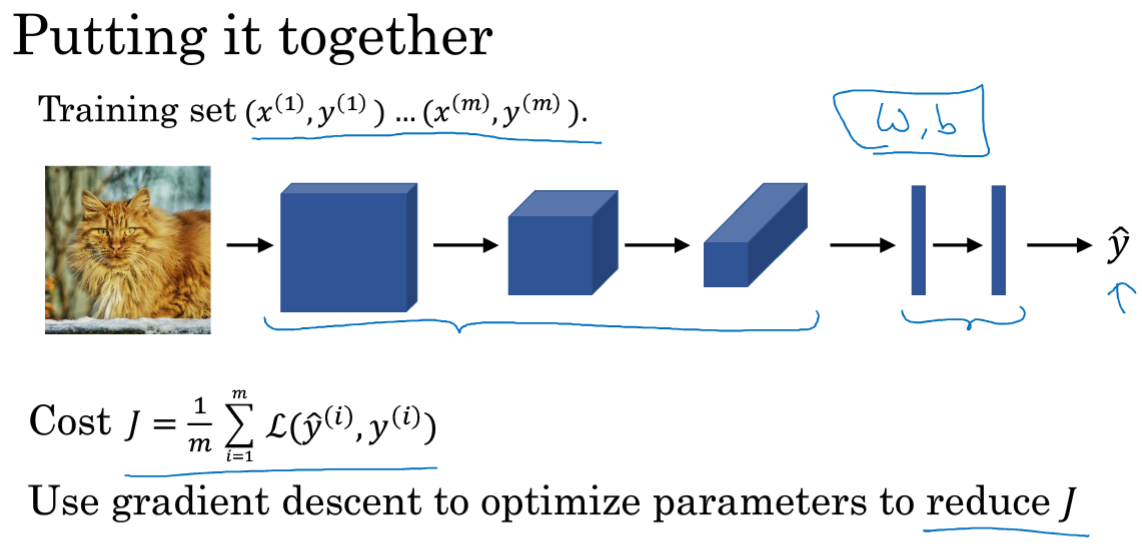
1.边缘检测示例
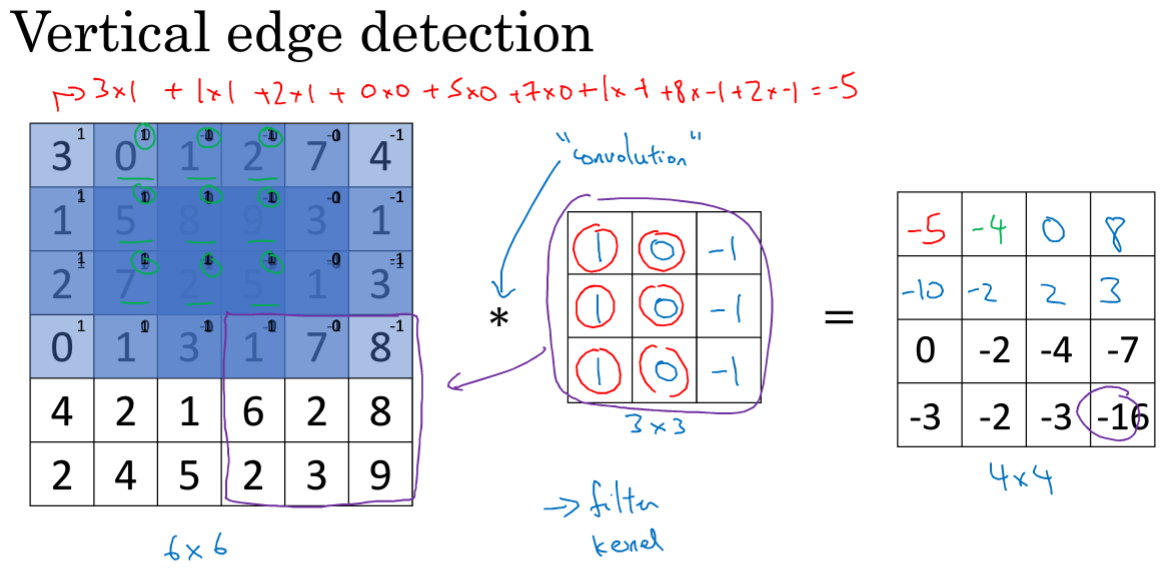
*表示卷积操作,标准表示。使用3*3的过滤器对其进行卷积,将3*3的覆盖在左侧上,并将运算结果相加;第二步将窗口向右移动一个单位,进行计算...横向之后再将窗格下移一个,进行循环..
那么为什么能检测出呢?
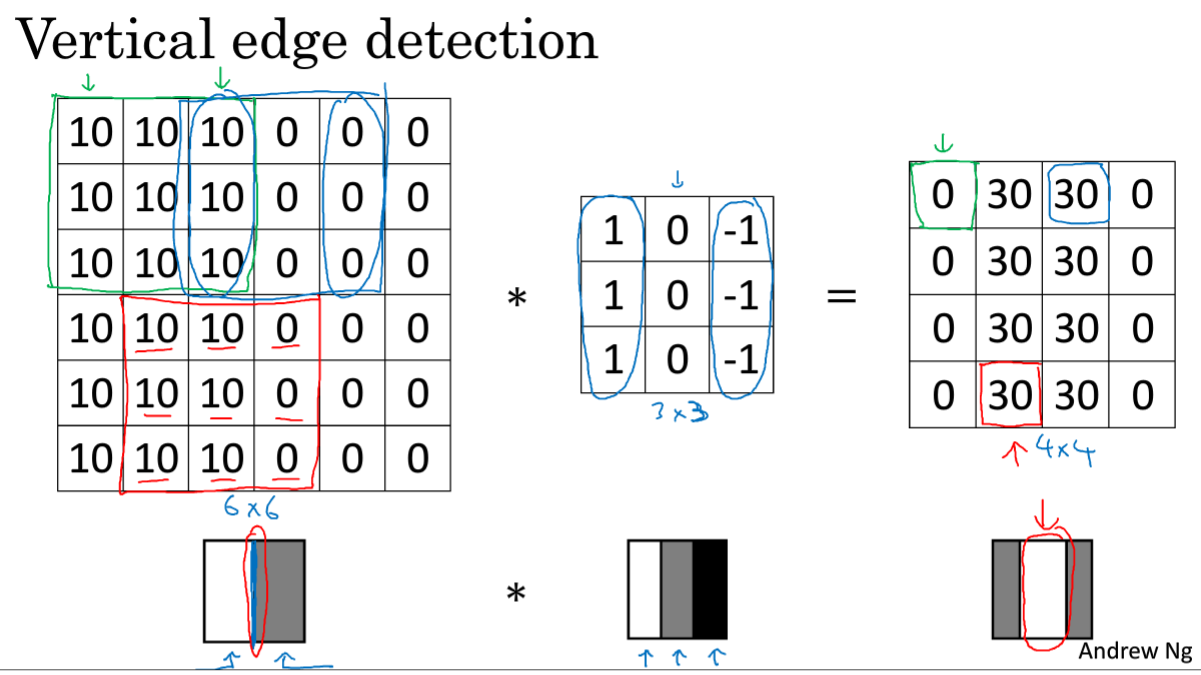
对于左边的6*6的图像,要检测出中间的垂直部分。进行卷积运算之后,得到右边的结果,可以检测出其中的结果。
但是较粗,原因是6*6是比较小的。如果是1000*1000的话,效果会更好。
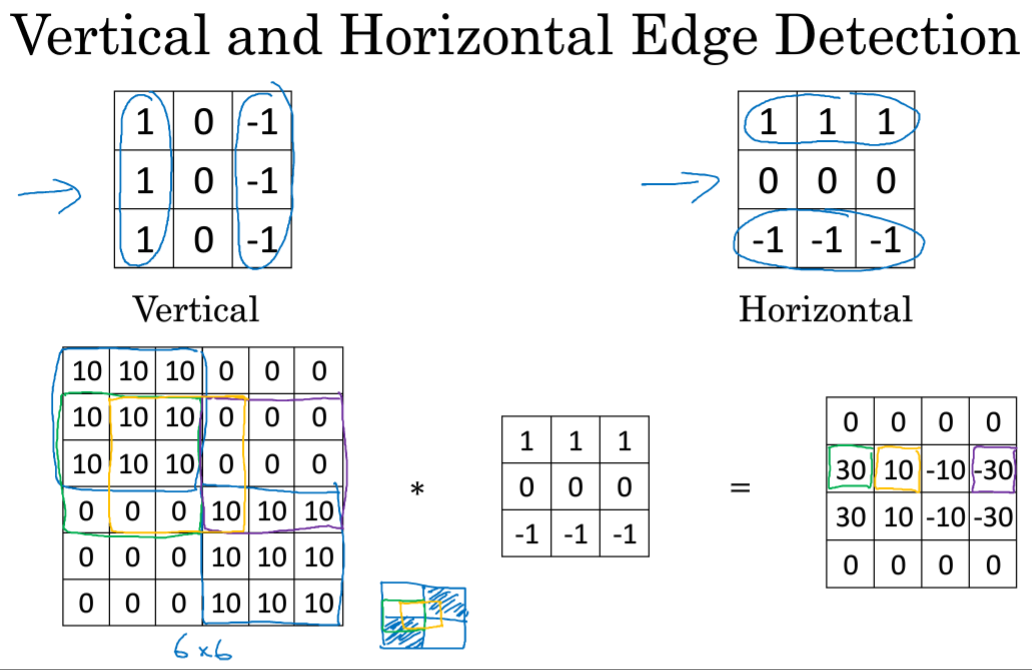
更多边缘检测:
同样可以进行水平检测 ,只不过卷积矩阵右旋90度。
Sobel滤波器,优点在于中间一行元素的权重,即中间的权重,可以使结果的鲁棒性更高;还有sharr滤波器。
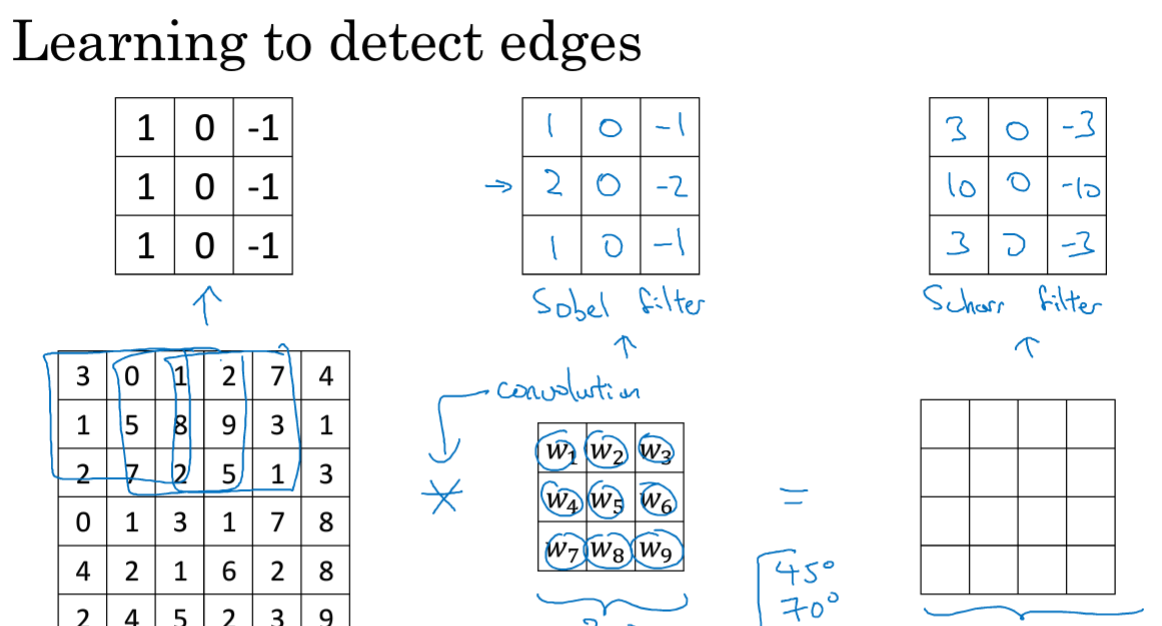
也可以将权重设置为参数,通过BP去进行学习,也可以检测到不止水平或垂直角度,比如45°、70°等。
2.Padding
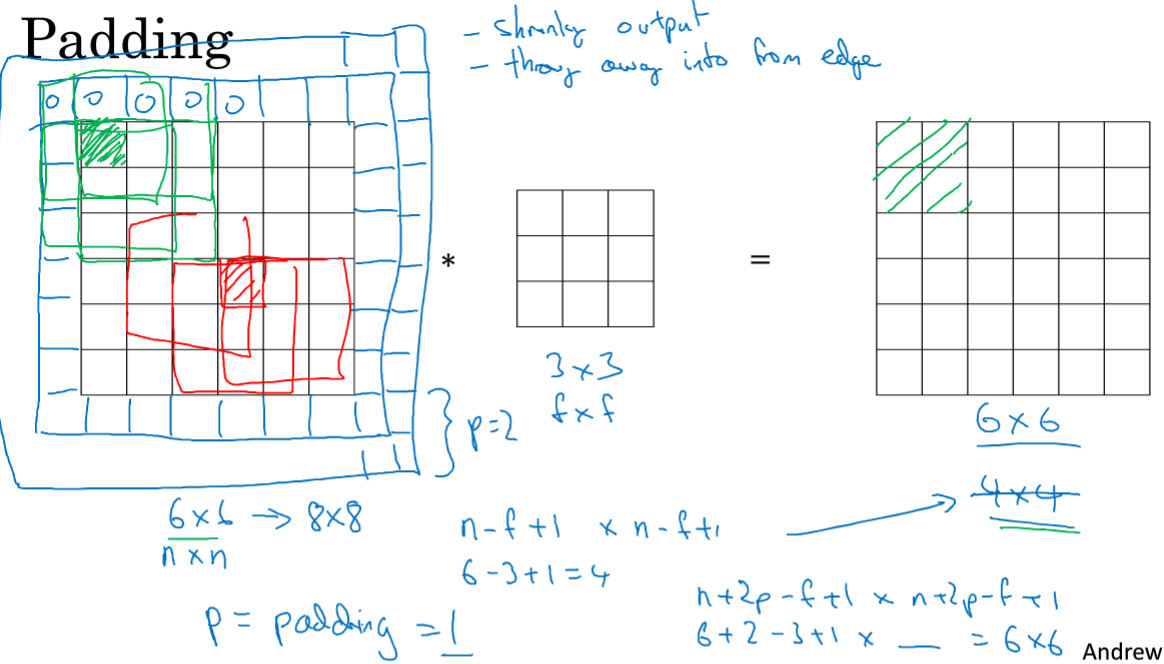
从上图的卷积中,6*6与3*3,结果是4*4,所以一般的结果是:(n-f+1)*(n-f+1),n是原矩阵大小,f是卷积矩阵;
但是这样每次做卷积,图像就会被压缩,可能会缩到只有1*1的大小;另一个缺点是,对于位于边缘的特征,包括的次数很少,位于中间的,次数多,意味着丢掉了图像边缘的很多信息。
解决办法是,在进行卷积操作之前,可以进行pad,上图中p=padding=1,上下分被补上1,p也可以等于2...等等。

有两种卷积,valid中意味着不填充,Same意味着填充并且输出不变,其中p=(f-1)/2,所以f通常是奇数,是CV的惯例。
3.卷积步长
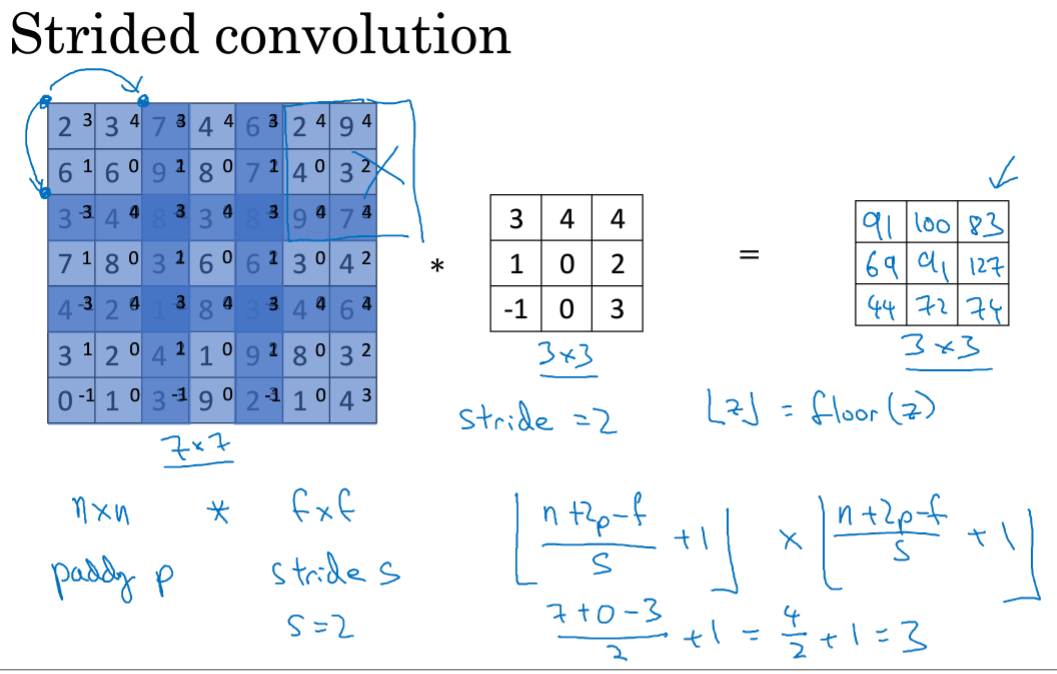
如果有框内元素到了外面,就不进行卷积,这是CV传统。所以要向下取整。

这是总结,包括图像原大小n,卷积f,padding的p,步幅s,最终输出的公式,有向下取整。
4.卷积为何有效?
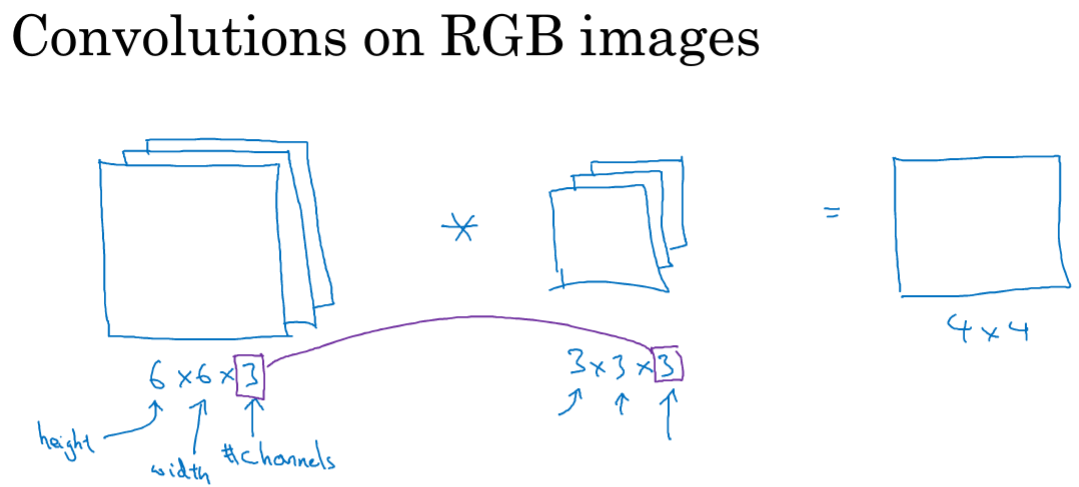
对于有RGB三种的图像来说,进行卷积操作后,会得到4*4的结果,且其中的图像层数和卷积层数必须一致。

对于矩阵第一层R如果设置为检测垂直,另两个为0,则是针对红色层进行垂直边缘检测;如果关心在哪个颜色通道进行检测,则设置成下边的即可。
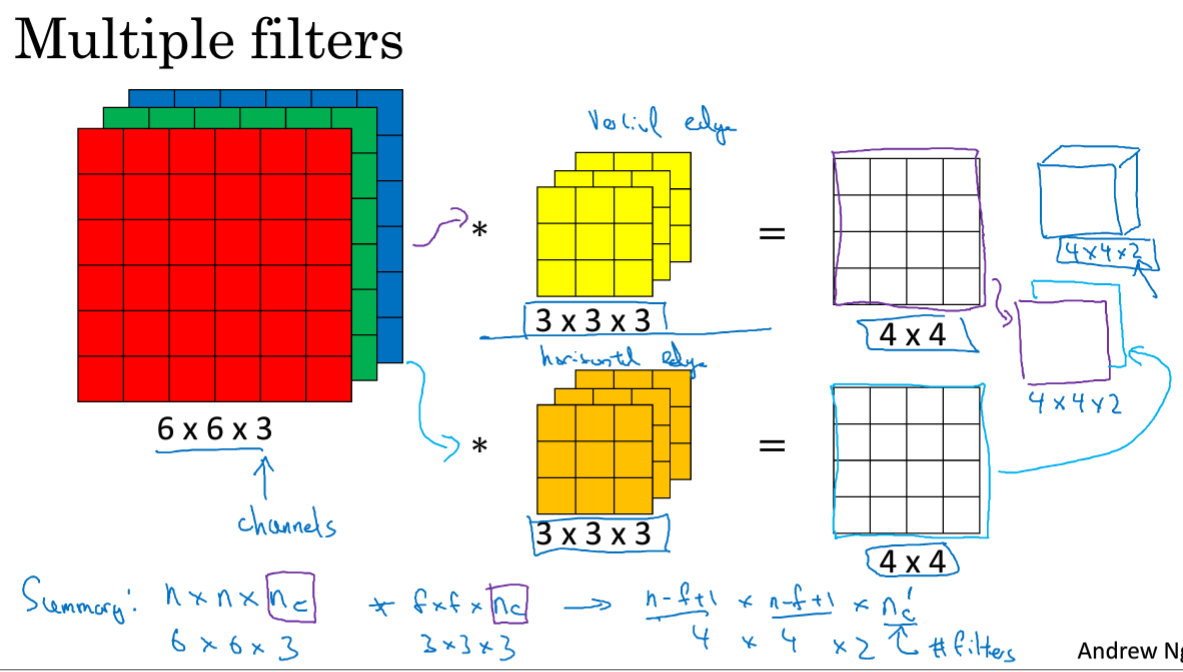
总结:nc在两个中相等的,最终结果中的nc'是使用的过滤器的个数,在本例中就是两个,上边的进行垂直边缘检测,下边的进行水平边缘检测。
最终将两个4×4的矩阵堆叠起来,得到最终的结果,4*4*2.
5.单层卷积网络
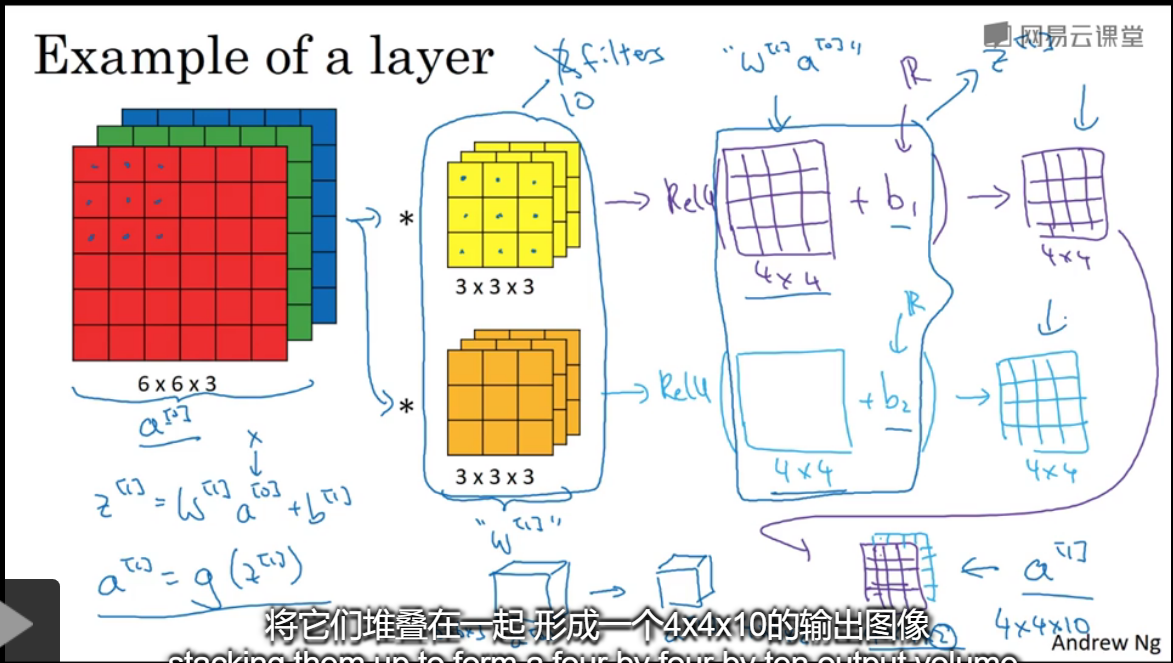
1.本例中由6*6*3,输出为4*4*2,因为滤波层是用了2个滤波器,即选择两个特征映射,如果是10个滤波器,那么最终结果为4*4*10。
2.卷积过程为相乘+偏置,使用ReLu进行非线性映射,最终得到a[1]输出就是4*4*2的结果。a[0]是输入,w[1]是第一层卷积层。

如果有10个3*3*3的滤波,那么这层神经网络有几个参数?
每一个滤波有 27个+偏置,偏置是实数,广播到矩阵中相加,共有280个。这个网络可以运用到大图上,而不增加参数个数,这是CNN的避免过拟合办法。
下面总结一下CNN的标记:

对于输入:包括图片高度宽度和通道数(RGB、灰度等),n[l]c是过滤器的通道数(是针对一个过滤器来说的),通道数肯定是要和上一层的输出通道数保持一致的。
//但是我感觉这里each filter is:f[l]*f[l]*n[l-1]c其实是不对的吧?
对于输入和输出,其中的高度和宽度是有计算关系的,另有激活、权重、偏置等。
对于A[l]的m是共有m个样本。
//感觉做CV确实是运算量大,矩阵都比较高维,不得不用GPU的。。。
6.简单卷积NN示例

现在假设来检测一张图中是否有一只猫,高度宽度=39,通道数=3;设置了每层卷积的参数,最终得到了7*7*40的结果,是为图片提取的特征数=1960,;
进行展开,最终使用logistic或softmax进行预测是否有猫。
在CNN中,设定这么多参数是比较麻烦的,高度和宽度会随着网络深度加深而逐渐减小,而通道数量在增加3->10->20->40,

在卷积网络中的三种层:卷积、池化、全连接层。后两者更容易设计。
7.池化层
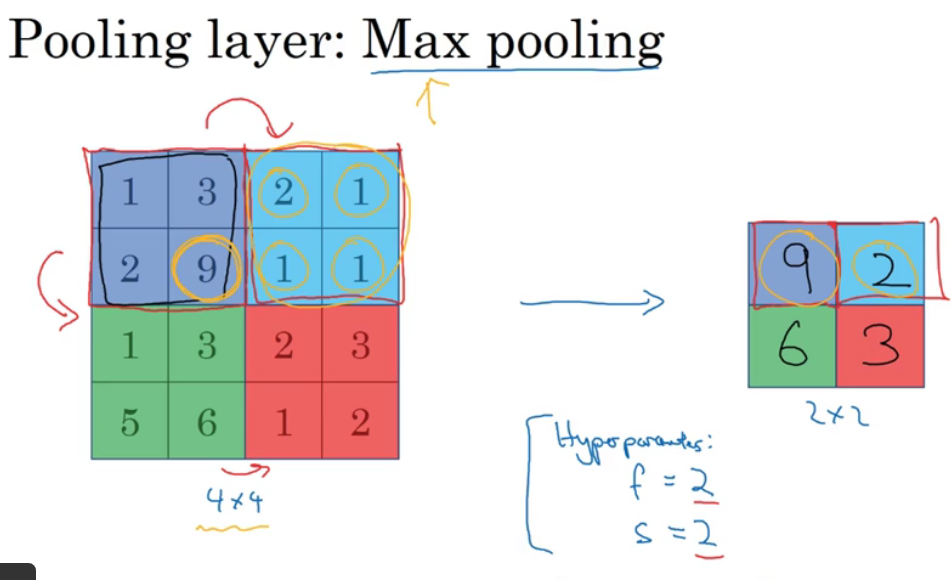
使用池化层,来缩减模型大小,提高计算速度,提高所取特征的鲁棒性。
上例中使用池化层,若最终输出是2*2,那么很简单,对应颜色区域取最值即可。
池化的最大操作功能是主要在任何一个象限内提取到某个特征,它都会保留在最大池化的输出里,如果在过滤器中提取到某个特征,那么保留其最大值;如果没有提取到这个特征,那么即使最大值也是很小的。(例如在图片中检测猫眼),这是最大池化的直观理解。
更有趣的是,池化有一组超参,但是却不需要学习!一旦确定了f和s,它就是一个固定运算。

上例中,池化层为3*3,即f=3;之前在CNN中的参数仍然适用于当前;如果输入有nc个信道,那么对每个信道都单独进行最大池化操作,输出结果是3*3*nc。

上图是另一种平均池化,不太常用。每个取得是平均值。
一种用法是在很深的神经网络中,使用平均池化来分解规模为7*7*1000的网络的表示层,

池化的参数包括:过滤器大小和步幅s,f=2,s=2应用最广泛,相当于高度宽度缩减一半。
最大池化中很少用到padding。
输入是nH*nW*nc,输出信道和输入一样,因为对每一个信道都进行池化。
没有要学习的参数!可能是手动设置,或者通过交叉验证设置,最大池化是计算NN某一层的静态属性。
8.卷积神经网络示例

通常将一层lay=一层卷积+一层池化,作为一层,通常统计具有权重和参数的层(池化层没有权重和参数,只有一些超参数)。
假设要识别的图象是32*32*3,具有RGB的。
将特征展开为400维的向量,并且有一个全连接层,下一层为120;再连接一个全连接层,假设为84个单元,最后连接一个softmax层,10个单元。
那么如何选取这么多参数呢?对于超参数,不要自己选定,而要看其他文献中是如何取的。选一个在别人任务中很好的框架,那也可能适用于自己的程序。
随着网络深度的增加,宽度和高度都会减小,而信道通道数会增加。
典型的CNN是一个或多个con层之后跟一个池化层,然后是几个全连接层,最后一个softmax。
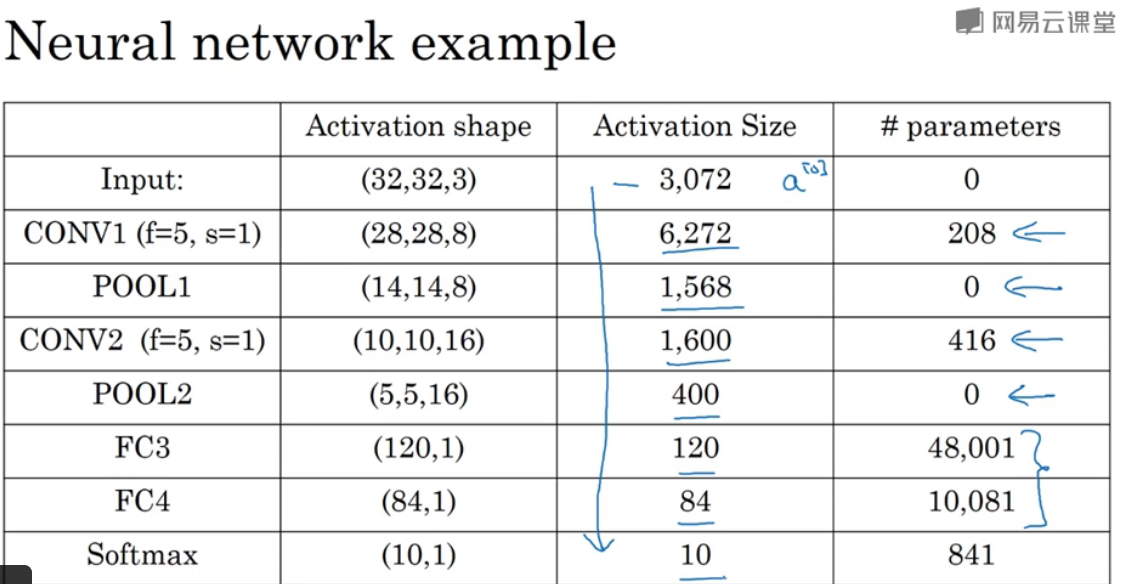
CNN的参数,输入层和池化层参数都为0,激活size是激活层相乘;可以发现大多数的参数是在全连接层(Fully connected),卷积层的参数较少的。
9.为什么使用卷积
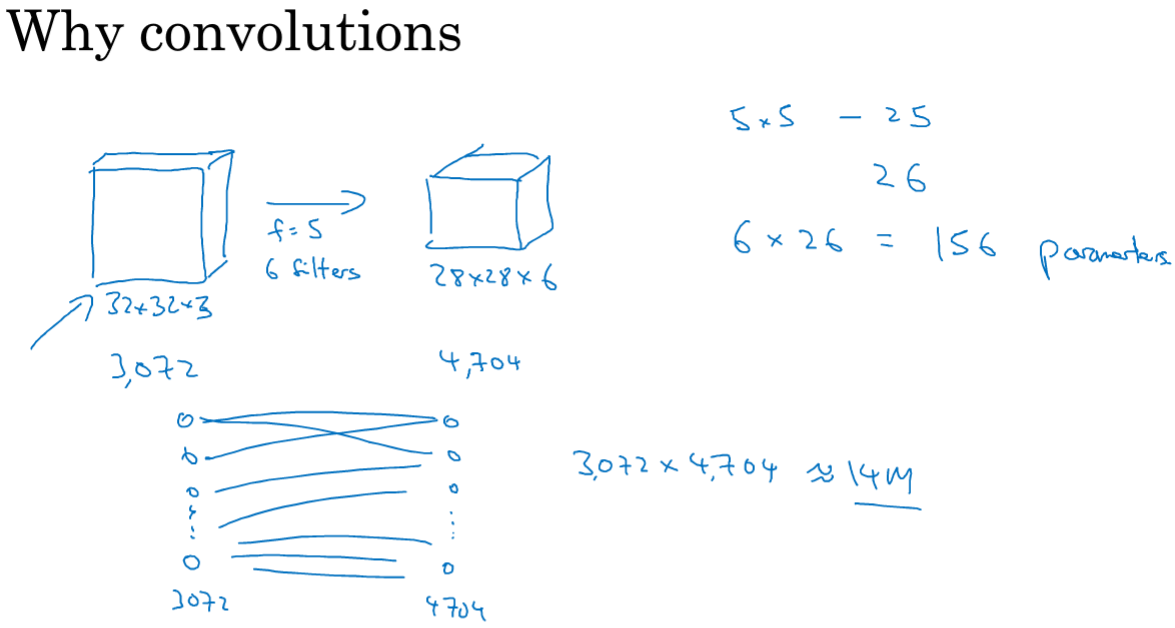
和全连接网络相比,卷积拥有两个优点:参数共享和稀疏连接。
对于这样地一个网络,如果是全连接,输入特征是3072个,第二层为4704个,那么需要的参数量是1400万;但是看卷积层的参数数量是共156个参数。
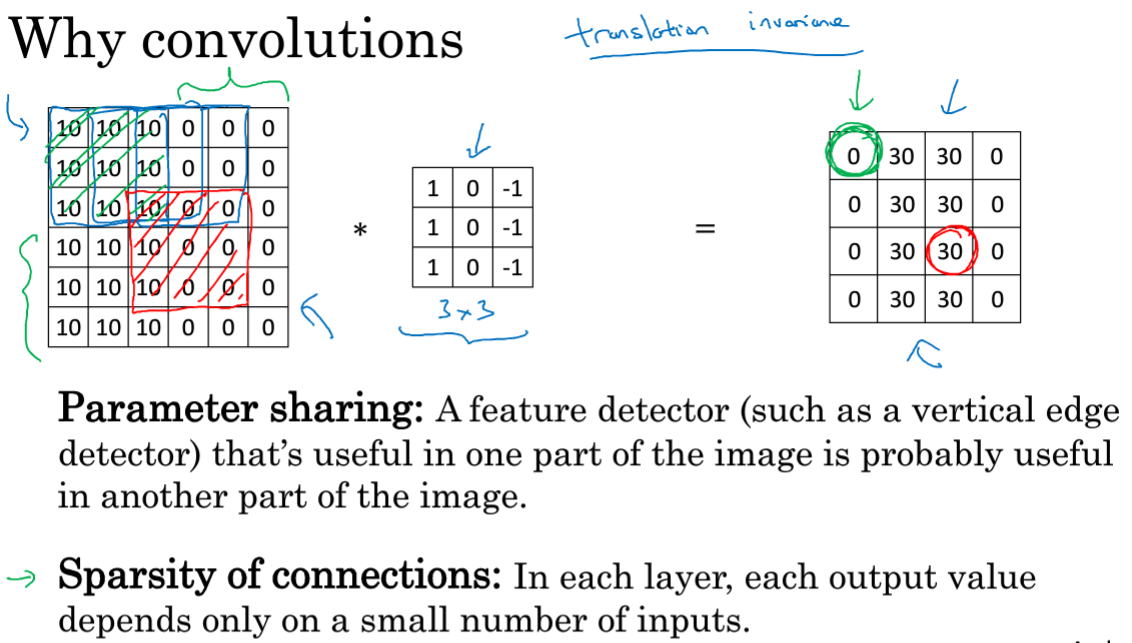
比如对于垂直检测,如果适用于图片中的一部分,那么图片中旁边的区域也可以进行垂直检测,可以在图片不同区域中使用同样的参数进行提取特征;
稀疏连接:最终右边的0行0列的0只与输入的36个特征中的9个相连接,神经网络可以通过这种机制减少参数,以便使用更小的训练集来训练它。
CNN具有平移不变性,一只猫向右移动两个像素,仍是清晰的一只猫,因为即使移动图片也依然具有非常相似的特征。