pandas中有两个主要的数据结构:Series和DataFrame。
【Series】
Series是一个一维的类似的数组对象,它包含一个数组数据(任何numpy数据类型)和一个与数组关联的索引。
为了方便理解,可以把Series看着是一个有序字典。其中索引是连续的,从0开始。
from pandas import Series,DataFrame series=Series(["Kangkang","Michale","Jane","Maria"]) print(series)
输出如下,左边表示每个元素对应的索引,右边表示相应元素,索引从0开始。
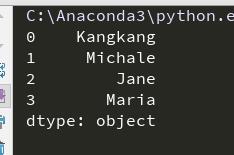
使用 series.values和series.index 来获取元素和相应的索引。
print(series.values) print(series.index)

【DataFrame】
一个DataFrame表示一个表格,它包含一个经过排序的列表集。每一个列表都可以有不同的类型值(数字,字符串,布尔等等)。
Datarame有行和列的索引;它可以被看作是一个Series的字典(每个Series共享一个索引)。
可以通过相等长度列表的字典来构建一个DataFrame。
data={"name":["Kangkang","Michale","Jane","Maria"],"age":["18","19","20","21"]}
dataFrame=DataFrame(data)
print(dataFrame)
输出如下,这时对列名进行了排序:
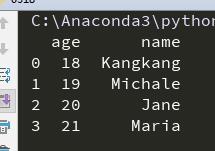
可以通过columns参数来指定列的排序:
data={"name":["Kangkang","Michale","Jane","Maria"],"age":["18","19","20","21"]}
dataFrame=DataFrame(data,columns=["name","age"])
print(dataFrame)
输出如下:
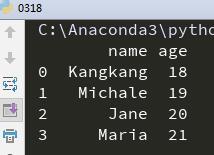
和Series中一样,如果你多传入了一个列,但它不包含在data中,那么在结果中,它会显示为NA值:
data={"name":["Kangkang","Michale","Jane","Maria"],"age":["18","19","20","21"]}
dataFrame=DataFrame(data,columns=["name","age","score"])
print(dataFrame)
输出如下:
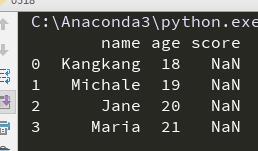
【Reference】