Event Time
本文翻译自DataStream API Docs v1.2的Event Time
-------------------------------------------------------
一、事件时间 / 处理时间 / 提取时间
Flink支持流程序不同的time概念。
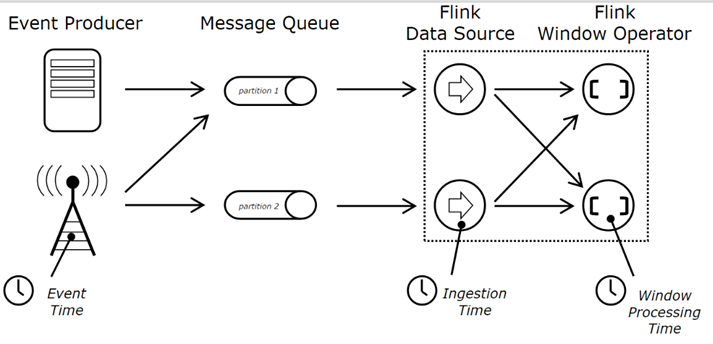
· Processing time:处理时间指执行对应Operation的设备的系统时间。
当一个流程序以处理时间运行,所有基于时间的operation(如time窗口)将使用运行对应Operation的设备的系统时钟。例如,一个每小时触发的时间窗口将包含在系统时钟走过一小时的事件内到达特定operator的所有数据。
处理时间是时间的最简单概念,并且不需要stream和设备之间的协调。它提供了最佳的性能和最低的执行时间。但是,在分布式异步环境中,由于数据到达系统的速度(如从信息队列中到达的数据)以及在系统内部Operator之间流动速度都十分容易受到影响,故处理时间无法提供确定性(determinism)。
· Event time:事件时间是每个单独事件在它的生产设备上发生的时间。该时间通常在数据进入Flink之前就会被集成进数据,且event timestamp是可以从数据中抽取出来的。一个每小时事件的时间窗口将包含所有带有一个小时内的时间戳的数据,而不管这些数据是什么时候到达,也不管它们是以什么顺序到达的。
即使在乱序事件、迟到事件以及备份或持久日志的数据重放等多种的情形下,事件时间也可以给我们提供正确的结果。在事件时间中,时间的增长依靠数据,而不依赖于任何wall clock。事件时间程序必须定义如何生成Event Time Watermarks,这是在事件时间中标识时间增长的机制,有关该机制将在下面描述。
在事件时间处理中,由于它本质上会等待迟到事件和乱序事件,总会导致一些延迟,因此,事件时间程序通常会与processing time operation结合
· Ingestion Time:提取时间是事件进入Flink的时间,在Source Operator中,每个数据以source的当前时间作为时间戳,且基于时间的operator(如时间窗口)便使用该时间戳。
提取时间概念上处于Event Time和Processing Time之间。
a. 与处理时间相比,提取时间的开销稍微昂贵一些,但会给出更多可预见的结果:因为提取时间使用稳定的时间戳(在source上仅仅赋值一次),数据流过的不同的窗口Operator使用同一个时间戳。而在处理时间下,每个window operator可能将数据赋值给不同的窗口(根据本地系统时钟和任何传输延迟)。
b. 与事件时间相比,提取时间不能处理任何乱序事件或迟到数据,但是程序不需要定义如何生成Watermarks。在Flink内部,对待提取时间与事件时间相似,都有自动时间戳赋值以及自动水印生成功能。
1.1 设置时间特征
Flink DataStream程序的第一个部分通常是设置基础时间特征,它定义了数据流源是如何运行的(例如是否使用时间戳),以及诸如KeyedStream.timeWindow(Time.seconds(30))的窗口Operation使用的是哪种概念的时间。
接下来的例子是一个在每小时的窗口中聚合事件的Flink程序,窗口的运行方式与不同时间特征相匹配。
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setStreamTimeCharacteristic(TimeCharacteristic.ProcessingTime);
// alternatively:
//
env.setStreamTimeCharacteristic(TimeCharacteristic.IngestionTime);
//
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);
DataStream<MyEvent> stream = env.addSource(new FlinkKafkaConsumer09<MyEvent>(topic, schema, props));
stream.keyBy(
(event) -> event.getUser()
)
.timeWindow(Time.hours(1))
.reduce(
(a, b) -> a.add(b)
)
.addSink(...);
注意:若要以Event Time运行示例,程序需要使用一个Event time source,或者注入一个Timestamp Assigner & Watermark Generator。这些方法描述了如何访问事件时间戳,以及该事件流会展示出怎样的时间上的乱序性。
下面的部分描述了Timestamps和Watermarks里的普遍机制。有关如何在Flink的DataStream API中使用Timestamp assignment和watermark generation,请查看Generating Timestamps / Watermarks。
二、事件时间(Event Time)和Watermarks
注意:Flink从Dataflow模型中实现了技术,为了更好介绍Event Time,请查看以下文章
· Tyler Akidau的Streaming 101
· Dataflow Model论文
一个支持事件时间的流处理器需要衡量事件时间增长的方式。例如,一个构建了每小时窗口的窗口Operator需要在其事件时间到达下一个小时的时刻接到通知,从而使其可以关闭下一个窗口。
事件时间可以独立于处理时间(Processing Time)(由wall clock衡量)增长。例如,在一个程序中,一个Operator的当前事件时间可以稍稍慢于处理时间(这是由接收最新element的延迟引起的)并且以相同速度增长。在另一个流程序中,由于通过使用在Kafka topic(或另一个消息队列)中已经缓存的数据而实现的快进式读取,从而使得事件时间可以在几秒内增长几周。
Flink中衡量事件时间的机制是Watermarks。Watermark带有一个时间戳t,并作为流的一部分共同流动。一个Watermark(t)声明了事件时间已经走到了该流中的时间t,意味着所有时间戳t`<t的事件已经发生了。
下图是一个带有(逻辑)时间戳的事件流,在事件流中还有Watermark在其中流动。在该事件流中,事件按照其时间戳有序排列,这意味着watermark仅仅是数据流中简单的带有有序时间戳的周期性标记。
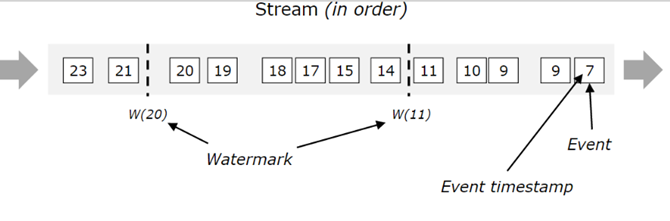
Watermark对于乱序流来说极其重要,正如下图所示的就是一个乱序流,其中的时间不以它们的时间戳顺序发生。Watermark在流中建立了一个点,该点表明时间戳早于该Watermark的时间戳的所有事件都已经发送了。一旦一个Operator接收到一个Watermark,该Operator便可以将其内部事件时钟(event time clock)的值推进到Watermark的值处。

2.1 并行流中的Watermark
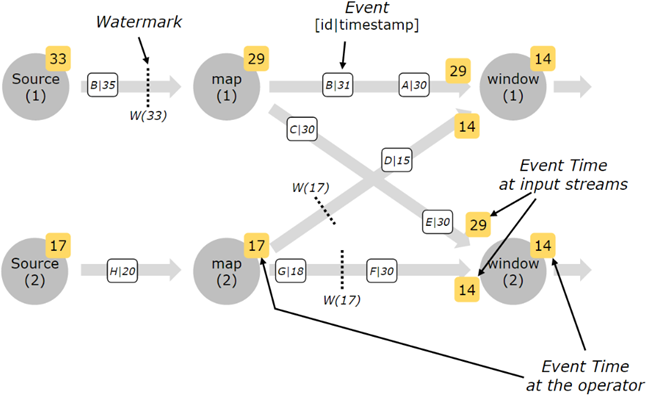
Watermark是在source方法处生成的,也可以直接在source方法之后生成。每个source方法的并行子任务通常独立生成watermark。这些watermark定义了在某个特定的并行source中的事件时间。
随着Watermark在流程序中的流动,它们在到达Operator时推动了Operator中的事件时间前进。一个Operator一旦推进了它的事件时间,它就会在下游为它后继的Operator生成一个新的Watermark。
那些接收多个输入流的Operator(如keyBy(…)之后,或partition(…)方法后,或一个union方法)会在它的每个输入流上分别跟踪其各自事件时间,Operator当前的事件时间是它的所有输入的事件时间之间的最小值。随着输入流更新它们的事件时间,Operator的事件时间也随之更新。
下图是一个事件和Watermark流过并行系统、且Operator跟踪其事件时间的例子。
2.1迟到Element
某些element违反Watermark条件的情况是有可能出现的,这意味着即使在Watermark(t)发生后,还有带有时间戳t`<t的事件发生。事实上,在许多实际部署中,某些element可能会随机性地发生延迟,使我们不可能定义一个“某时间戳的所有事件都已发生”的时间点。此外,即便该延迟是有界的,由于延迟太多的watermark会对事件时间窗口造成太多延迟,这种情况通常也是不理想的。
由于上述几点,一些流程序会显式等待某数量的迟到element。而迟到element就是那些在已经过了迟到element的时间戳的系统事件时间时钟(该时钟以Watermark为信号)之后才到达的element