@(134 - Linux)
Part 1 交叉编译简介
1.1 What is cross-compiling?
对于没有做过嵌入式编程的人,可能不太理解交叉编译的概念,那么什么是交叉编译?它有什么作用?
在解释什么是交叉编译之前,先要明白什么是本地编译。
本地编译
本地编译可以理解为,在当前编译平台下,编译出来的程序只能放到当前平台下运行。平时我们常见的软件开发,都是属于本地编译:
比如,我们在 x86 平台上,编写程序并编译成可执行程序。这种方式下,我们使用 x86 平台上的工具,开发针对 x86 平台本身的可执行程序,这个编译过程称为本地编译。
交叉编译
交叉编译可以理解为,在当前编译平台下,编译出来的程序能运行在体系结构不同的另一种目标平台上,但是编译平台本身却不能运行该程序:
比如,我们在 x86 平台上,编写程序并编译成能运行在 ARM 平台的程序,编译得到的程序在 x86 平台上是不能运行的,必须放到 ARM 平台上才能运行。
(Host 生成的程序不能在Host 平台上运行而只能放到Target平台运行)
1.2 为什么会有交叉编译
之所以要有交叉编译,主要原因是:
- Speed: 目标平台的运行速度往往比主机慢得多,许多专用的嵌入式硬件被设计为低成本和低功耗,没有太高的性能
- Capability: 整个编译过程是非常消耗资源的,嵌入式系统往往没有足够的内存或磁盘空间
- Availability: 即使目标平台资源很充足,可以本地编译,但是第一个在目标平台上运行的本地编译器总需要通过交叉编译获得
- Flexibility: 一个完整的Linux编译环境需要很多支持包,交叉编译使我们不需要花时间将各种支持包移植到目标板上
1.3 为什么交叉编译比较困难
交叉编译的困难点在于两个方面:
1)不同的体系架构拥有不同的机器特性
- Word size: 是64位还是32位系统
- Endianness: 是大端还是小端系统
- Alignment: 是否必修按照4字节对齐方式进行访问
- Default signedness: 默认数据类型是有符号还是无符号
- NOMMU: 是否支持MMU
2)交叉编译时的主机环境与目标环境不同
- Configuration issues
- HOSTCC vs TARGETCC
- Toolchain Leaks
- Libraries
- Testing
详细的对比可以参看这篇文章,已经写的很详细了,在这就不细说了:Introduction to cross-compiling for Linux
第 2 章 交叉编译链
明白了什么是交叉编译,那我们来看看什么是交叉编译链。
注意:严格意义上来说,交叉编译器,只是指交叉编译的gcc,但是实际上为了方便,我们常说的交叉编译器就是交叉工具链。本文对这两个概念不加以区分,都是指编译链
首先编译过程是按照不同的子功能,依照先后顺序组成的一个复杂的流程,如下图:
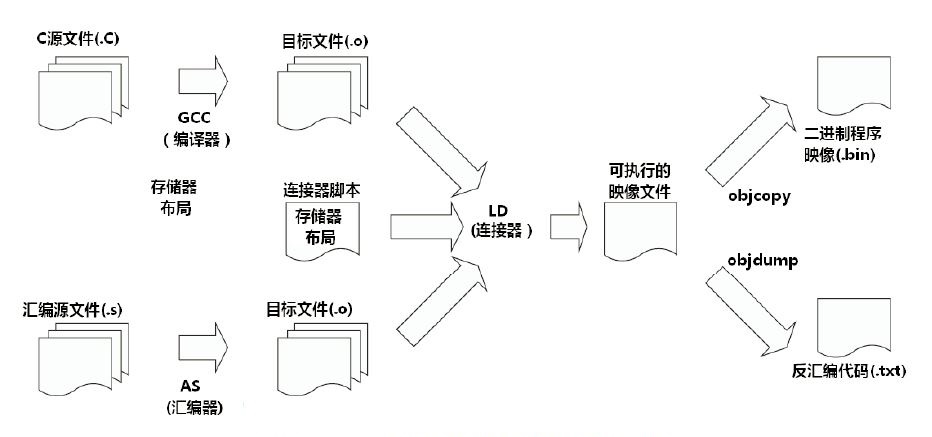
编译流程
那么编译过程包括了预处理、编译、汇编、链接等功能。既然有不同的子功能,那每个子功能都是一个单独的工具来实现,它们合在一起形成了一个完整的工具集。
同时编译过程又是一个有先后顺序的流程,它必然牵涉到工具的使用顺序,每个工具按照先后关系串联在一起,这就形成了一个链式结构。
因此,交叉编译链就是为了编译跨平台体系结构的程序代码而形成的由多个子工具构成的一套完整的工具集。同时,它隐藏了预处理、编译、汇编、链接等细节,当我们指定了源文件(.c)时,它会自动按照编译流程调用不同的子工具,自动生成最终的二进制程序映像(.bin)。
参考链接:https://blog.csdn.net/pengfei240/article/details/52912833