当使用一个类实例化多个对象时,多个对象之间是什么关系?他们各自的数据会不会发生混淆?这次课跟大家讲解一下这个问题。学完本次课,大家应该对对象在内存中的表示方式有一个初步的了解,为理解更深入的面向对象概念打一个基础。
编程任务:小明家的狗狗
我们还是通过一个程序任务来理解相关概念。先看看任务描述:小明养了两只小狗,一只叫旺财,白色,3岁;另一只叫小强,黄色,2岁。我们通过键盘向小狗发出指令,当我们输入旺财的时候,旺财需要做自我介绍。当我们输入小强的时候,小强要做自我介绍。当我们输入的既不是旺财,又不是小强的时候,输出“木有这只小狗”。我们用面向对象的方法来完成这个任务。
创建类和对象
使用面向对象的方法编写程序,通常包含如下三个核心步骤:
1.创建与待解决问题相关的类
2.定义属于某类的对象
3.使用new关键字实例化该对象
从编程任务的描述我们可以看到。两只小狗的共同状态特征是姓名和年龄,行为特征是"自我介绍",因此,可以声明一个Dog类如下:
第一步:新建一个项目:DemoDogs
第二步:在项目中新增一个类:AppMain,项目的入口主函数main放在该类中。
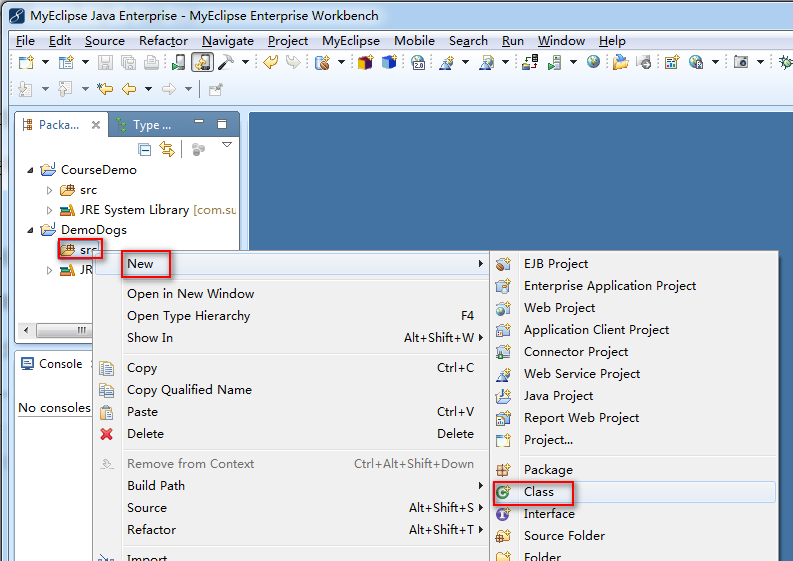
新建AppMain类
AppMain类代码如下:
第三步:在项目中新增一个类:Dog,类代码如下:
public class Dog { int age; String name; public void Introduce(){ System.out.println("我是"+name+",我今年"+age+"岁了"); } }
第四步:修改AppMain类的main函数:
public class AppMain { public static void main(String[] args) { // TODO Auto-generated method stub Dog dog1 = new Dog(); Dog dog2 = new Dog(); } }
对象实例化的过程解释
我们来看一下定义并实例化一个对象的具体过程。Dog dog1 = new Dog();这样一条语句,可以分成3个步骤来理解。在具体讲解之前,我们先要弄清一个事实:在运行程序的时候,数据是放在内存中的。

首先,Dog dog1部分,会在计算机栈内存中分配一块空间,这块空间的名称是dog1,并且dog1的值只能是一个内存地址,该地址里存放的必须是一个Dog对象。
其次,new Dog()部分,会在堆内存里面分配一块区域(在右边图中用两个橙色方格来表示,白色部分表示的是内存其它区域),假设刚分配到的这块内存区域的地址是0x1000(至于真实地址是什么,我们就没必要知道了,cpu自己知道就行了)。这块内存区域用来存放Dog对象的成员变量,即一个name成员变量和一个age成员变量。
最后,第三个步骤是赋值操作,赋值操作就是将刚才new出来的Dog对象所在的内存空间地址0x1000赋值给变量dog1。
请注意:这里将dog1称为变量,只是为了表述方便。其实dog1所代表的是内存中一个Dog对象,所以以后我们直接称dog1为对象dog1,或者实例dog1,不再称为变量。
现在我们还没有给dog1的成员变量赋任何值,也就是说我们只知道dog1是一条狗,但还不知道他叫什么,不知道他几岁。我们现在在程序里给dog1设置一些数据。
public class AppMain { public static void main(String[] args) { // TODO Auto-generated method stub Dog dog1 = new Dog(); dog1.name = "旺财"; dog1.age = 3; Dog dog2 = new Dog(); dog2.name = "小强"; dog2.age = 2; } }
这里有一点需要说明一下,对象dog1的成员name和age没有赋过任何值的时候,他们有一个默认值。任何基础数据类型的变量,如果从来没有给这个变量赋过值的话,JVM会给变量分配一个默认值。Int类型的默认值是0,string类型默认值是空字符串,空字符串用一对双引号表示。其它数据类型的默认值我们以后会慢慢接触到。如果给对象dog1的成员变量赋值,比如dog1.name=“旺财”;默认值就会更改为“旺财“。
刚才我们分析的是dog1对象在实例化时成员变量的内存结构,现在我们再分析一下成员方法的内存分配情况。JVM将成员变量存放在堆内存中,成员方法存放在另一块内存空间中,叫做“方法区” 这块区域存放了Dog类的信息,其中就包括成员方法。方法区中的成员方法会和堆内存中的成员变量关联对应起来吗?当然会,JVM会帮助我们完成这个工作。JVM会按照一定机制将这块方法区中的方法与堆内存区中的成员变量相互关联起来,当执行dog1.name = “旺财”这条语句的时候,会将字符串“旺财”送到dog1的”堆内存“区的成员变量name中,当执行dog1.Introduce()这条语句的时候,会调用dog1的方法区中introduce方法。注意:下面这几条语句都是错误的语句,大家想一想为社么错误。
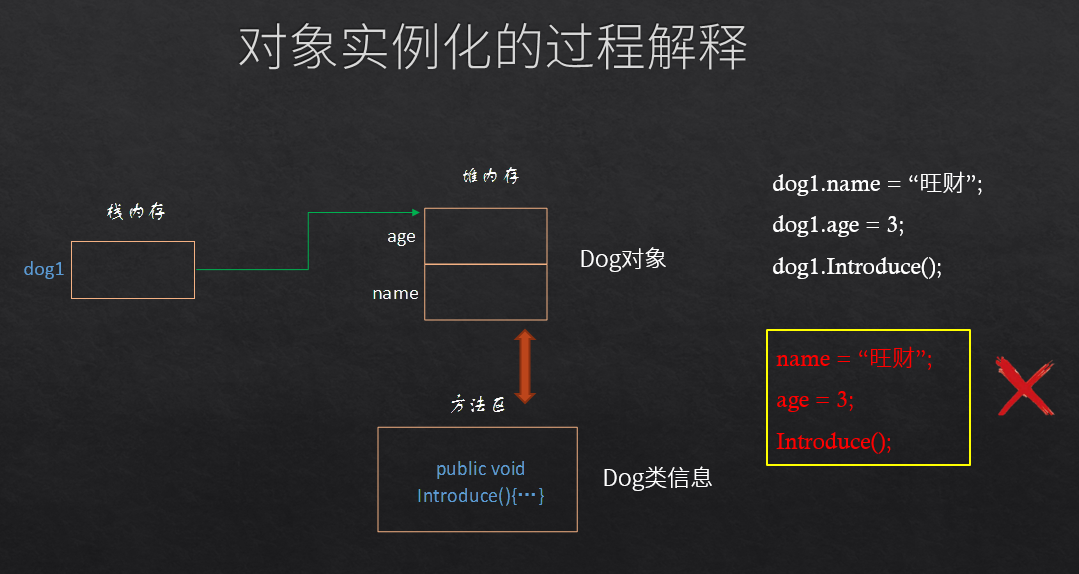
这就是单个对象的实例化过程。这种用图形的方式描述对象的内存结构,对理解类和对象的一些重要概念有很大帮助,希望大家能够理解并掌握这种画图方法,以后如果遇到难以理解的问题,可以按这个方法自己画一画,往往很容易就能帮助我们理清思路。
现在再看看新增dog2对象的内存结构。
dog1对象表示的是堆内存中创建出来的一个Dog对象,成员变量在堆内存,方法在方法区。现在看看新增一个dog2对象时发生了什么。与刚才的分析一样,栈内存会有一个对象名称dog2,代表的是在堆内存中创建的另一个Dog对象,成员变量放在堆内存中,这块成员变量区域与上面dog1的内存区域是两个不同的区域,dog2的成员变量与dog1的成员变量之间相互独立,互不影响。这就叫做每个对象都拥有一份成员变量的拷贝。
然而,dog2的方法区却和dog1的方法区是共用的。也就是说,introduce方法只有一份,dog1.introduce()语句所调用的代码和dog2.introduce()语句所调用的代码是同一份代码,但是为什么输出结果不一样呢?原因是在程序运行过程中,JVM可以根据是由哪个对象发起对introduce方法的调用,方法中所用到的成员变量数据就使用哪个对象的数据,这样,对象dog1调用introduce(),方法里的name和age用的是dog1的name和p的age,而dog2调用introduce时,方法里的name和age用的就是dog2对象的name和age。
搞清楚上述概念后,剩余的代码请读者自己完成。