0.课程地址与说明
2.课程全名:Using Python to Access Web Data
3.建议使用Python2进行学习
4.仅第一周有中文字幕,其它的只有英文字幕,只要英语有四级基本没有太大问题
5.本人使用的工具是蓝灯,做作业时可以用Google翻译插件帮帮忙
注:第一周讲课程说明和安装Python,无笔记
1.Regular Expressions - Part 1
1.Regular Expression Quick Guide

()用于截取匹配的字符串,举列
1 <p>Please click <a href="http://www.dr-chuck.com">here</a></p> 2 href="(.+)"匹配 http://www.dr-chuck.com 3 href=".+"匹配 href="http://www.dr-chuck.com/page2.htm"
2.翻译
dot . asterisk *
3.举列

^X.*:
以X开始,后面接任意数量的字母("."表示字母,"*"表示任意数量)且以":"结尾
^X-S+:
以X-开始,接着是一个字符数大于0且没有空格的字符串,字符串的最后以":"结尾
4.re.findall() 返回所有匹配项

[0-9]+
任意0-9之间的数字,可以是多个数字。因为时findall()所以会返回所有的数字
5.Greedy Matching 贪心匹配

*和+都是向外搜索去匹配最大的可匹配项,当然也可以使用 *?、+?来实现非贪心匹配
2.Regular Expressions - Part 2
1.通过括号来微调匹配结果

普通的email提取
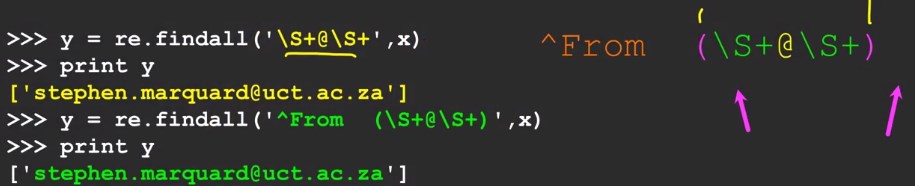
以"From "开头的Email提取
2.[^ ]用于排除字符
1 address=re.findall('@([^ ]*)',data) 2 print(address)
可以实现从@开始找,直到找到一个空格就停
3.[]内的"."
![]()
方括号内的"."并不代表任意字符,而仅仅代表"."
4.Escape Character, 字符前加""保留原意

附件列表
http://yunpan.cn/cubw8yLXSVudF 访问密码 f7bf