一、XML&DOM编程
1. 开发工具
文本编辑器:notepad++、EditPlus、UltraEdit
2. 重置视图:window----Reset perspective
3. 首选项:Preferences
4. Junit测试框架
5. XML:可扩展标记语言,W3C发布,数据存储格式。
标签:开始标签、嵌套标签、结束标签
应用:传输数据、配置文件
XML校验:浏览器校验
(1)XML语法
文档声明:包含版本号、编码表、独立属性
<?xml version="1.0" encoding=“UTF-8” standalone=“yes”?>
元素:一个XML标签就是一个元素,在开始标签和结束之间可以包含标签体。
自闭标签<a/>
属性:一个标签可以有多个属性,每个属性都有它自己的名称和取值
<china capital="beijing"/>
注释:Xml文件中的注释采用:“<!--注释-->” 格式。
注释不能出现在文档声明之前(因为XML要求文档声明必须在第一行,之前不能有其他内容)
注释不能嵌套
CDATA区/转义字符:<![CDATA[ 内容 ]]>
处理指令:处理指令用来指挥解析引擎如何解析XML文档内容。
<?xml-stylesheet type="text/css" href="1.css"?>
(2)xml约束:在xml技术里,可以编写一个文档来约束一个xml文档的写法,这称之为XML约束。
xml约束技术:XML DTD 、XML Schem
6. XML编程:利用java程序去增删改查(crud)XML中的数据,DOM解析、sax解析(只可查)
(1)sax解析
//1.获取解析器工厂
SAXParserFactory factory = SAXParserFactory.newInstance();
//2.通过工厂获取sax解析器
SAXParser parser = factory.newSAXParser();
//3.获取读取器
XMLReader reader = parser.getXMLReader();
//4.注册事件处理器
reader.setContentHandler(ContentHandler);
//5.解析XML
reader.parse("book.xml");
(2)dom4j解析
//1.获取解析器
SAXReader reader = new SAXReader();
//2.解析XML获取代表整个文档的DOM对象
Document dom = reader.read("book.xml");
//3.获取根节点
Element root = dom.getRootElement();
String bookName = root.element("书").element("书名").getText();
二、Web开发
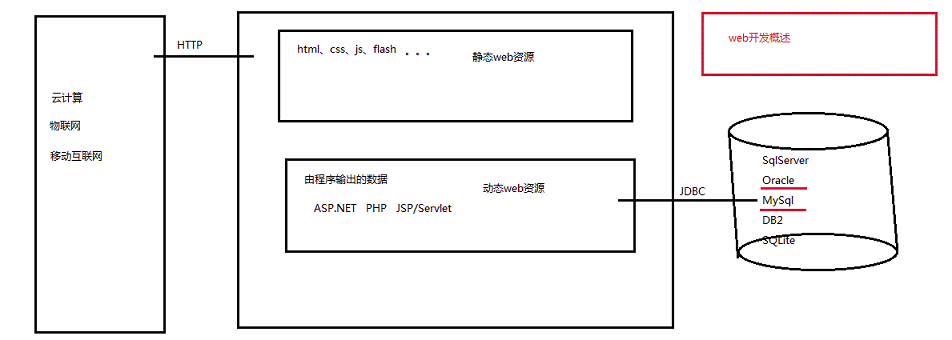
1. WEB,在英语中web即表示网页的意思,它用于表示Internet主机上供外界访问的资源。
2. Internet上供外界访问的Web资源分为:
(1)静态web资源(如html 页面):指web页面中供人们浏览的数据始终是不变。
静态web资源开发技术:Html、CSS、javaScript
(2)动态web资源:指web页面中供人们浏览的数据是由程序产生的,不同时间点访问web页面看到的内容各不相同。
常用动态web资源开发技术:JSP/Servlet、ASP、PHP等
3. 常用数据库:SqlServer、Oracle、MySQL、DB2、SQLite;操作数据库:JDBC
4. C/S和B/S之争
Client/Server:QQ、魔兽世界 优点:客户端可以任意设计,可以实现非常绚丽的效果和特殊的功能,只需下载一次客户端,以后只依赖网络传输变化的数据,对网络的依赖没有bs那么强
缺点:第一次使用时需要下载客户端,当需要更新时,所有的客户端都需要更新,有的情况下只是不可接受的
Browser/Server:WebQQ、网页游戏 优点:不需要下载客户端,只需服务器更新即可;缺点:浏览器展示能力有限;所有的资源都要从服务器获取,对网速的要求非常高。