根据线性表的实际存储方式,分为两种实现模型:
- 顺序表 ,将元素顺序地存放在一块连续的存储区里,元素间的顺序关系由它们的存储顺序自然表示。
- 链表 ,将元素存放在通过链接构造起来的一系列存储块中。
一、顺序表
在Java中,顺序表的结构主要有:数组、ArrayList
ArrayList 的 本质是对 数组Object[ ] 的封装,将该数组作为它的一个属性。元素存储在 数组中
CRUD
对 ArrayList 的操作,实际上也是,用数组工具类---Arrays 来封装数组的CRUD以及排序等操作方法
- 查找、修改操作,可快速找到相关节点,时间复杂度上位 O(1)
- 插入、删除操作,需要增加 额外的 相关操作(即,将后续元素的进行前移 or 后移)
排序:
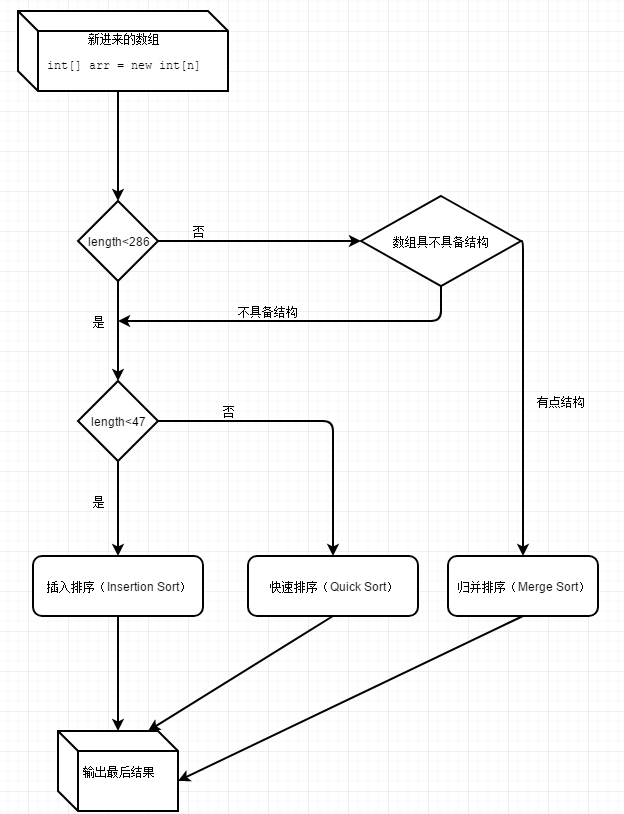
在 JDK 中对数组的操作主要是 Arrays 类。其中 Arrays.sort() 有多种重载方式。在对整型(int) 进行排序时,主要使用到了 插入排序、快速排序、归并排序
参考:https://www.cnblogs.com/baichunyu/p/11935995.html
- 当 数列长度 小于 47 时,使用插入排序
- 当 数列长度 大于等于 47 且 小于286时,使用 快速排序
- 当 数列长度 大于 286 时,
- 数列具备结构 -- 使用 归并排序
- 不具备结构 --- 使用 快速排序
二、链表
链表 中主要由 节点 组成,每个 节点 都存储元素 以及其他节点的地址(如:前后节点的地址)。
CRUD
链表 的 CRUD 操作都要从头遍历到 指定的索引处(因为链表的存储不是连续的,所以时间复杂为 O(n) )。对节点的插入、删除操作,并不需要对后续的元素调整位置,只是修改相关节点指向其他节点的指针。
排序
一般链表的排序思路:(如:LinkedList)
- 建立一个新的数组,将 链表 中的元素 复制到 数组;
- 对 数组 进行排序;
- 将排序后的 数组 再复制回 原来的 链表中。(即,对链表 进行 set 操作)
1、单向链表
在 Java 中,单向链表 的数据结构 主要有:HashMap
HashMap 由 数组 + 单向链表(or 红黑树) 组成,HashMap的 Entry实体类(存储键值对的实体) 组成单向链表
2、双向链表
在 Java 中,双向链表 的数据结构 主要有:LinkedList、LinkedHashMap
LinkedList 用内部类--Node来作为节点。
LinkedList 有 first 和 last 属性,所以在 LinkedList 的头尾操作时,时间复杂度为O(1);
3、单向循环链表
链表的最后一个节点指向链表的 头节点。举例:略!
4、双向循环列表
在 Java 中,单向链表 的数据结构 主要有:LinkedHashMap
LinkedHashMap 中
- 有 数据+单向链表(红黑树) 结构,用于存储 键值对 元素
- 同时也 双向循环链表 结构,用于维护 键值对 的 插入顺序 or 访问顺序 ,达到该 Map 有序效果。
三、栈
栈 -- 先进后出
栈的实现: 栈可以用顺序表实现,也可以用链表实现。
四、队列
单向队列 -- 先进先出。双向队列 -- 可从两端进,两端出
队列的实现(同栈一样): 栈可以用顺序表实现,也可以用链表实现。
五、堆
六、树
Java中的内存划分
1、栈
栈(Stack):存放的都是方法的 局部变量。方法的运行一定要在栈中运行。
- 局部变量:方法的参数,或是方法 大括号{ } 内部的变量
- 作用域:一旦超出 作用域,立刻从 栈内存 当中弹出
2、堆
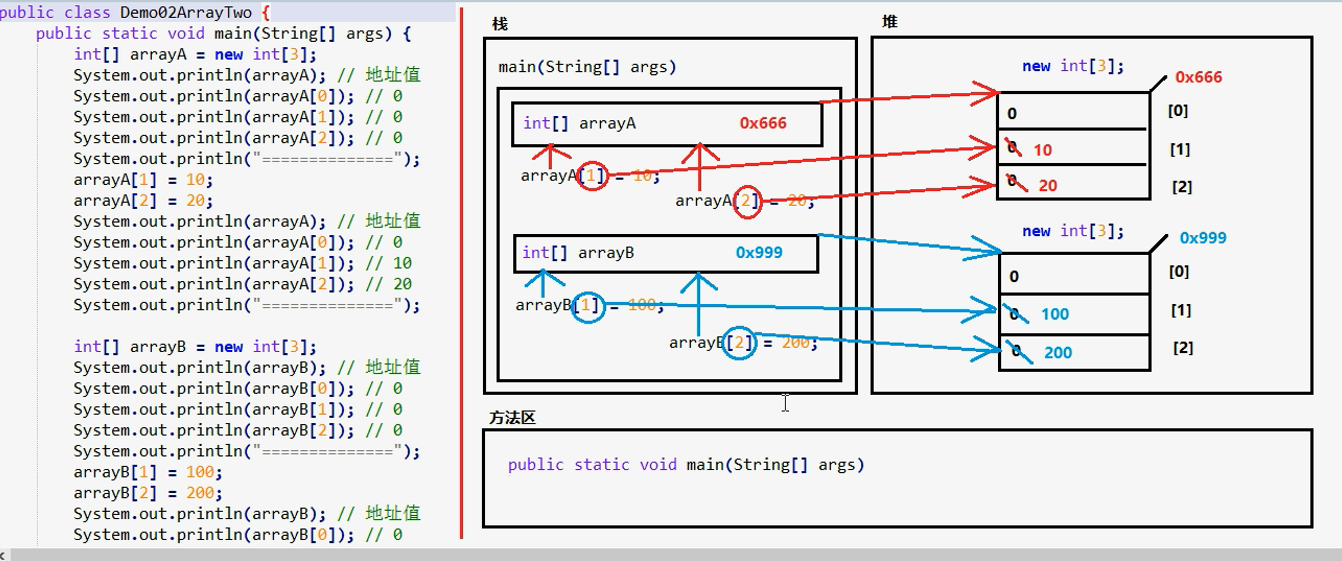
堆(Heap):凡是 new 出来的东西,都在 堆 当中。(如果是在方法内定义的引用类型的局部变量,该引用类型的对象 是在堆中,该对象的变量名 是 在栈中,且变量名存储的是 对象地址 -- 该对象在堆中的地址)
- 堆内存里面的东西都有一个地址值:16进制
- 堆内存里的数据,都有默认值。规则:
- 整数 -- 默认为 0
- 浮点数 -- 默认为 0.0
- 字符 -- 默认为
‘u0000’ - 布尔 -- 默认为 false
- 引用类型 -- 默认为
null
3、方法区
方法区:存储 .class 相关信息,包括方法的信息(即,方法的定义等)
4、本地方法栈
与操作系统相关
5、寄存器
与 CPU 相关