一、什么是Git?
Git是一个开源的分布式版本控制系统,用于敏捷高效地处理任何或小或大的项目。
Git是Linus Torvalds为了帮助管理 Linux 内核开发而开发的一个开放源码的版本控制软件。
二、分布式VS集中式
VisualSVN、TortoiseSVN、Bazzar为集中式版本控制系统,而Mercurial、Git、Bitkeeper为分布式版本控制系统。
1. 集中式版本控制
优点:可以对具体的文件或目录进行权限控制,有全局的版本号。
缺点:所有操作都需要联网中心服务器。
2. 分布式版本控制
优点:
i. 分支管理。
ii. 完整性和安全性更高,各客户端保留有完整的版本库。
iii. 绝大部分操作都是本地化的,支持离线。
缺点:
i. 对版本库的目录和文件无法做到精细化的权限控制。
ii. 无全局性的版本号。
通过以上分析的集中式和分布式版本控制的优缺点,我们就能总结出以Git为代表的分布式版本控制和以SVN为代表的集中式版本控制之间的区别。
3. Git和SVN的区别
- 最核心的区别当然是分布式和集中式。
- 处理数据的方式不同,Git以元数据方式存储数据,SVN按照文件存储,对应的取出数据方式也不一样。
- 分支管理或分支模型(下文会详解)。
- 全局性的版本号。
- 数据的完整性和安全性,分布式的更好。
三、常用的Git解决方案和代码托管平台
1.开源软件解决方案:Gitea、GitLab
2.代码托管平台:码云(Gitee)、码市(Coding)、GitHub、GitLab、Bitbucket
四、Git的基石SHA-1
In cryptography, SHA-1 (Secure Hash Algorithm 1) is a cryptographichash function which takes an input and produces a 160-bit (20-byte) hash value known as a message digest – typically rendered as ahexadecimal number, 40 digits long. It was designed by the UnitedStates National Security Agency, and is a U.S. Federal InformationProcessing Standard.
以上摘自维基百科,主要说明了SHA是一个密码散列函数家族,是FIPS所认证的安全散列算法。能计算出一个数字消息所对应到的,长度固定的字符串(又称消息摘要)的算法。且若输入的消息不同,它们对应到不同字符串的机率很高。SHA-1长度为20字节,160位,熟悉网络编程的都知道,4位可以转换成一个十六进制的数字,所以一个SHA-1散列可以展示为40长度的十六进制的数字。
SHA-1的计算方法伪代码:
1 //Note: All variables are unsigned 32 bits and wrap modulo 232 when calculating 2 3 //Initial variables: 4 h0 := 0x67452301 5 h1 := 0xEFCDAB89 6 h2 := 0x98BADCFE 7 h3 := 0x10325476 8 h4 := 0xC3D2E1F0 9 10 //Pre-processing: 11 append the bit '1' to the message 12 append k bits '0', where k is the minimum number >= 0 such that the resulting message 13 length (in bits) is congruent to 448(mod 512) 14 append length of message (before pre-processing), in bits, as 64-bit big-endian integer 15 16 //Process the message in successive 512-bit chunks: 17 break message into 512-bit chunks 18 for each chunk 19 break chunk into sixteen 32-bit big-endian words w[i], 0 ≤ i ≤ 15 20 21 //Extend the sixteen 32-bit words into eighty 32-bit words: 22 for i from 16 to 79 23 w[i] := (w[i-3] xor w[i-8] xor w[i-14] xor w[i-16]) leftrotate 1 24 25 //Initialize hash value for this chunk: 26 a := h0 27 b := h1 28 c := h2 29 d := h3 30 e := h4 31 32 //Main loop: 33 for i from 0 to 79 34 if 0 ≤ i ≤ 19 then 35 f := (b and c) or ((not b) and d) 36 k := 0x5A827999 37 else if 20 ≤ i ≤ 39 38 f := b xor c xor d 39 k := 0x6ED9EBA1 40 else if 40 ≤ i ≤ 59 41 f := (b and c) or (b and d) or(c and d) 42 k := 0x8F1BBCDC 43 else if 60 ≤ i ≤ 79 44 f := b xor c xor d 45 k := 0xCA62C1D6 46 temp := (a leftrotate 5) + f + e + k + w[i] 47 e := d 48 d := c 49 c := b leftrotate 30 50 b := a 51 a := temp 52 53 //Add this chunk's hash to result so far: 54 h0 := h0 + a 55 h1 := h1 + b 56 h2 := h2 + c 57 h3 := h3 + d 58 h4 := h4 + e 59 60 //Produce the final hash value (big-endian): 61 digest = hash = h0 append h1 append h2 append h3 append h4
虽然SHA-1作为数字签名的算法不安全,但是作为日常项目代码管理来说却足够能够保证其唯一性。
我们已经了解到SHA-1摘要的长度是20字节,也就是160位。要确保有50%的概率出现一次冲突,需要2^80个随机散列的对象(计算冲突概率的公式是p=(n(n-1)/2)*(1/2^160))。2^80=1.2*10^24,也就是一亿亿亿,这是地球上沙粒总数的1200倍。即使按照目前公开的2005年CRYPTO会议中由王小云提出的更具效率的SHA-1攻击法,也需要2^63=9.2*10^18,也就是九十二亿亿,虽然不及地球上的沙粒数也是一个很大的数字。
超大型项目Linux内核有超过45万次提交,包含360万个对象,也至多需要前11个字符就能够保证SHA-1的唯一性。
Git根据文件内容或目录结构计算出SHA-1散列值,然后通过散列值存储、检索和处理信息。
五、Git模型
1. 区域模型
Git项目中的主要区域:Git目录(仓库)、工作目录和暂存区(索引)
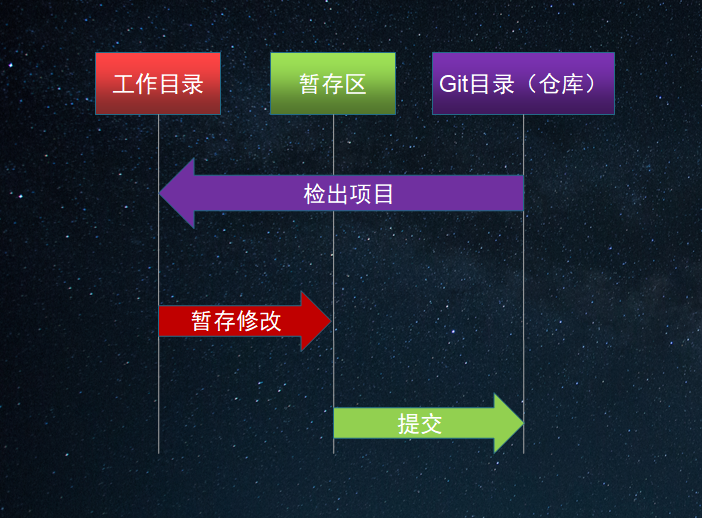
Git目录也称为Git仓库或Git数据库,是保存Git项目元数据和对象数据库的地方。是Git最重要的部分,当从其它计算机中克隆项目时需要复制的内容。
工作目录是项目某个版本的单次检出。这些文件从Git仓库中提取出来,放置在磁盘上使用和修改。我们平时码代码时的区域就是在工作目录中,因为这里是唯一提供了对文件进行编辑的地方。
暂存区也称为索引,是一个文件,一般位于Git目录中。保存了下次所要提交内容的相关信息。Git的add命令就是将工作目录中的内容添加到暂存区中。
2. 分支模型
分支模型是Git的精髓,被称为Git的“杀手锏特性”。
分支意味着偏离开发主线并继续你自己的工作而不影响主线开发。在其它很多版本控制工具中,有较昂贵的成本,因为常常需要去对整个源代码目录进行一次复制,特别对于大型项目,这样的复制时间成本是很高的。
Git的分支与众不同的地方在于,极致的轻量,几乎即时就可以完成分支操作,分支间的切换操作也很方便。
Git以快照的方式存储数据。
当发起提交时,Git存储的是提交对象(commit object),其中包含了指向暂存区快照的指针。提交对象也包含作者的姓名和邮箱地址、已输入的提交信息以及指向其父提交的指针。初始提交没有父提交,而一般的提交会有一个父提交;对于两个或更多分支的合并提交,存在多个父提交。
当执行git commit进行提交时,Git会先为每个子目录计算校验和,然后再把这些树对象(tree object)保存到Git仓库中,Git随后会创建提交对象,其中包括元数据以及指向项目根目录的树对象的指针,以便有需要的时候重新创建这次快照。
Git分支只不过是一个指向某次提交的轻量级的可移动指针。Git默认的分支名称是master。当你发起提交时,你的当前分支比如master分支就会移动指向你刚刚的提交。
git init命令默认创建的就是master分支。
Git的分支实际上就是一个简单的文件,其中只包含了该分支所指向提交的长度为40个字符的SHA-1校验和。正因如此,Git分支的创建和删除成本就很低。创建新分支就如同向文件写入40个字符外加一个换行符一样简单方便。
提交时Git保存了父对象的指针,当进行合并操作时Git会自动寻找适当的合并基础,创建新分支并在其上coding,然后把多个分支间的代码进行合并很方便,所以Git鼓励开发人员创建和使用分支。
接下来我们来了解几个分支概念
长期分支VS主题分支
主题分支是指短期的、用于实现某一特定功能及其相关工作的分支。与之相对的就是长期分支,长期分支是在整个项目中会一直保持,用于合并主题分支或版本控制和代码发布的分支。比如在master分支上存放稳定版的代码,develop上进行开发,test分支上进行测试,在iss-email上进行email的主题开发。
远程分支VS跟踪分支
远程分支是指向远程仓库的分支的指针,这些指针存在于本地且无法被移动。基于远程分支创建的本地分支就是其远程分支的跟踪分支(tracking branch),有时也叫做上游分支(upstream branch)。远程分支我们能够理解是在服务器上的分支,那跟踪分支呢?我随便创建的本地分支都是跟踪分支吗?本地非跟踪分支和跟踪分支又有什么区别呢?
当你克隆一个远程仓库时,Git默认情况下会自动创建跟踪着远程origin/master分支的本地master分支。当你试图执行分支切换操作时,如果该分支尚未被创建,并且该分支名称和某个远程分支名称一致,那么Git会帮你创建跟踪分支。当设置成为跟踪分支后,使用Git命令时可以简化操作,比如在master分支上push代码到远程仓库上,可以直接使用git push,如果没设置跟踪分支需要使用git push origin/master。
$git checkout --track origin/serverfix Branch serverfix set up to track remote branch serverfix from origin. Switched to new Branch 'serverfix'
$git checkout -b sf origin/serverfix Branch sf set up to track remote branch serverfix from origin. Switch to a new branch 'sf'
当我们了解了Git的分支模型后,分支模型正确的打开方式是什么样的呢?
假设你在master分支上做了一些项目起始的工作,之后为了实现某个需求,创建并切换到主题分支sub-record,并在其上做了一些开发工作。之后,你又尝试另一种能实现需求的方式,创建并切换到新的分支sub-recordv1。接着你又切换回master分支并继续工作了一段时间,最后你创建了新的分支dumb-idea来实现你的一个不确定的想法。
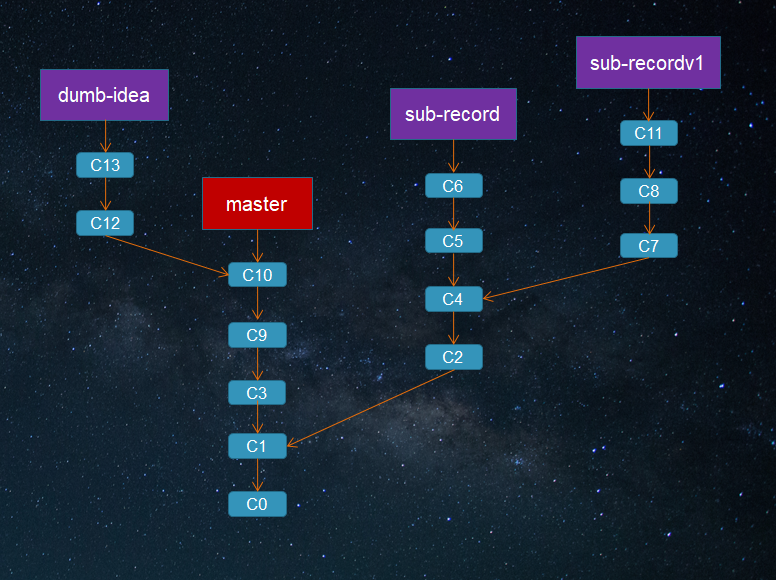
最后你觉得sub-recordv1方案效率比较高,而在dumb-idea上的工作同事们都觉得很有意义,那么把主题分支上的提交并合并入长期分支master,舍弃掉sub-record上的C5和C6提交。
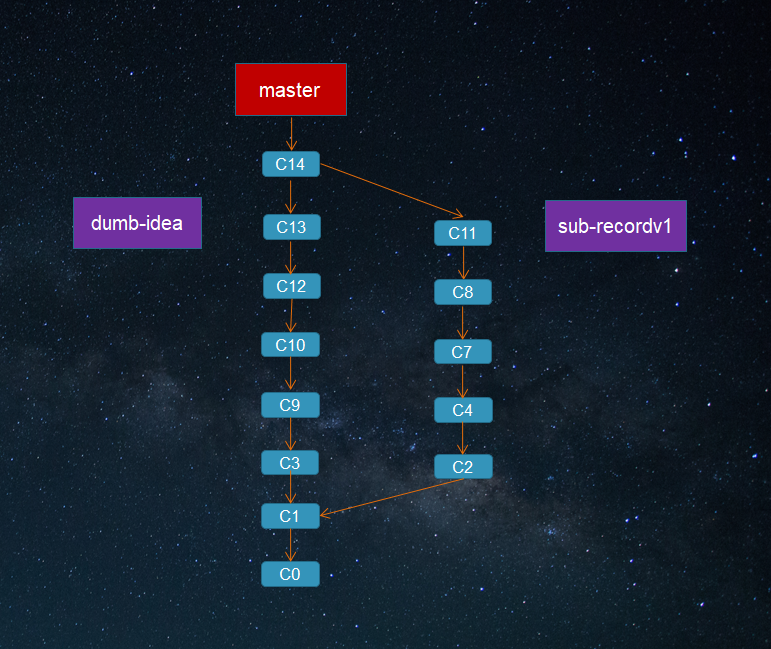
根据项目的需要,为实现一个需求或一个子需求甚至一个想法创建一个分支。合并代码的时候只需要合并需要的,那些暂时没能合并入的代码也许以后要么直接或间接就可以用上,如果没能用上也可以借鉴和参考。毕竟创建和使用Git分支的成本很低而且方便有效,这样才是Git分支模型的正确打开方式。
3. 对象模型
对象模型分为:主要对象和标签对象。主要对象又分为blob对象、树对象和提交对象。
blob对象是保存到Git仓库的文件当前版本或者称为元数据。可以理解为文件内容。
树对象解决的是文件名的存储问题。可以认为是目录,对应为Unix目录项。单个树对象包含一个或多个树条目,每个条目包含一个指向blob对象或子树的指针以及相关模式、类型和文件名。
提交对象指定了此刻项目快照的顶层树对象、作者/提交者信息、提交时间戳、一个空行以及提交消息。指向的是树对象。
标签对象与提交对象非常相似,包含了标签的创建者、日期、标签消息和一个指针。通常指向提交对象也可以指向blob对象。是不可变的分支引用,总是指向相同的提交对象或blob对象。
4. “三棵树”模型
将Git类比为三棵树的内容管理器。“树”实际上指的是“文件的集合”,并非特定的数据结构。
| 三棵树 | HEAD | 最近提交的快照,下次提交的父提交 |
| 索引 | 预计的下一次提交的快照 | |
| 工作目录 | 沙盒 |
HEAD和索引这两棵树把数据以一种高效但不够直观的方式保存在.git目录中。而工作目录则将其提取成实际的文件,以便于编辑。可以把工作目录当作沙盒,在将内容提交到暂存区(索引)并写入历史记录之前,你可以随意修改。
三棵树之间的切换
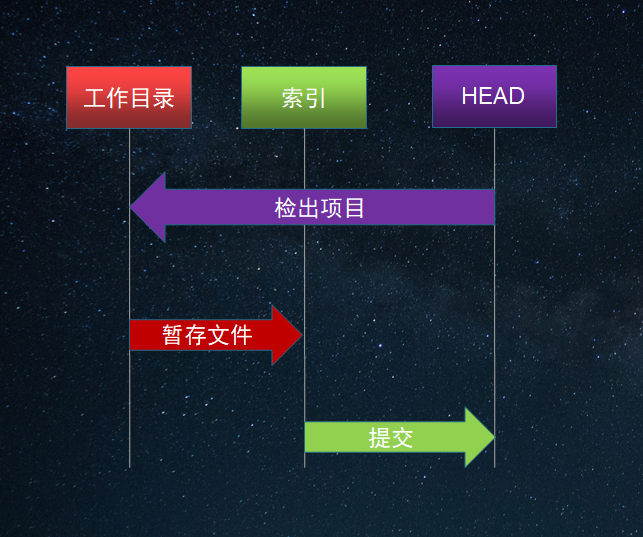
$git status Changes to be committed: (use "git restore --staged <file>..."to unstage) Changes not staged for commit: (use "git add <file>..." to update what will be committed) (use "git restore <file>..." to discard changes in working directory)
其中Changes not staged for commit提示的是索引和工作目录之间的差异。
其中Changes to be committed提示的是HEAD和索引之间的差异。
通过以上我们了解到,Git通过操作三棵树的状态来记录项目的快照。
通过学习了三棵树模型,我们将运用所学来理解Git的重置,包括两个命令:reset和checkout。
reset命令会以特定的次序重写这三棵树,操作方式如下:
(1)移动HEAD分支的指向(指定了--soft选项,则在此停止)。
(2)使索引看起来像HEAD(默认行为,或指定了--mixed选项,则在此停止)。
(3)使工作目录看起来像索引(指定了--hard选项,则在此停止)。
checkout命令操作三棵树有两种方式:
方式一(不使用路径):
(1)与reset --hard不同,checkout不会影响工作目录。他会确保不会破坏已更改的文件。
(2)更新HEAD的方式。reset移动的是HEAD指向的分支,而checkout移动的是HEAD,使其指向其他分支。
假设我们有两个分支:master和develop,分别指向不同的提交。我们当前处在develop分支(因为HEAD也指向该分支)。如果执行git reset master,那么develop会与master一样,指向同一提交。如果执行的是git checkout master,那么发生移动的会是HEAD,而不是develop。HEAD将会指向master。
方式二(使用路径):
加上文件路径,与reset一样,不会移动HEAD。会使用提交中的文件来更新索引,但是也会覆盖工作目录中对应的文件。
reset和checkout命令速查表
| 操作 | HEAD | 索引 | 工作目录 | 工作目录是否安全? | |
| 提交级别 | reset --soft [commit] | REF | 否 | 否 | 是 |
| reset [commit] | REF | 是 | 否 | 是 | |
| reset --hard [commit] | REF | 是 | 是 | 否 | |
| checkout [commit] | HEAD | 是 | 是 | 是 | |
| 文件级别 | reset (commit) [file] | 否 | 是 | 否 | 是 |
| checkout (commit) [file] | 否 | 是 | 是 | 否 | |
HEAD一列中的REF表示该命令移动了HEAD指向的引用(分支),HEAD表示移动了HEAD自身。
注意:“工作目录是否安全”一列,如果显示是否,应当慎重,执行前要考虑清楚,否则可能丢失工作成果。
六、文件状态的生命周期
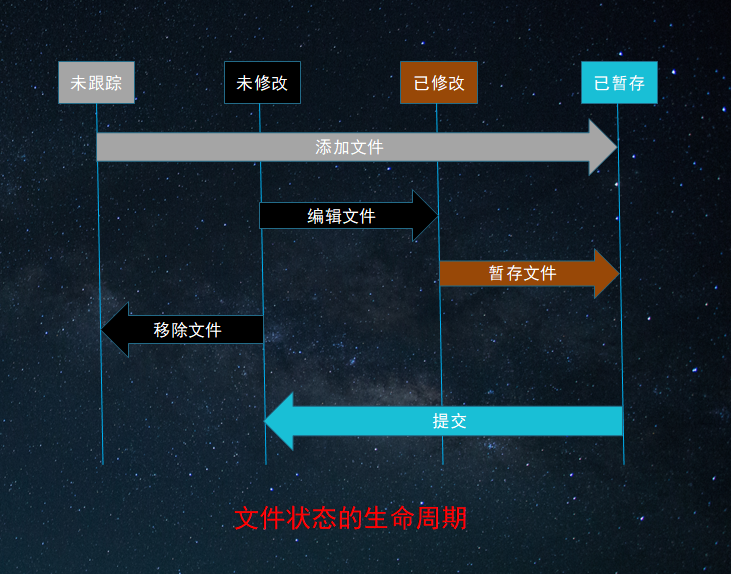
七、提交史观
| 代表观点 | 提交史观 | 代表命令 |
| “史书”、“记录” | Git仓库提交历史就是实际发生过的事件的记录 | merge |
| “故事” | Git提交历史是关于项目如何构建的故事 | rebase |
变基操作是把某条分支线上的工作在另一个分支线上按顺序重现。而合并操作则是找出两个分支的末端,并把它们合并到一起。
最好的操作方式是,在本地尚未推送的更改进行变基操作,从而简化提交历史,但决不能对任何已经推送到服务器的更改进行变基操作。
八、分布式工作流
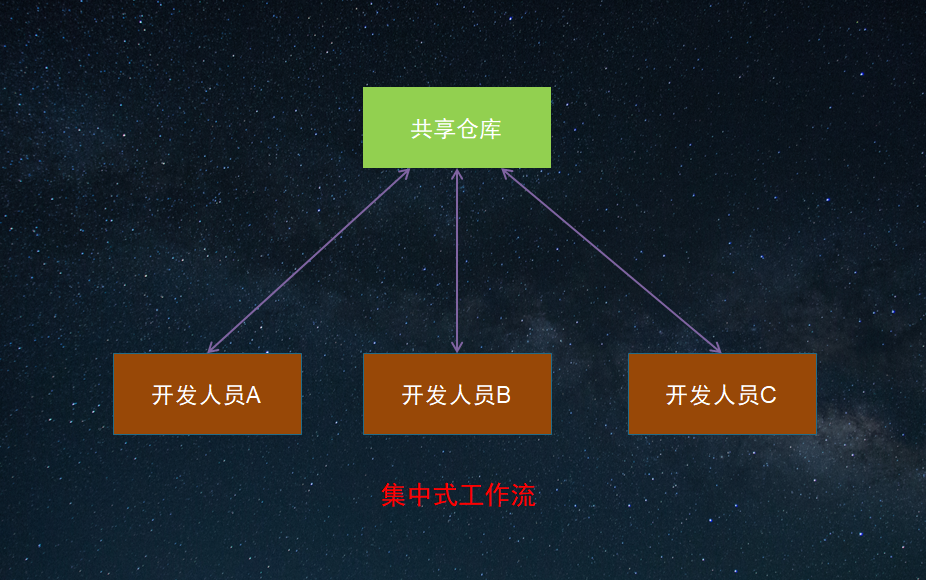
1. 集中式工作流
一个中枢(或是仓库)接受代码,所有人以此同步各自的工作。
2. 集成管理者工作流
(1)项目维护人员推送到公开仓库。
(2)贡献者克隆该仓库,作出自己的修改。
(3)贡献者推送到自己的公开仓库副本。
(4)贡献者向维护人员发送电子邮件,要求合并变更。
(5)维护人员将贡献者的仓库添加为远程仓库并在本地进行合并。
(6)维护人员将合并后的变更推送到主仓库。

3. 司令官与副官工作流
(1)普通开发人员使用自己的主题分支,根据参考仓库(reference repository)拉取项目或进行变基。
(2)副官将开发人员的主题分支合并入master分支。
(3)司令官将副官的master分支合并入自己的master分支。
(4)司令官将其master分支推送到参考仓库,同时其他开发人员以此为基础进行变基操作。

参考资料
[1] Scott Chacon,Ben Straub《精通Git》(第2版)
[2] 维基百科
[3] https://www.sohu.com/a/234659269_575744
[4] https://www.runoob.com/git/git-tutorial.html