读完本系列两篇文章后,相信您会对表格中如何加索引有一个清晰的了解。
为什么索引查询速度快?
大多数人知道因为索引是一个有序的排列所以查询速度快。如果更详细的说明,这里要说到数据表格和索引的组织了。在SQL Server 2005 以前, 一个表格是以一个B树后者一个堆(Heap)存放的,每个B树或者堆,在sys.indexes里面都有一条记录相对应。SQL Server2005以后,引入了分区表(Table Partition)的概念。这里说的分区表不是咱们在解决大数据所使用表分区技术。而是数据库的存储单位“区”,一个区是8个物理上连续的页。言归正传,现在的分区基本上代替了原来表格的概念。一个分区就是一个B树或者一个堆。而一张表格则是一个到多个分区的组合。
图1显示了表的组织。表包含在一个或多个分区中,每个分区在一个堆或一个聚集索引结构包含数据行。堆的页或聚集索引的页在一个或多个分配单元中进行管理
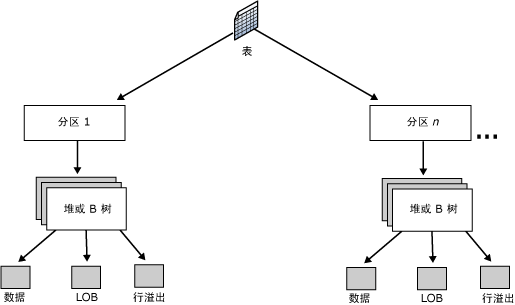
下文细说一下表格中的堆结构、聚集索引、非聚集索引。
堆结构
堆是不含聚集索引的表。SQL Server使用“索引分配映射(IAM)”页将堆的页面联系在一起。堆的特点有以下几个:
1. 堆内的数据页和行没有任何特定的顺序
在一个堆里的数据完全是随机存放的。而且SQL Server也假设数据之间没有任何联系
2. 页面也不连接在一起。
数据页之间唯一的逻辑连接是记录在IAM页内的信息。页面与页面之间没有什么紧密的联系。
3. 堆中的行一般不按照插入的顺序返回。
因为IAM按照数据页在数据文件内存在的顺序标识它们,所以这意味着堆扫描会沿每个文件进行。而不是按这些行的插入顺序,或者是任何逻辑上的顺序。
图2下图说明 SQL Server 数据库引擎 如何使用 IAM 页检索具有单个分区的堆中的数据行。
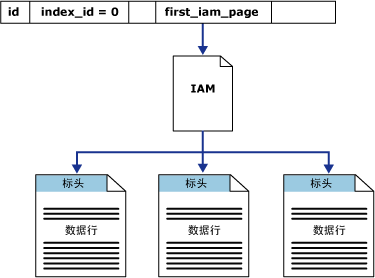
从上面的介绍我们可以看到,SQL Server针对堆的管理是比较简单的。在算法能力上也是比较弱的。不谈性能,光从数据存储管理上来讲,用堆去管理一个超大的表格是比较吃力的。所以在SQL Server里强烈建议在所有大的、经常使用的表格上都建立聚集索引。聚集索引可以帮助避免很多问题。如磁盘空间、查询性能、查询并发等。
聚集索引结构
在SQL Server中,索引是按B树结构进行组织的。索引B树中的每一页称为一个索引节点。B树的顶端节点成为根节点。索引中的底层节点称为叶节点。根节点与叶节点之间的任何索引级别统称为中间级。每个索引行包含一个键值和一个指针,该指针指向B树上的某一中间级页或叶级索引中的某个数据行。每级索引中的页均被链接在双向链接列表中。
数据链内的页和行将按聚集索引键值进行排序。所有插入操作都在所插入行中的键值与现有行中的排序顺序想匹配时进行。B树的页集合由sys.system_internals_allocation_units系统视图中的页指针来定位。
对于某个聚集索引,sys.system_internals_allocation_units中的root_page列指向该聚集索引某个特定分区的顶部。SQL Server将在索引中向下移动以查找与某个聚集索引键对应的行。为了查找键行扫描。为了查找数据页链的首页,SQL Server将从索引的根节点沿最左边的指针进行扫描。
相对于堆,聚集索引的特点有以下几个:
1. 堆内的数据也和行有严格的顺序。
聚集索引保证了表格的数据按照索引行的顺序排列。而且SQL Server知道这种顺序关系。
2. 页面链接在一起。页面与页面联系紧密。
3. 树中的行一般能够按照索引列的顺序返回。
从上面的比较我们也能看出来,建立了B树以后,SQL Server对数据也的管理能够更加快速有效有些会发生在堆上的问题就不容易在B树上发生。
图3显式了聚集索引单个分区中的结构。

非聚集索引结构
非聚集索引与聚集索引具有相同的B树结构,它们之间的显著差别在于以下两点:
- 基础表的数据行不按非聚集索引键的顺序排序和存储。
- 非聚集索引的叶层是由索引页而不是由数据页组成。
- 建立非聚集索引的表可以是一个B树,也可以是一个堆。
- 如果表是堆(意味着该表没有聚集索引),则行定位器是指向行的指针。该指针由文件标识符(ID)、页码和页上的行数生成。整个指针成为行ID(RID)。
- 如果表有聚集索引或索引视图上有聚集索引,则行定位器是行的聚集索引键。如果聚集索引键不是唯一的索引,SQL Server将添加在内部生成一个值(称为唯一值)以使所有重复键唯一。SQL Server通过使用存储在非聚集索引的叶行内的聚集索引键搜索聚集索引来检索数据行。
所以非聚集索引不会去改变或者改善数据页的存储模式。它的B树结构只针对自己的索引页面。如果问题是由堆的特性导致的。加一个非聚集索引不能带来根本的改善。
图4说明了单个分区中的非聚集索引结构
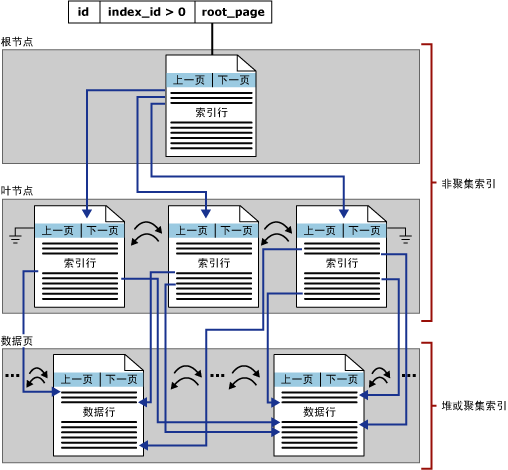
了解了以上数据存储的结构,索引为什么查询速度快,基本就没什么疑问了。 然而有时候我们虽然建立了索引却发现效能仍然得不到解决。类似这样的问题。需要从多个方面去入手。如需求、索引的设计是否合理、执行计划的选择。为了便于问题的逐一解决我们仍然需要进一步分析。对于OLTP系统一次请求的时效性是关键。影响时效性的因素一般有阻塞、死锁、锁的数量。运行SELECT、UPDATE、INSERT、DELETE语句,会申请什么样的锁,以及了解执行计划对锁申请数量的影响,了解全面方能够清楚要缓解阻塞和死锁,须在数据库调优上下什么样的功夫。这跟索引有密不可分的关系。猛戳下文…
本文引用来自微软TechNet官方资料和“SQL Server 企业级平台管理实践.”