4个你未必知道的内存小知识
http://www.sohu.com/a/159561375_723543
1 复杂的CPU与单纯的内存
首先,我们澄清几个容易让人混淆的CPU术语。
-
Socket或者Processor:指一个物理CPU芯片,盒装的或者散装的,上面有很多针脚,直接安装在主板上。
-
Core:指Socket里封装的一个CPU核心,每个Core都是完全独立的计算单元,我们平时说的4核心CPU,就是指一个Socket(Processor)里封装了4个Core。
-
HT超线程:目前Intel与AMD的Processor大多支持在一个Core里并行执行两个线程,此时在操作系统看来就相当于两个逻辑CPU(Logical
Processor),在大多数情况下,我们在程序里提到CPU这个概念时,就是指一个Logical Processor。
然后,我们先从第1个非常简单的问题开始:CPU可以直接操作内存吗?可能99%的程序员会不假思索地回答:“肯定的,不然程序怎么跑。”如果理性地分析一下,你会发现这个回答有问题:CPU与内存条是独立的两个硬件,而且CPU上也没有插槽和连线可以让内存条挂上去,也就是说,CPU并不能直接访问内存条,而是要通过主板上的其他硬件(接口)来间接访问内存条。
第2个问题:CPU的运算速度与内存条的访问速度之间的差距究竟有多大?这个差距跟王健林“先挣它个一个亿的”小目标和“普通人有车有房”的宏大目标之间的差距相比,是更大还是更小呢?答案是“差不多”。通常来说,CPU的运算速度与内存访问速度之间的差距不过是100倍,假如有100万元人民币就可以有房(贷)有车(贷)了,那么其100倍刚好是一亿元人民币。
既然CPU的速度与内存的速度还是存在高达两个数量级的巨大鸿沟,所以它们注定不能“幸福地在一起”,于是CPU的亲密伴侣Cache闪亮登场。与来自DRAM家族的内存(Memory)出身不同,Cache来自SRAM家族。DRAM与SRAM最简单的区别是后者特别快,容量特别小,电路结构非常复杂,造价特别高。
造成Cache与内存之间巨大性能差距的主要原因是工作原理和结构不同,如下所述。
-
DRAM存储一位数据只需要一个电容加一个晶体管,SRAM则需要6个晶体管。由于DRAM的数据其实是保存在电容里的,所以每次读写过程中的充放电环节也导致了DRAM读写数据有一个延迟的问题,这个延迟通常为十几到几十ns。
-
内存可以看作一个二维数组,每个存储单元都有其行地址和列地址。由于SRAM的容量很小,所以存储单元的地址(行与列)比较短,可以一次性传输到SRAM中;而DRAM则需要分别传送行与列的地址。
-
SRAM的频率基本与CPU的频率保持一致;而DRAM的频率直到DDR4以后才开始接近CPU的频率。
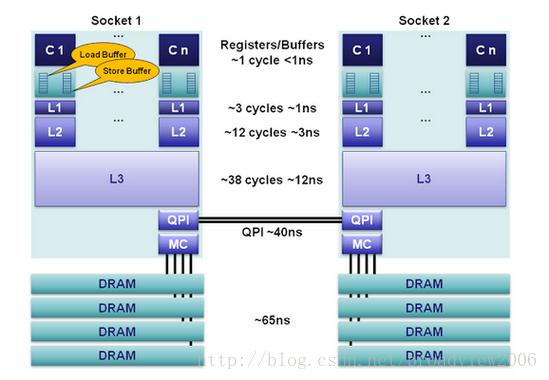
Cache是被集成到CPU内部的一个存储单元,一级Cache(L1 Cache)通常只有32~64KB的容量,这个容量远远不能满足CPU大量、高速存取的需求。此外,由于存储性能的大幅提升往往伴随着价格的同步飙升,所以出于对整体成本的控制,现实中往往采用金字塔形的多级Cache体系来实现最佳缓存效果,于是出现了二级Cache(L2 Cache)及三级Cache(L3 Cache),每一级Cache都牺牲了部分性能指标来换取更大的容量,目的是缓存更多的热点数据。以Intel家族Intel Sandy Bridge架构的CPU为例,其L1 Cache容量为64KB,访问速度为1ns左右;L2 Cache容量扩大4倍,达到256KB,访问速度则降低到3ns左右;L3 Cache的容量则扩大512倍,达到32MB,访问速度也下降到12ns左右,即使如此,也比访问主存的100ns(40ns+65ns)快一个数量级。此外,L3 Cache是被一个Socket上的所有CPU Core共享的,其实最早的L3 Cache被应用在AMD发布的K6-III处理器上,当时的L3 Cache受限于制造工艺,并没有被集成到CPU内部,而是集成在主板上。
下面给出了Intel Sandy Bridge CPU的架构图,我们可以看出,CPU如果要访问内存中的数据,则要经过L1、L2与L3这三道关卡后才能抵达目的地,这个过程并不是“皇上”(CPU)亲自出马,而是交由3个级别的贵妃(Cache)们层层转发“圣旨”(内存指令),最终抵达“后宫”(内存)。
2 多核CPU与内存共享的问题
现在恐怕很难再找到单核心的CPU了,即使是我们的智能手机,也至少是双核的了,那么问题就来了:在多核CPU的情况下,如何共享内存?
如果擅长多线程高级编程,那么你肯定会毫不犹豫地给出以下伪代码解决方案:
synchronized(memory)
如果真这么简单,那么这个世界上就不会只剩下两家独大的主流CPU制造商了,而且可怜的AMD一直被Intel“吊打”。
多核心CPU共享内存的问题也被称为Cache一致性问题,简单地说,就是多个CPU核心所看到的Cache数据应该是一致的,在某个数据被某个CPU写入自己的Cache(L1 Cache)以后,其他CPU都应该能看到相同的Cache数据;如果自己的Cache中有旧数据,则抛弃旧数据。考虑到每个CPU有自己内部独占的Cache,所以这个问题与分布式Cache保持同步的问题是同一类问题。来自Intel的MESI协议是目前业界公认的Cache一致性问题的最佳方案,大多数SMP架构都采用了这一方案,虽然该协议是一个CPU内部的协议,但由于它对我们理解内存模型及解决分布式系统中的数据一致性问题有重要的参考价值,所以在这里我们对它进行简单介绍。
首先,我们说说Cache Line,如果有印象的话,则你会发现I/O操作从来不以字节为单位,而是以“块”为单位,这里有两个原因:首先,因为I/O操作比较慢,所以读一个字节与一次读连续N个字节所花费的时间基本相同;其次,数据访问往往具有空间连续性的特征,即我们通常会访问空间上连续的一些数据。举个例子,访问数组时通常会循环遍历,比如查找某个值或者进行比较等,如果把数组中连续的几个字节都读到内存中,那么CPU的处理速度会提升几倍。对于CPU来说,由于Memory也是慢速的外部组件,所以针对Memory的读写也采用类似I/O块的方式就不足为奇了。实际上,CPU Cache里的最小存储单元就是Cache Line,Intel CPU的一个Cache Line存储64个字节,每一级Cache都被划分为很多组Cache Line,典型的情况是4条Cache Line为一组,当Cache从Memory中加载数据时,一次加载一条Cache Line的数据。下图给出了Cache的结构。

每个Cache Line的头部有两个Bit来表示自身的状态,总共有4种状态。
-
M(Modified):修改状态,其他CPU上没有数据的副本,并且在本CPU上被修改过,与存储器中的数据不一致,最终必然会引发系统总线的写指令,将Cache
Line中的数据写回到Memory中。
-
E(Exclusive):独占状态,表示当前Cache Line中包含的数据与Memory中的数据一致,此外,其他CPU上没有数据的副本。
-
S(Shared):共享状态,表示Cache
Line中包含的数据与Memory中的数据一致,而且在当前CPU和至少在其他某个CPU中有副本。
-
I(Invalid):无效状态,当前Cache Line中没有有效数据或者该Cache
Line数据已经失效,不能再用,当Cache要加载新数据时,优先选择此状态的Cache Line,此外,Cache Line的初始状态也是I状态。
MESI协议是用Cache Line的上述4种状态命名的,对Cache的读写操作引发了Cache Line的状态变化,因而可以理解为一种状态机模型。但MESI的复杂和独特之处在于状态有两种视角:一种是当前读写操作(Local Read/Write)所在CPU看到的自身的Cache Line状态及其他CPU上对应的Cache Line状态;另一种是一个CPU上的Cache Line状态的变迁会导致其他CPU上对应的Cache Line的状态变迁。如下所示为MESI协议的状态图。
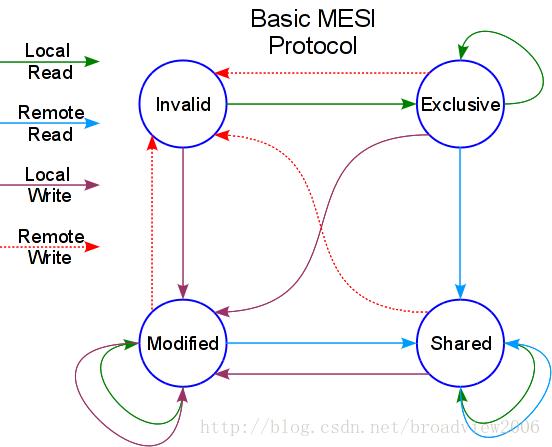
结合这个状态图,我们深入分析MESI协议的一些实现细节。
(1)某个CPU(CPU A)发起本地读请求(Local Read),比如读取某个内存地址的变量,如果此时所有CPU的Cache中都没加载此内存地址,即此内存地址对应的Cache Line为无效状态(Invalid),则CPU A中的Cache会发起一个到Memory的内存Load指令,在相应的Cache Line中完成内存加载后,此Cache Line的状态会被标记为Exclusive。接下来,如果其他CPU(CPU B)在总线上也发起对同一个内存地址的读请求,则这个读请求会被CPU A嗅探到(SNOOP),然后CPU A在内存总线上复制一份Cache Line作为应答,并将自身的Cache Line状态改为Shared,同时CPU B收到来自总线的应答并保存到自己的Cache里,也修改对应的Cache Line状态为Shared。
(2)某个CPU(CPU A)发起本地写请求(Local Write),比如对某个内存地址的变量赋值,如果此时所有CPU的Cache中都没加载此内存地址,即此内存地址对应的Cache Line为无效状态(Invalid),则CPU A中的Cache Line保存了最新的内存变量值后,其状态被修改为Modified。随后,如果CPU B发起对同一个变量的读操作(Remote Read),则CPU A在总线上嗅探到这个读请求以后,先将Cache Line里修改过的数据回写(Write Back)到Memory中,然后在内存总线上复制一份Cache Line作为应答,最后将自身的Cache Line状态修改为Shared,由此产生的结果是CPU A与CPU B里对应的Cache Line状态都为Shared。
(3)以上面第2条内容为基础,CPU A发起本地写请求并导致自身的Cache Line状态变为Modified,如果此时CPU B发起同一个内存地址的写请求(Remote Write),则我们看到状态图里此时CPU A的Cache Line状态为Invalid,其原因如下。
CPU B此时发出的是一个特殊的请求——读并且打算修改数据,当CPU A从总线上嗅探到这个请求后,会先阻止此请求并取得总线的控制权(Takes Control of Bus),随后将Cache Line里修改过的数据回写道Memory中,再将此Cache Line的状态修改为Invalid(这是因为其他CPU要改数据,所以没必要改为Shared)。与此同时,CPU B发现之前的请求并没有得到响应,于是重新发起一次请求,此时由于所有CPU的Cache里都没有内存副本了,所以CPU B的Cache就从Memory中加载最新的数据到Cache Line中,随后修改数据,然后改变Cache Line的状态为Modified。
(4)如果内存中的某个变量被多个CPU加载到各自的Cache中,从而使得变量对应的Cache Line状态为Shared,若此时某个CPU打算对此变量进行写操作,则会导致所有拥有此变量缓存的CPU的Cache Line状态都变为Invalid,这是引发性能下降的一种典型Cache Miss问题。
在理解了MESI协议以后,我们明白了一个重要的事实,即存在多个处理器时,对共享变量的修改操作会涉及多个CPU之间的协调问题及Cache失效问题,这就引发了著名的“Cache伪共享”问题。
下面我们说说缓存命中的问题。如果要访问的数据不在CPU的运算单元里,则需要从缓存中加载,如果缓存中恰好有此数据而且数据有效,就命中一次(Cache Hit),反之产生一次Cache Miss,此时需要从下一级缓存或主存中再次尝试加载。根据之前的分析,如果发生了Cache Miss,则数据的访问性能瞬间下降很多!在我们需要大量加载运算的情况下,数据结构、访问方式及程序算法方面是否符合“缓存友好”的设计,就成为“量变引起质变”的关键性因素了。这也是为什么最近,国外很多大数据领域的专家都热衷于研究设计和采用新一代的数据结构和算法,而其核心之一就是“缓存友好”。
3 著名的Cache伪共享问题
Cache伪共享问题是编程中真实存在的一个问题,考虑如下所示的Java Class结构:
class MyObject
按照Java规范,MyObject的对象是在堆内存上分配空间存储的,而且a、b、c三个属性在内存空间上是近邻,如下所示。
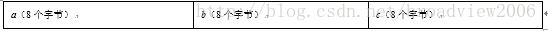
我们知道,X86的CPU中Cache Line的长度为64字节,这也就意味着MyObject的3个属性(长度之和为24字节)是完全可能加载在一个Cache Line里的。如此一来,如果我们有两个不同的线程(分别运行在两个CPU上)分别同时独立修改a与b这两个属性,那么这两个CPU上的Cache Line可能出现如下所示的情况,即a与b这两个变量被放入同一个Cache Line里,并且被两个不同的CPU共享。
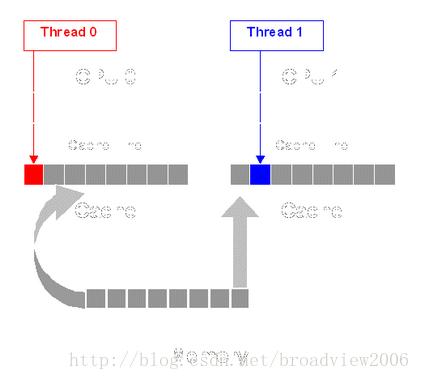
根据MESI协议的相关知识,我们知道,如果Thread 0要对a变量进行修改,则因为CPU 1上有对应的Cache Line,这会导致CPU 1的Cache Line无效,从而使得Thread 1被迫重新从Memory里获取b的内容(b并没有被其他CPU改变,这样做是因为b与a在一个Cache Line里)。同样,如果Thread 1要对b变量进行修改,则同样导致Thread 0的Cache Line失效,不得不重新从Memory里加载a。如此一来,本来是逻辑上无关的两个线程,完全可以在两个不同的CPU上同时执行,但阴差阳错地共享了同一个Cache Line并相互抢占资源,导致并行成为串行,大大降低了系统的并发性,这就是所谓的Cache伪共享。
解决Cache伪共享问题的方法很简单,将a与b两个变量分到不同的Cache Line里,通常可以用一些无用的字段填充a与b之间的空隙。由于伪共享问题对性能的影响比较大,所以JDK 8首次提供了正式的普适性的方案,即采用@Contended注解来确保一个Object或者Class里的某个属性与其他属性不在一个CacheLine里,下面的VolatileLong的多个实例之间就不会产生Cache伪共享的问题:
@Contended 4 深入理解不一致性内存
MESI协议解决了多核CPU下的Cache一致性问题,因而成为SMP架构的唯一选择。SMP架构近几年迅速在PC领域(X86)发展,一个CPU芯片上集成的CPU核心数量越来越多,到2017年,AMD的ZEN系列处理器就已经达到16核心32线程了。SMP架构是一种平行的结果,所有CPU Core都连接到一个内存总线上,它们平等访问内存,同时整个内存是统一结构、统一寻址的(Uniform Memory Architecture,UMA)。如下所示给出了SMP架构的示意图。

但是,随着CPU核心数量的不断增长,SMP架构也暴露出其天生的短板,其根本瓶颈是共享内存总线的带宽无法满足CPU数量的增加,同时,一条“马路”上通行的“车”多了,难免陷入“拥堵模式”。在这种情况下,分布式解决方案应运而生,系统的内存与CPU进行分割并捆绑在一起,形成多个独立的子系统,这些子系统之间高速互连,这就是所谓的NUMA(None Uniform Memory Architecture)架构,如下图所示。
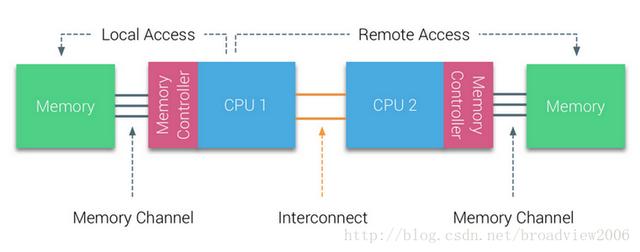
我们可以认为NUMA架构第1次打破了“大锅饭”的模式,内存不再是一个整体,而是被分割为相互独立的几块,被不同的CPU私有化(Attach到不同的CPU上)。因此,当CPU访问自身私有的内存地址时(Local Access),会很快得到响应,而如果需要访问其他CPU控制的内存数据(Remote Access),则需要通过某种互连通道(Inter-connect通道)访问,响应时间与之前相比变慢。 NUMA 的主要优点是伸缩性,NUMA的这种体系结构在设计上已经超越了SMP,可以扩展到几百个CPU而不会导致性能严重下降。
NUMA技术最早出现在20世纪80年代,主要运行在一些大中型UNIX系统中,Sequent公司是世界公认的NUMA技术领袖。早在1986年,Sequent公司就率先利用微处理器构建大型系统,开发了基于UNIX的SMP体系结构,开创了业界转入SMP领域的先河。1999年9月,IBM公司收购了Sequent公司,将NUMA技术集成到IBM UNIX阵营中,并推出了能够支持和扩展Intel平台的NUMA-Q系统及解决方案,为全球大型企业客户适应高速发展的电子商务市场提供了更加多样化、高可扩展性及易于管理的选择,成为NUMA技术的领先开发者与革新者。随后很多老牌UNIX服务器厂商也采用了NUMA技术,例如IBM、Sun、惠普、Unisys、SGI等公司。2000年全球互联网泡沫破灭后,X86+Linux系统开始以低廉的成本侵占UNIX的地盘,AMD率先在其AMD Opteron系列处理器中的X86 CPU上实现了NUMA架构,Intel也跟进并在Intel Nehalem中实现了NUMA架构(Intel服务器芯片志强E5500以上的CPU和桌面的i3、i5、i7均基于此架构),至此NUMA这个贵族技术开始真正走入平常百姓家。
下面我们详细分析一下NUMA技术的特点。首先,NUMA架构中引入了一个重要的新名词——Node,一个Node由一个或者多个Socket Socket组成,即物理上的一个或多个CPU芯片组成一个逻辑上的Node。如下所示为来自Dell PowerEdge系列服务器的说明手册中的NUMA的图片,4个Intel Xeon E5-4600处理器形成4个独立的NUMA Node,由于每个Intel Xeon E5-4600为8 Core,支持双线程,所以每个Node里的Logic CPU数量为16个,占每个Node分配系统总内存的1/4,每个Node之间通过Intel QPI(QuickPath Interconnect)技术形成了点到点的全互连处理器系统。
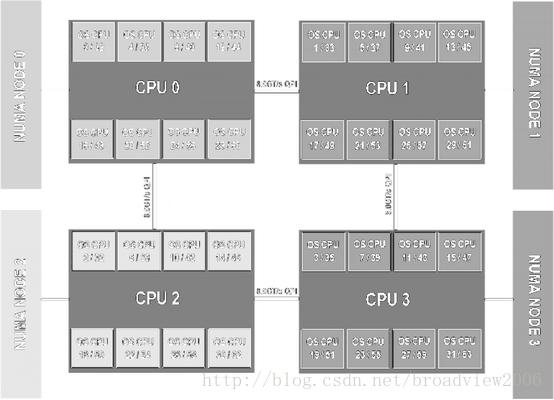
其次,我们看到NUMA这种基于点到点的全互连处理器系统与传统的基于共享总线的处理器系统的SMP还是有巨大差异的。在这种情况下无法通过嗅探总线的方式来实现Cache一致性,因此为了实现NUMA架构下的Cache一致性,Intel引入了MESI协议的一个扩展协议——MESIF。MESIF采用了一种基于目录表的实现方案,该协议由Boxboro-EX处理器系统实现,但独立研究MESIF协议并没有太大的意义,因为目前Intel并没有公开Boxboro-EX处理器系统的详细设计文档。
最后,我们说说NUMA架构的当前困境与我们对其未来的展望。
NUMA架构由于打破了传统的“全局内存”概念,目前在编程语言方面还没有任何一种语言从内存模型上支持它,所以当前很难开发适应NUMA的软件。但这方面已经有很多尝试和进展了。Java在支持NUMA的系统里,可以开启基于NUMA的内存分配方案,使得当前线程所需的内存从对应的Node上分配,从而大大加快对象的创建过程。在大数据领域,NUMA系统正发挥着越来越强大的作用,SAP的高端大数据系统HANA被SGI在其UV NUMA Systems上实现了良好的水平扩展。据说微软将会把SQL Server引入到Linux上,如此一来,很多潜在客户将有机会在SGI提供的大型NUMA机器上高速运行多个SQL Server实例。在云计算与虚拟化方面,OpenStack与VMware已经支持基于NUMA技术的虚机分配能力,使得不同的虚机运行在不同的Core上,同时虚机的内存不会跨越多个NUMA Node。
NUMA技术也会推进基于多进程的高性能单机分布式系统的发展,即在4个Socket、每个Socket为16Core的强大机器里,只要启动4个进程,通过NUMA技术将每个进程绑定到一个Socket上,并保证每个进程只访问不超过Node本地的内存,即可让系统进行最高性能的并发,而进程间的通信通过高性能进程间的通信技术实现即可。返回搜狐,查看更多