一、查找到js的网址
在我们做爬虫的时候,如何判断一个数据是Ajax(asynchronous JavaScript And Xml,异步的JavaScript和Xml), 首先是数据的加载,在请求网页的URL一般不会改变,通过开发者工具进行如何下勾选。

就可以在下面中看到来源,通过查看js文件或者Doc文档来获取这些信息,在对js进行解析,这样就可以解决 Ajax的问题,相比较而言还是比较简单的,找到目标网站后就是对js的当进行一个解析。
可以将目标的地址,比如说图片的URL地址复制下来,在所有文档中进行一个匹配(Ctrl+F),这样就可以找到这个id是属于那个文件,在对文件进行一个解析,就可以得到想要的内容。
二、请求头的构造
我们有时候还会遇到需要带请求头的访问,因此就需要,构造一个URL
from urllib.parse import urlencode
data = {
"key_1": param_1,
"key_2": param_2
}
urlencode(data)
通过这个方法,构造一个URL进行请求,就可以了。其中的参数在如下的图进行查看。
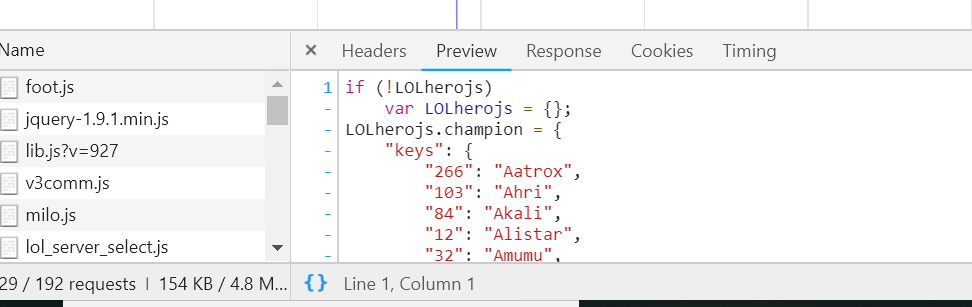
最后就是爬虫多练,多爬些网站,多掌握一些好的解析方法,做多了自然就熟了。