本章内容
- 线程
- 进程
- 协程
线程是最小的调度单位
进程是最小的管理单元
线程
多线程的特点:
- 线程的并发是利用cpu上下文切换
- 多线程的执行的顺序是无序的
- 多线程共享全局变量
- 线程是继承在进程里的,没有进程就没有线程
- GIL全局解释器锁
- 只有在进行耗时的IO操作的时候,能释放GIL,所以只要在IO密集型的代码里,用多线程就很合适
多线程的好处
- 达到充分利用CPU的目的。多线程完成cpu内核的快速切换,提高CPU的利用率
- 多线程可以防止数据阻塞问题,多条线程同时运行,哪怕一条线程的代码执行读取数据阻塞,也不会影响其它任务的执行。
- 多线程可以提高系统I/O问题的处理效率等
并行和并发
- 并行:指在同一时刻,有多条指令在多个处理器上同时执行;
- 并发:指在同一时刻,只能有一条指令执行,但多个进程指令被快速轮换执行,使得在宏观上具有多个进程同时执行的效果。
#并发
import time ,threading
def test1(n):
for i in range(n):
time.sleep(1)
print('task1',i)
def test2(n):
for i in range(n):
time.sleep(1)
print('task2',i)
thread1 = threading.Thread(target=test1,args=(10,))
thread2 = threading.Thread(target=test2,args=(10,))
thread1.start()
thread2.start()
.......................................
#运行共用10s
#无序
import time,threading
def test1(n):
time.sleep(1)
print('task',n)
for i in range(10):
thread1 = threading.Thread(target=test1,args=(i,))
thread1.start()
...............................运行结果
task 1
task 2
task 3
task 7
task 5
task 4
task 6
task 0
task 9
task 8
#共享全局变量
import threading
num=0
def test1():
global num
for i in range(10):
num+=1
def test2():
global num
print(num)
thread1 = threading.Thread(target=test1)
thread2 = threading.Thread(target=test2)
thread1.start()
thread2.start()
..............................................运行结果
10
#GIL全局解释器锁实例
import threading
global_num = 0
def test1():
global global_num
for i in range(1000000):
global_num += 1
def test2():
global global_num
for i in range(1000000):
global_num += 1
t1 = threading.Thread(target=test1)
t2 = threading.Thread(target=test2)
t1.start()
t2.start()
print(global_num)
......................................运行结果
109704
#运行结果本应该为2000000,为什么运行结果远小于应得结果?
第一个原因:运行代码后加上我们启动的两个线程,cpu共起了3个线程;其中一个用于执行代码(取名a),两个用于执行函数test1和test2(t1 t2);a线程运行到print(global_num)时,test1和test2循环还没有执行完毕!线程a就已经输出了;所以得到的值不是2000000
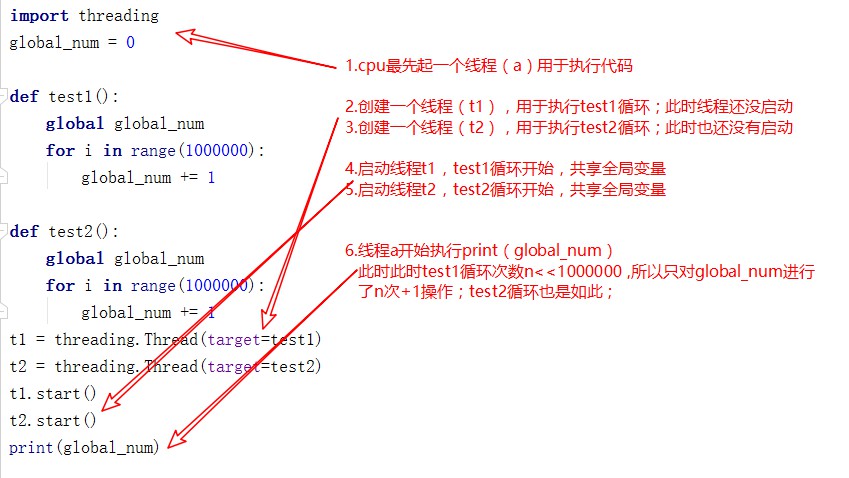
解决方法:让a线程等test1和test2循环完成之后再执行print();
#原因1解决后
import threading
global_num = 0
def test1():
global global_num
for i in range(1000000):
global_num += 1
def test2():
global global_num
for i in range(1000000):
global_num += 1
t1 = threading.Thread(target=test1)
t2 = threading.Thread(target=test2)
t1.start()
t2.start()
t1.join()
t2.join()
print(global_num)
...........................................运行结果
1240490
#为什么还是不等于2000000呢?
第二个原因:GIL全局解释器锁
GIL全局解释器锁:Global Interpreter Lock,意思就是全局解释器锁,这个GIL并不是python的特性,他是只在Cpython解释器里引入的一个概念;随着电脑多核cpu的出现核cpu频率的提升,为了充分利用多核处理器,进行多线程的编程方式更为普及,随之而来的困难是线程之间数据的一致性和状态同步,而python也利用了多核,所以也逃不开这个困难,为了解决这个数据不能同步的问题,设计了gil全局解释器锁。
gil全局解释器锁的作用:多线程共享全局变量的时候,gil全局解释器锁可以保证同一时间内只有一个线程可以拿到这个全局变量;

看图讲解:
- t1拿到全局变量count=0
- t1申请gil锁(gil全局解释器锁可以保证只有一个线程可以拿到这个全局变量)
- t1调用系统线程
- t1到cpu上执行+1操作
- t1执行操作时可能偷懒了,没加完,但时间到了t1只能把gil锁给了t2
- t2在此之前已经拿到count全局变量count=0(注意此时以为t1没执行完+1操作,count=0)
- t2拿到gil锁
- t2调用系统线程
- t2到cpu上执行+1操作
- t2勤勤恳恳的+1,在时间内完成了加一操作
- t2 完成给count赋值(此时count=1)
- t1又拿到gil锁,继续未完成的操作,
- t1完成操作并赋值给count=1,(此时count还是=1)
#解决方法:调用threading模块的lock锁
import threading
global_num = 0
lock=threading.Lock() #实例化一个lock锁
def test1():
global global_num
lock.acquire() #锁上
for i in range(1000000):
global_num += 1
lock.release() #解锁
def test2():
global global_num
lock.acquire() #锁上
for i in range(1000000):
global_num += 1
lock.release() #解锁
t1 = threading.Thread(target=test1)
t2 = threading.Thread(target=test2)
t1.start()
t2.start()
t1.join()
t2.join()
print(global_num)
.....................................运行结果
2000000
进程
- 一个程序运行起来之后,代码+用到的资源称之为进程,它是操作系统分配资源的基本单位,不仅可以通过线程完成多任务,进程也是可以的
- 进程之间是相互独立的
- 进程启动耗费的资源是比较大的,但是效率比较高
- cpu密集的时候适合用多进程
#多线程实现多任务
import multiprocessing,time
num = 10
def test1():
for i in range(num):
time.sleep(1)
print('task1',i)
def test2():
for i in range(num):
time.sleep(1)
print('task2',i)
if __name__ == '__main__':
p1 = multiprocessing.Process(target=test1)
p2 = multiprocessing.Process(target=test2)
p1.start()
p2.start()
.............................运行结果
#共运行10s
#相互独立资源不共享
import multiprocessing
num = 0
def test1 ():
global num
for i in range(10):
num+=1
print(num)
def test2():
global num
for i in range(10):
num+=1
print(num)
if __name__ == '__main__':
p1 = multiprocessing.Process(target=test1)
p2 = multiprocessing.Process(target=test2)
p1.start()
p2.start()
...............................运行结果
10
10
#进程池
import time ,multiprocessing
from multiprocessing import Pool
def test1(n):
for i in range(n):
time.sleep
print('task1',i)
def test2(n):
for i in range(n):
time.sleep(1)
print('task2',i)
if __name__ == '__main__':
pool = Pool(1) #允许最大进程数
pool.apply_async(test1,(10,)) #参数必须元组
pool.apply_async(test2,(10,))
pool.close()
pool.join()
协程
协程:也叫微线程,协程是在一个线程里面的
现有进程---> 线程 ---> 协程
- 进程是资源分配的单位
- 线程是操作系统调度的单位
- 协程的调度由所在程序自身控制
- 进程切换需要的资源最大,效率低
- 线程切换需要的资源一般,效率一般
- 协程切换任务资源很小,效率高
- 多进程、多线程根据cpu核数不一样可能是并行的,但是协成在一个线程中
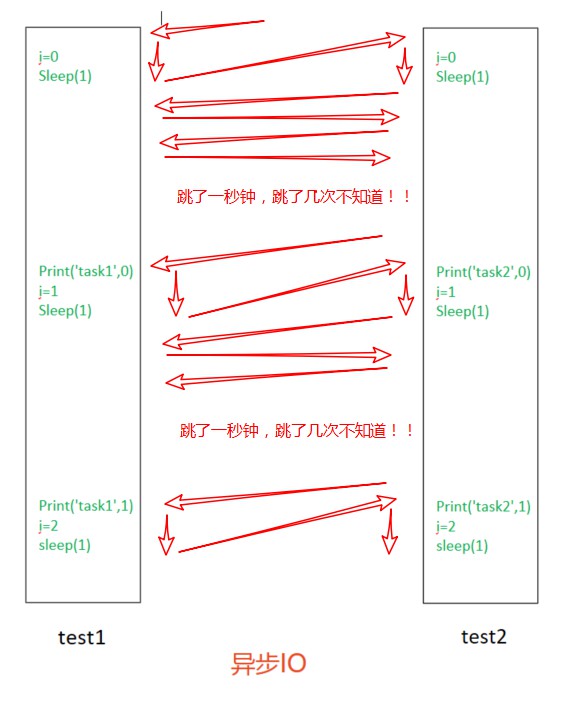
异步IO:遇到io请求就切换
第一步:pip 安装gevent模块
pip install gevent
协程实例:
#异步io
import gevent
def test1(n):
for i in range(n):
gevent.sleep(1)
print('task1',i)
def test2(n):
for i in range(n):
gevent.sleep(1)
print('task2',i)
g1 = gevent.spawn(test1,10) #协程任务g1
g2 = gevent.spawn(test2,10) #任务g2
g1.join()
g2.join()
..........................运行结果
#运行共用时10s
分析异步IO运行
协程完全靠异步IO完成两个任务:遇到io请求就切换(sleep算IO请求)