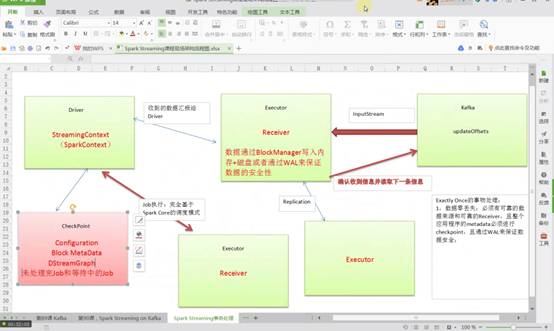
必须要有可靠的数据来源和可靠的Receiver、整个应用程序的MetaData必须进行CheckPoint、通过WAL来保证数据安全(生产环境下Receiver接收Kafka的数据,默认情况下会在Executor中存在二份数据,且默认情况下必须二份数据备份后才进行计算;如果Receiver接收数据时奔溃,没有Copy副本,此时会重新从Kafka中进行Copy,Copy的依据是zookeeper元数据)。
大家可以将Kafka看作是一个简单的文件存储系统,在Executor中Receiver确定受到Kafka的每一条记录后进行Replication到其他Executor成功后会通过ack向Kafka发送确认收到的信息并继续从Kafka中读取下一条信息。
2、Driver容错如下图所示:
再次思考数据在哪些地方可能丢失?
数据丢失的主要场景如下:
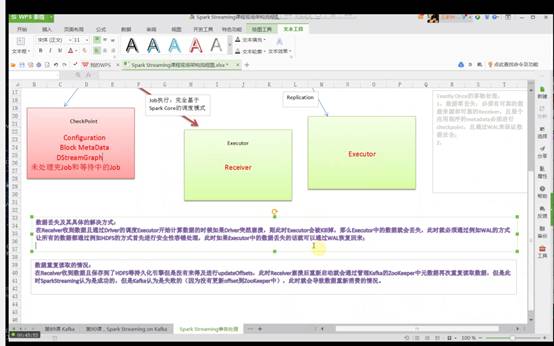
在Receiver收到数据且通过Driver的调度,Executor开始计算数据的时候如果Driver突然奔溃(导致Executor会被Kill掉),此时Executor会被Kill掉,那么Executor中的数据就会丢失,此时就必须通过例如WAL机制让所有的数据通过类似HDFS的方式进行安全性容错处理,从而解决Executor被Kill掉后导致数据丢失可以通过WAL机制恢复回来。
下面需要考虑二个很重要的场景:
数据的处理怎么保证有且仅有被处理一次?
数据零丢失并不能保证Exactly Once,如果Receiver接收且保存起来后没来得及更新updateOffsets时,就会导致数据被重复处理。
更详细的说明数据重复读取的场景:
在Receiver收到数据且保存到了hdfs时Receiver奔溃,此时持久化引擎没有来得及进行updateOffset,Receiver重新启动后就会从管理Kafka的ZooKeeper中再次读取元数据从而导致重复读取元数据;从SparkStreaming来看是成功的,但是Kafka认为是失败的(因为Receiver奔溃时没有及时更新offsets到ZooKeeper中)重新恢复时会重新消费一次,此时会导致数据重新消费的情况。
性能补充:
- 通过WAL方式保证数据不丢失,但弊端是通过WAL方式会极大的损伤SparkStreaming中的Receiver接收数据的性能(现网生产环境通常会Kafka direct api直接处理)。
- 需要注意到是:如果通过Kafka作为数据来源的话,Kafka中有数据,然后Receiver接受数据的时候又会有数据副本,这个时候其实是存储资源的浪费。(重复读取数据解决办法,读取数据时可以将元数据信息放入内存数据库中,再次计算时检查元数据是否被计算过)。
Spark1.3的时候为了避免WAL的性能损失和实现Exactly Once而提供了Kafka direct api,把Kafka作为文件存储系统!!!此时Kafka兼具有流的优势和文件系统的优势,至此,Spark Streaming+Kafka就构建了完美的流处理世界!!!
数据不需要copy副本,不需要WAL性能损耗,不需要Receiver,而直接通过kafka direct api直接消费数据,所有的Executors通过kafka api直接消费数据,直接管理offset,所以也不会重复消费数据;事务实现啦!!!
最后一个问题,关于Spark Streaming数据输出多次重写及解决方案:
为什么会有这个问题,因为SparkStreaming在计算的时候基于SparkCore,SparkCore天生会做以下事情导致SparkStreaming的结果(部分)重复输出:
1.Task重试;
2.慢任务推测;
3.Stage重复;
4.Job重试;
会导致数据的丢失。
对应的解决方案:
1.一个任务失败就是job 失败,设置spark.task.maxFailures次数为1;
2.设置spark.speculation为关闭状态(因为慢任务推测其实非常消耗性能,所以关闭后可以显著的提高Spark Streaming处理性能)
3.Spark streaming on kafka的话,假如job失败后可以设置kafka的auto.offset.reset为largest的方式会自动恢复job的执行。
最后再次强调:
可以通过transform和foreachRDD基于业务逻辑代码进行逻辑控制来实现数据不重复消费和输出不重复!这二个方法类似于spark s的后门,可以做任意想象的控制操作!
姜伟
备注:
Spark发行版笔记4
更多私密内容,请关注微信公众号:DT_Spark