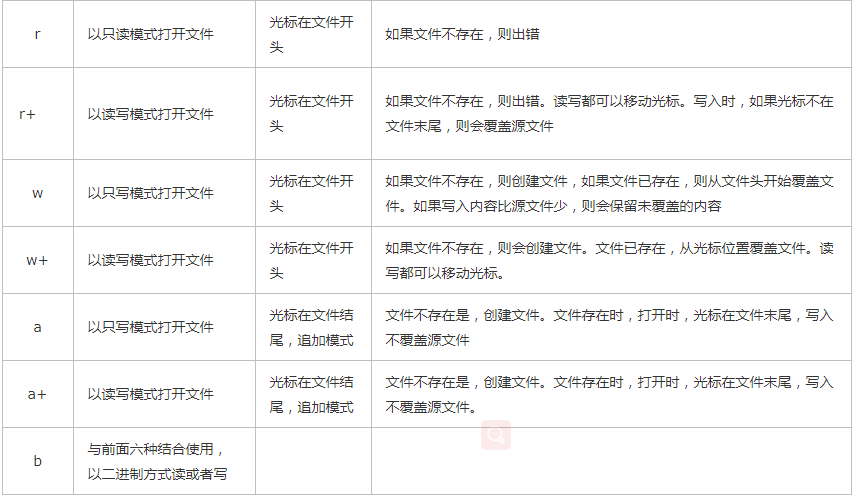
三元运算
三元运算也称三目运算,是对简单语句的简写:
# 语法
if 条件成立: val = 1 else: val = 2
# 改成三目运算val = 1 if 条件成立 else 2
三目求1-10的偶数:
print([i for i in range(1, 11) if i % 2 == 0])
文件操作
文件操作分为读、写、修改,我们分别来说下
示例1:读的模式
f = open(file='D:/read.txt',mode='r',encoding='utf-8') data = f.read() f.close() ''' 1.file = 'D:/read.txt' 表示文件路径 2.mode = 'r' 表示以读的方式的打开文件 3.encoding='utf-8' 表示将硬盘上的 0101010 按照utf-8的规则去“断句”,再将“断句”后的每一段0101010转换成unicode的 01010101,unicode对照表中有01010101和字符的对应关系。 4.f.read() 表示读取所有的内容,内容是转换完毕的字符串 5.close() 表示关闭文件
PS: 此处的encoding必须和文件在保存时设置的编码一致,不然“断句”会不准确从而造成乱码。 '''
示例2:二进制的读模式
f = open(file='D:/read.txt',mode='rb')
data = f.read()
f.close()
'''
1.file = 'D:/read.txt' 表示文件路径
2.mode = 'rb' 表示以二进制读的方式的打开文件
3.f.read() 表示读取所有内容,内容是硬盘上原来以某种编码保存的 010101010,即:某种编码格式的字节类型
4.close() 表示关闭文件
'''
注意:
- 文件操作时,以 “r”或“rb” 模式打开,则只能读,无法写入;
- 硬盘上保存的文件都是某种编码的0101010,打开时需要注意:
- rb,直接读取文件保存时原生的0101010,在Python中用字节类型表示
- r和encoding,读取硬盘的0101010,并按照encoding指定的编码格式进行断句,再将“断句”后的每一段0101010转换成unicode的 010101010101,在Python中用字符串类型表示
示例2:写的模式
f = open(file='D:/write.txt',mode='w',encoding='utf-8') f.write('写入文件') f.close() ''' file='D:/write.txt' 表示文件路径 mode='w' 表示只写 encoding='utf-8' 将要写入的unicode字符串编码成utf-8格式 f.write(...) 表示写入内容,写入的内容是unicode字符串类型,内部会根据encoding转换为制定编码的 01101010101,即:字节类型 f.close() 关闭文件 '''
示例4:二进制的写模式
f = open(file='D:/write.txt',mode='wb')
f.write('写入文件'.encode('utf-8'))
f.close()
'''
file='D:/write.txt' 表示文件路径
mode='wb' 表示只以2进制模式写
f.write(...) 表示写入内容,写入的内容必须字节类型,即:是某种编码格式的0101010
f.close()
'''
注意:
文件操作时,以 “w”或“wb” 模式打开,则只能写,并且在打开的同时会先将内容清空。
写入到硬盘上时,必须是某种编码的0101010,打开时需要注意:
- wb,写入时需要直接传入以某种编码的0100101,即:字节类型
- w 和 encoding,写入时需要传入unicode字符串,内部会根据encoding制定的编码将unicode字符串转换为该编码的 010101010
示例5:追加模式
f = open("text.txt",'a',encoding="gbk") f.write(" 追加到后边") f.close()
注意:
文件操作时,以 “a”或“ab” 模式打开,则只能追加,即:在原来内容的尾部追加内容
写入到硬盘上时,必须是某种编码的0101010,打开时需要注意:
- ab,写入时需要直接传入以某种编码的0100101,即:字节类型
- a 和 encoding,写入时需要传入unicode字符串,内部会根据encoding制定的编码将unicode字符串转换为该编码的 010101010
示例6:读写模式
f = open("read.txt",'r+',encoding="gbk") data = f.read() # 可以读内容 print(data) f.write(" test_read") # 可以写 f.close()
示例7:写读模式
f = open("read.txt",'w+',encoding="gbk") data = f.read() # 可以读内容 print(data) f.write(" test_read") # 可以写 f.close()
示例1与示例2的区别:
示例1,是以r方式打开文件,示例2是以rb的方式打开文件,rb是指二进制模式,数据读到内存里是bytes格式,如果想看内容还要手动decode,因此在文件打开阶段不需要指定编码.
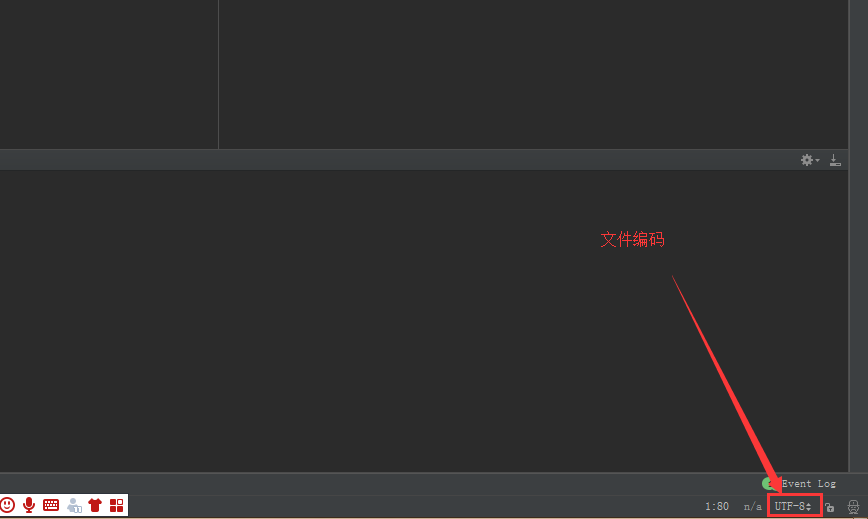
如何知道一个文件的编码:
1.Pycharm打开文件,右下角显示文件编码,如图:
2.chardet方法:
1 import chardet 2 3 f = open('read.txt',mode='rb') 4 data = f.read() 5 f.close() 6 7 result = chardet.detect(open('read.txt',mode='rb').read()) 8 print(result) 9 10 # 打印结果 11 {'encoding': 'utf-8', 'confidence': 0.99, 'language': 'Chinese'}
文件操作的其他功能


def fileno(self, *args, **kwargs): # real signature unknown 返回文件句柄在内核中的索引值,以后做IO多路复用时可以用到 def flush(self, *args, **kwargs): # real signature unknown 把文件从内存buffer里强制刷新到硬盘 def readable(self, *args, **kwargs): # real signature unknown 判断是否可读 def readline(self, *args, **kwargs): # real signature unknown 只读一行,遇到 or 为止 def seek(self, *args, **kwargs): # real signature unknown 把操作文件的光标移到指定位置 *注意seek的长度是按字节算的, 字符编码存每个字符所占的字节长度不一样。 如“路飞学城” 用gbk存是2个字节一个字,用utf-8就是3个字节,因此以gbk打开时,seek(4) 就把光标切换到了“飞”和“学”两个字中间。 但如果是utf8,seek(4)会导致,拿到了飞这个字的一部分字节,打印的话会报错,因为处理剩下的文本时发现用utf8处理不了了,因为编码对不上了。少了一个字节 def seekable(self, *args, **kwargs): # real signature unknown 判断文件是否可进行seek操作 def tell(self, *args, **kwargs): # real signature unknown 返回当前文件操作光标位置 def truncate(self, *args, **kwargs): # real signature unknown 按指定长度截断文件 *指定长度的话,就从文件开头开始截断指定长度,不指定长度的话,就从当前位置到文件尾部的内容全去掉。 def writable(self, *args, **kwargs): # real signature unknown 判断文件是否可写
总结: