一、Hbase架构
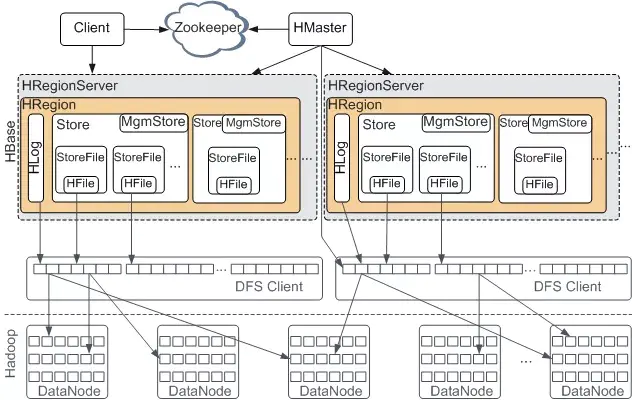
强制写一致(不是最终一致),写比读块,自动分片/合片。
一个RegionServer机器上有多个Region但只有一个HLog,所有Region都往这个HLog中写入数据操作,一个表对应一个或者多个Region(表按行切分为不同Region),每个Region根据列族划分为不同的Store文件。
表是稀疏矩阵,很好的存储特征向量hbase vs cassandrahbase是主从结构,cassandra对等节点rowKey:columnFamily:columnQualifier:timeStamp:value行键:列族:列名:时间戳:值
1.Master作用
Table:create,delete,alter,list
RegionServer:分配regions到每个RegionServer,监控每个RegionServer状态
2.RegionServer作用
Data:get,put,delete
Region:splitRegion,compactRegion
3.HLog作用
预写入日志(WAL),每次操作执行之前都写入此文件
4.Region
表按行切分为不同的Region,一张表对应一个或者多个Region
5.Store
列族存储为文件夹,里面包含每次flush生成的列族文件
6.StoreFile
每次flush生成的列族文件
7.MemStore
内存中的列族文件
8.Zookeeper
处理客户端DML操作,存放meta表所在RegionServer地址(meta不走切分逻辑)
二、Hbse写数据流程
client->查询zookeeper寻找meta表所在RegionServer->访问meta表找到要写入数据的表所在RegionServer->访问数据表所在RegionServer->写入HLog和MemStore
三、Hbase读数据流程
client->查询zookeeper寻找meta表所在RegionServer->访问meta表找到要写入数据的表所在RegionServer->访问数据表所在RegionServer->从磁盘读取数据到块缓存->快缓存数据和MemStore进行Merge->返回指定时间戳数据
无论如何Hbase都会读取Region上的Hstore上的文件
四、flush流程
1.MemStore默认达到堆内存40%*0.95时候开始flush(非阻塞),当达到堆内存的40%会阻塞客户端进行flush操作
<!--一个regionServer的flush-->
<property>
<!--阻塞flush-->
<name>hbase.regionserver.global.memstore.size</name>
<value>0.4</value>
</property>
<property>
<!--非阻塞flush-->
<name>hbase.regionserver.global.memstore.size.lower.limit</name>
<value>0.95</value>
</property>
<property>
<!--region到达128M,单个regionflush-->
<name>hbase.regionserver.memstore.flush.size</name>
<value>134217728</value>
</property>
2.默认最后一次编辑后1小时会进行flush
<property>
<name>hbase.regionserver.optionalcacheflushinterval</name>
<value>3600000</value>
</property>官方建议只使用一个列族,因为全局flush会将表所有region所有内存中的列族刷入磁盘,可能会生成大量小文件触发
五、compact流程
Compact分为 Minor Compact (局部合并)和 Major Compact (全局合并);Minor不会清理过期数据和删除数据而Major会。
<property>
<!--生产环境设置为0关闭,通关手动进行Major-->
<name>hbase.hregion.majorcompaction</name>
<value>604800000</value>
</property>
<property>
<!--每个region的每个列族对应的memstoreflush为hfile时候默认超过3个文件就会进行compact-->
<name>hbase.hstore.compactionThreshold</name>
<value>3</value>
</property>
Minor Compact 超过指定HFile数后不会立刻compact,过一段时间后再进行。Minor Compact 过程先创建合并后的大文件再将各个文件写入,全部完成后再删除其余的三个文件。
Major Compact 会清理过期数据和删除数据。flush 只会删除在内存的数据,但是删除标记不会删除,等到 Major Compact 时会删除标记,因为内存中删除标记有可能针对Hfile中数据删除。
六、split过程
当某个HFile文件大小超过Min(RegionNum^2*"hbase.regionserver.memstore.flush.size","hbase.hregion.max.filesize")时split
split过程会产生数据倾斜
<property>
<!--HFile最大大小-->
<name>hbase.hregion.max.filesize</name>
<value>10737418240</value>
</property>
七、操作
7.1 DDL
# 显示所有表
hbase> list
# 创建命名空间
hbase> create_namespace
# 建表,命名空间可以省略
hbase> create '[命名空间:]表名','列族'....
# 查看表信息
hbase> describe '表名'
# 修改表保存版本数量(版本是相同数据不同的时间戳)
hbase> alter '表名',{NAME=>'列族名',VERSIONS=>保存版本数量}
# 删除表(先停用再删除)
hbase> disble '表名'
hbase> drop '表名'
# 删除命名空间(先要将命名空间下的所有表删除)
hbase> drop_namespace '命名空间'
7.2 DML
# 添加数据
hbase> put '[namespace:]table','rowKey','columnFamily:columnName','value'
# 全表范围扫描查询数据(rowKey相同就是同一条数据)
hbase> scan
# 全表扫描所有版本数据
hbase> scan '表名',{RAW=>true,VERSION=显示的最多版本数}
# 限定条件查询数据
hbase> get '[namespace:]table','rowKey'[,'columnFamily:columnName']
# 删除数据值(在这之前的所有版本全部删除,并不会真实删除而是put一个DeleteColumn数据)
hbase> delete '[namespace:]table','rowKey','columnFamily:columnName'
# 删除整条数据
hbase> deleteall '[namespace:]table','rowKey'
hbase数据文件结构:表名为一个文件夹,下面存储一个Region文件夹,里面存放所有的列族文件夹,里面存储数据文件
删除操作是是Put一个DeleterColumn标记,将删除数据的时间戳之前的数据全部隐藏,当进行全局compact时候才会进行物理删除