[转载]机器学习优化方法总结:SGD,Momentum,AdaGrad,RMSProp,Adam
https://blog.csdn.net/u010089444/article/details/76725843
这篇博客格式不好直接粘贴,就不附原文了。
有几个点可以注意下,原文没有写的很清楚:
-
优化方法的作用是什么?
可以说,没有优化方法,机器学习模型一般一样可以执行,所以说它并不是必须的。但是优化方法可以动态调整学习率以及影响迭代中参数调整的方向和幅度,可以加速收敛,是对原方法的一种优化。
-
Momentum:
Momentum方法一般用来辅助SGD,从下图也能看出来:
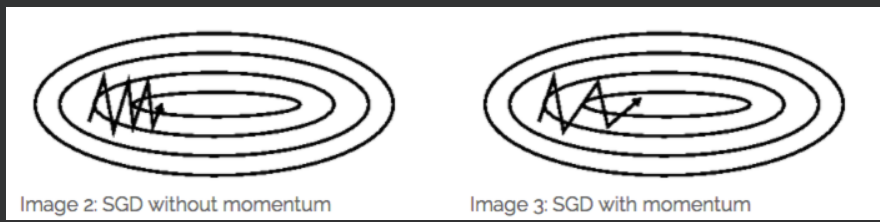
它的作用是加速SGD,并且抑制震荡。
另外,从原理上来说,它应用在BGD上也没有什么问题。
-
Nesterov Momentum方法是Momentum方法的一种改进,思路也是和传统的思路比较类似的:传统思路中,在一次参数更新中,更新后面的参数如果要使用前面的参数,则使用本次更新中前面参数已经更新了的值可以加速收敛。这里是反过来了:先更新vt,后更新梯度。但是vt的计算中要用到梯度,这里就使用梯度更新后的值可以使得结果更加准确、收敛更快。但是这时更新值还没有计算出来,于是使用了”预测“值,J中的梯度计算取的是迭代公式中的线性部分。
-
什么是”矩估计“
来源:https://baike.baidu.com/item/%E7%9F%A9%E4%BC%B0%E8%AE%A1
矩估计,即矩估计法,也称“矩法估计”,就是利用样本矩来估计总体中相应的参数。首先推导涉及感兴趣的参数的总体矩(即所考虑的随机变量的幂的期望值)的方程。然后取出一个样本并从这个样本估计总体矩。接着使用样本矩取代(未知的)总体矩,解出感兴趣的参数。从而得到那些参数的估计。
其实就是用样本估计总体
在实际应用中 ,Adam为最常用的方法,可以比较快地得到一个预估结果