| 故事背景
话说有一回,X市X公司的产品经理Douni兴致冲冲的跑来和Sum(Sum,X市X公司资历8年程序猿,技能:深思、熟虑、心细、深究、技术过敏。口头禅:嗯,容我想想。坚信:只要赚钱的业务,我都可以让一枚程序猿完成,如果不行,那就再加一枚。)说:“最近公司的B2C业务不景气,需要开发代理功能,我们产品部正在开产品研讨会,要不要一起来参加。”,Sum摸了一把下巴,嘴角露出一丝诡异的笑容,目光沿着45度角向产品经理投射过去,说:“容我,想想。”。话音未落,已被Douni抬离卡座,电光火石间仿佛听到Doubi那久久未能散去的余音:“这事没你不行!!!”
| 需求分析
Sum在产品研讨会上讨论(激烈争吵)之后,最终确定了需求。
需求定义是在X公司的一个B2C电商平台增加一个代理功能,让指定的老用户升级为代理,从而推动该电商的流水,代理也可以从中获取到可观的报酬。
这个需求对于资深、心细的Sum来说,并未有挑战。但是Sum虽然自称是猿,但毕竟来说,还是一个小团队的头儿。所以,在经过整理需求之后,发现了一个比较容易犯错,且若交给队员去实现的话,有延期风险的技术难点。所以,Sum决心自己先过一遍核心思路,再把该功能交给队友去做。
| 开干
该功能点对于Sum来说,并不难。主要是在该平台高并发下,代理利润分成的结算。这设计到了数据的一致性和可靠性。在有限的开发条件下,Sum的第一念头是写一个存储过程,在存储过程当中,使用事务对数据进行修改。于是,Sum在分配完其余工作之后,开始着手编写这个存储过程。
Sum打开phpstudy,开启mysql(项目用的是PHP、mysql的环境),然后打开SQLyog,进入本地的环境。
很熟练的,新建了一个数据库demo。
接着建立用户表names,注意,该表的存储引擎是InnoDB(InnoDB具有事务回滚、提交、原子性等功能)
1 CREATE TABLE `names` ( 2 `id` int(11) unsigned NOT NULL AUTO_INCREMENT, 3 `name` varchar(10) DEFAULT NULL, 4 PRIMARY KEY (`id`), 5 UNIQUE KEY `name` (`name`) 6 ) ENGINE=InnoDB AUTO_INCREMENT=3 DEFAULT CHARSET=utf8mb4
再建立一张资金表testa:
1 CREATE TABLE `testa` ( 2 `id` int(11) unsigned NOT NULL AUTO_INCREMENT, 3 `name` varchar(40) DEFAULT NULL, 4 `money` decimal(10,2) DEFAULT NULL, 5 PRIMARY KEY (`id`), 6 UNIQUE KEY `name` (`name`) 7 ) ENGINE=InnoDB AUTO_INCREMENT=3 DEFAULT CHARSET=utf8mb4
万事已具备,只欠编写代码了。Sum坐在电脑前,深思了一会。突然间,双手放在键盘上。。。
经过了大概十几分钟,显示器出现了一连串代码:
1 DELIMITER $$ 2 3 USE `demo`$$ 4 5 DROP PROCEDURE IF EXISTS `test`$$ 6 7 CREATE DEFINER=`root`@`localhost` PROCEDURE `test`(IN id INT(11) UNSIGNED, IN m DECIMAL(10,2) UNSIGNED) 8 test:BEGIN 9 DECLARE t_error INT DEFAULT 0; 10 DECLARE CONTINUE HANDLER FOR SQLEXCEPTION SET t_error = 1; 11 12 SELECT `name` INTO @t_name FROM `names` WHERE `id`= id;-- 查出用户的信息 13 SET AUTOCOMMIT = 0;-- 关闭自动提交SQL语句 14 START TRANSACTION;-- 开启事务,当然开启事务还有BEGIN 15 SELECT `money` INTO @money FROM `testa` WHERE `name`=@t_name FOR UPDATE;-- 查询当前余额,这一步为什么查询出来而不是直接锁?大家思考下。 16 UPDATE `testa` SET `money`=@money+m WHERE `name`=@t_name;-- 更新资金库 17 18 IF t_error = 1 THEN-- 失败则回滚 19 ROLLBACK; 20 ELSE 21 COMMIT;-- 成功则提交 22 END IF; 23 24 SELECT t_error;-- 返回该事务的处理代码0|1 25 END$$ 26 27 DELIMITER ;
Sum摸了一把下巴,满意的喝了一口咖啡,Ctrl+F9,这个存储过程就创建好了。
接下来就是调试阶段,任何程序猿对外都会说,我的代码是没有BUG的,即使心中对自己有一万个为什么。对于自认为骨子里有架构师天分的Sum来说,在未对外吹牛逼的时候,自测是非常重要的环节。于是他兴奋的打开了一个查询窗口,潇潇洒洒的写上了一句:
call ·test·(1,33.00);
这段代码他心中已经运行了好几遍,也检查了好几遍,自认为并未有传说中程序杀手--BUG--的存在,充满自信的按下了Ctrl+F9。
万万没想到,运行结果竟然是!!!!!
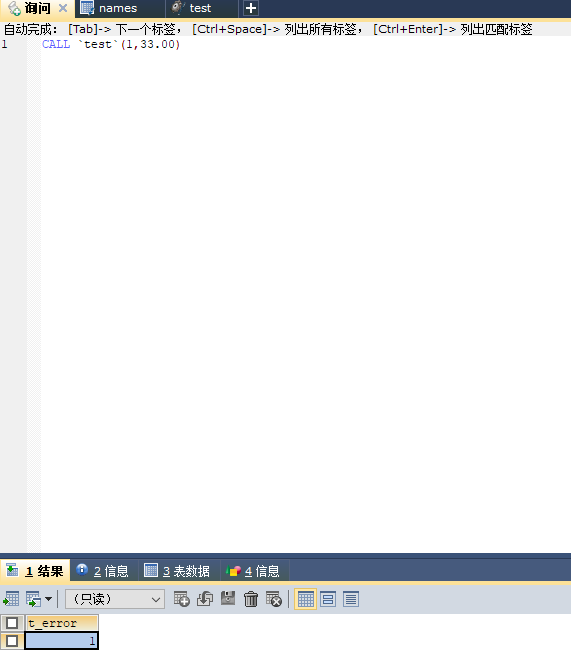
非常刺激!!!Sum手一抖,咖啡差些洒在办公桌上!!昂无里窝波儿!!简直不敢相信!!Sum把咖啡往桌上一放,目光立即盯着该段存储过程的代码,一行行往下扫去!!!
“没问题啊没问题啊,问题出在哪里啊!!!”脑中蹦出无数个没问题,Sum此时都快疯了。心想,“幸好,不把这个工作丢给队员,这操作简直太正确了!!!”
在思考无果后,Sum各种百度谷歌。。。。。(省去一小时寂静无语的时光)
终于在网上找到了一个解决方案
-- 如果出现执行异常则结束后继的执行,并执行begin-end中的处理 DECLARE EXIT HANDLER FOR SQLEXCEPTION BEGIN -- 回滚事务 ROLLBACK; -- 获取错误信息 GET DIAGNOSTICS CONDITION 1 @p1=RETURNED_SQLSTATE,@p2= MESSAGE_TEXT; -- 借“模拟”抛出异常 RESIGNAL SET schema_name = 'mtt_dev', table_name = 'tb_test', message_text = @p2, mysql_errno = @p1; END;
当Sum把代码小心翼翼的合并到存储过程中后,按下Ctrl+F9,竟然报错了
错误代码: 1064
You have an error in your SQL syntax; check the manual that corresponds to your MySQL server version for the right syntax to use near 'DIAGNOSTICS CONDITION 1 @p1=RETURNED_SQLSTATE,@p2= MESSAGE_TEXT;
-- 借“' at line 10
原来,这个解决方案是在mysql5.6版本或以上版本才能使用,而Sum本地的环境是5.1版本的mysql,所以提示了报错。MySQL 5.6 提供了 get diagnostic 语句来获取错误缓冲区的内容
这一方案在电光火石间就被抛弃了。Sum又陷入了新一轮的惆怅当中,可是有着架构师天赋的Sum岂是说放弃就放弃的?于是,他开始了新一轮的调试。
Sum每一行每一行的进行调试,也不忘在X技术群里问老前辈们。
终于有发现!!!(已经过了3个小时)
Sum发现,在第一句“SELECT `name` INTO @t_name FROM `names` WHERE `id`= id LIMIT 1”加上LIMIT 1,竟然就过了!!!
如法炮制,Sum把剩余的有关查询和更新的语句都加上LIMIT 1,然后按下Ctrl+F9,再次拿起咖啡,点击运行call ·test·(1,33.00);

完美运行!!!
Sum这可高兴坏了,一看时间,已经是17:00了,于是放下咖啡,快速的编写技术方案,做好demo,交付给队员!
| 最终代码
1 DELIMITER $$ 2 3 USE `demo`$$ 4 5 DROP PROCEDURE IF EXISTS `test`$$ 6 7 CREATE DEFINER=`root`@`localhost` PROCEDURE `test`(IN id INT(11) UNSIGNED, IN m DECIMAL(10,2) UNSIGNED) 8 test:BEGIN 9 DECLARE t_error INT DEFAULT 0; 10 DECLARE CONTINUE HANDLER FOR SQLEXCEPTION SET t_error = 1; 11 12 SELECT `name` INTO @t_name FROM `names` WHERE `id`= id LIMIT 1;-- 查出用户的信息 13 SET AUTOCOMMIT = 0;-- 关闭自动提交SQL语句 14 START TRANSACTION;-- 开启事务,当然开启事务还有BEGIN 15 SELECT `money` INTO @money FROM `testa` WHERE `name`=@t_name LIMIT 1 FOR UPDATE;-- 查询当前余额,这一步为什么查询出来而不是直接锁?大家思考下。 16 UPDATE `testa` SET `money`=@money+m WHERE `name`=@t_name LIMIT 1;-- 更新资金库 17 18 IF t_error = 1 THEN-- 失败则回滚 19 ROLLBACK; 20 ELSE 21 COMMIT;-- 成功则提交 22 END IF; 23 24 SELECT t_error,@t_name;-- 返回该事务的处理代码0|1 25 END$$ 26 27 DELIMITER ;
| 总结
1.当在事务中select 【字段】 into @用户变量 的时候,请确保结果集是一条,如果是多条,请使用游标!
2.使用for update的时候,一定要命中索引字段,不然会锁表,违背了高并发时候,处理事务的初衷
3.小的表,没有索引,尽量的就不用for update,因为mysql的执行计划
4.for update 叫做悲观锁,命中索引的时候,叫做行锁,不命中的时候,叫做表锁,如果结果集为空,则无锁!