谁创造了AlexNet?
AlexNet是有Hinton大神的弟子Alex Krizhevsky提出的深度卷积神经网络。它可视为LeNet的更深更宽的版本。
AlexNet主要用到的技术
- 成功使用ReLU作为CNN的激活函数,并验证了其效果在较深的神经网络超过了sigmiod,成功解决了sigmoid在网络较深时的梯度弥散问题。
- 训练时候使用Dropout以一定概率随机失活了一部分神经元,一面模型过拟合。
- 使用重叠最大池化方法:池化核尺寸大于步长,是的卷积层的输出之间有重叠部分,提升了特征的丰富性。
- 提出了LRN(局部相应归一化),对局部神经元创建竞争机制,使得响应大的神经元输出变得更大,抑制了反馈较小的神经元。一定程度提升了泛化能力。
- 使用CUDA加速,两块GTX 580 3GB 显卡加速。这导致论文中的网络结构图分为两路训练。
- 采用数据增强:随机地从226*226的原图中截取224*224大小的区域(水平翻转以及镜像),数据增强有效抑制过拟合,提高泛化能力。
网络结构
整个AlexNet有8个需要训练的层(不包含LRN和池化层),前5层是卷积层,后三层是全连接层,其中最后的全连接层输出是一个1000通道softmax映射归一化结果,表示输入在1000类别的响应情况,或者说在归属类上的概率分布,再细致的说就是每个通道的softmax输出表示输入属于该类的可能性。由于当时显存容量的限制,作者使用了2块GTX580 3GB RAM 的GPU并行训练,所以网络分成两路。
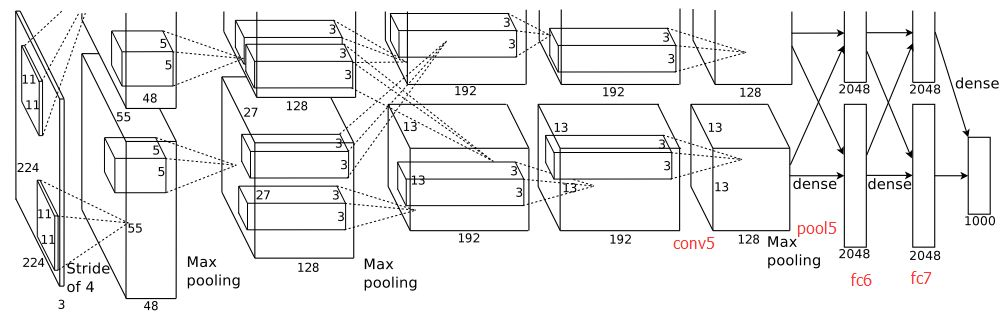
如今我们显卡已经足够,可以并成一路。
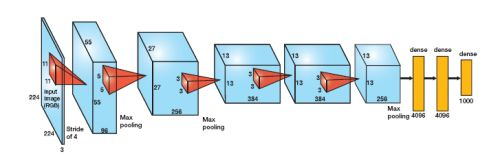
AlexNet每层的超参数及参数数量

以上的网络中:
- 5个卷积层的卷积核依次为:11*11*3@96,5*5*96@256,3*3*256@384,3*3*384@384,3*3*384@265,步长依次为4,1,1,1,1,模式为VALID,SAME,SAME,SAME,SAME
- 池化层在第①第②和第⑤个卷积层之后,每一次池化,尺寸减半。
- LRN在第①和第②的池化层和ReLU后的后的卷积层之间
- 随后就是三个全连接层,最后一个全连接层是softmax输出的结果
AlexNet的实现
(待续)
参考
https://blog.csdn.net/sun_28/article/details/52134584
《tensorflow实战》